 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqual Confusion Fairness: Measuring Group-Based Disparities in Automated Decision Systems
Jul 02, 2023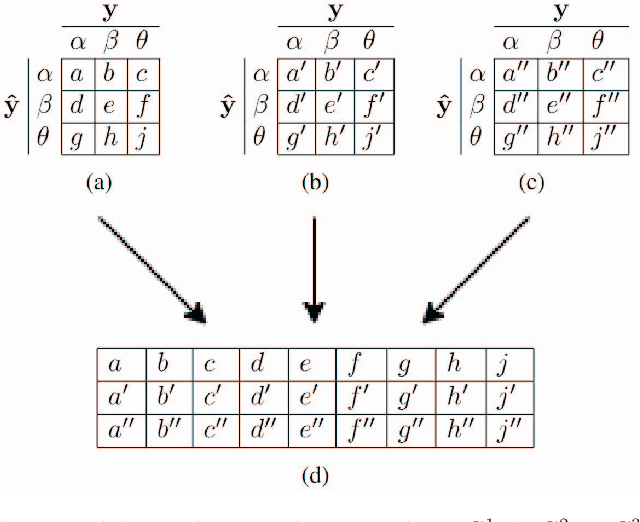
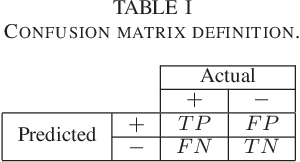
As artificial intelligence plays an increasingly substantial role in decisions affecting humans and society, the accountability of automated decision systems has been receiving increasing attention from researchers and practitioners. Fairness, which is concerned with eliminating unjust treatment and discrimination against individuals or sensitive groups, is a critical aspect of accountability. Yet, for evaluating fairness, there is a plethora of fairness metrics in the literature that employ different perspectives and assumptions that are often incompatible. This work focuses on group fairness. Most group fairness metrics desire a parity between selected statistics computed from confusion matrices belonging to different sensitive groups. Generalizing this intuition, this paper proposes a new equal confusion fairness test to check an automated decision system for fairness and a new confusion parity error to quantify the extent of any unfairness. To further analyze the source of potential unfairness, an appropriate post hoc analysis methodology is also presented. The usefulness of the test, metric, and post hoc analysis is demonstrated via a case study on the controversial case of COMPAS, an automated decision system employed in the US to assist judges with assessing recidivism risks. Overall, the methods and metrics provided here may assess automated decision systems' fairness as part of a more extensive accountability assessment, such as those based on the system accountability benchmark.
Accuracy, Fairness, and Interpretability of Machine Learning Criminal Recidivism Models
Sep 14, 2022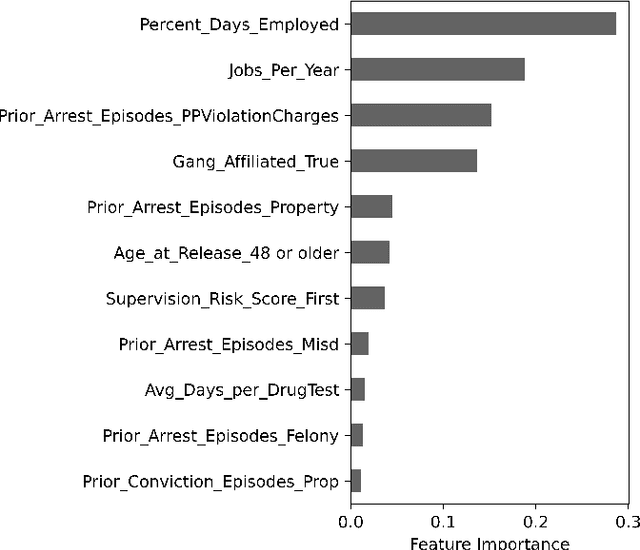
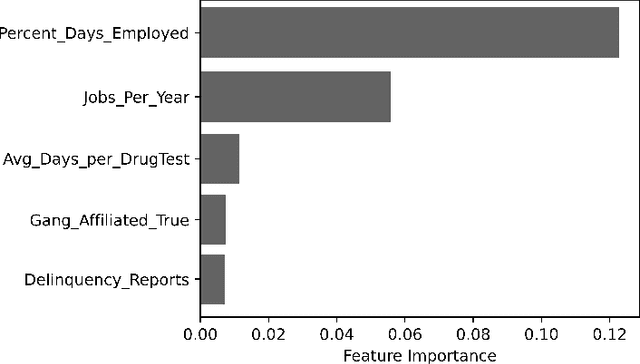
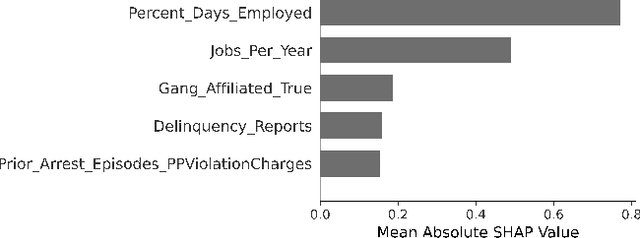
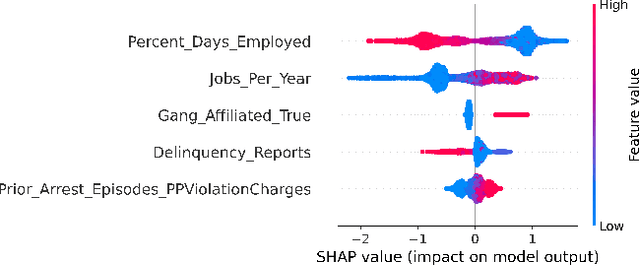
Criminal recidivism models are tools that have gained widespread adoption by parole boards across the United States to assist with parole decisions. These models take in large amounts of data about an individual and then predict whether an individual would commit a crime if released on parole. Although such models are not the only or primary factor in making the final parole decision, questions have been raised about their accuracy, fairness, and interpretability. In this paper, various machine learning-based criminal recidivism models are created based on a real-world parole decision dataset from the state of Georgia in the United States. The recidivism models are comparatively evaluated for their accuracy, fairness, and interpretability. It is found that there are noted differences and trade-offs between accuracy, fairness, and being inherently interpretable. Therefore, choosing the best model depends on the desired balance between accuracy, fairness, and interpretability, as no model is perfect or consistently the best across different criteria.
Error Parity Fairness: Testing for Group Fairness in Regression Tasks
Aug 16, 2022
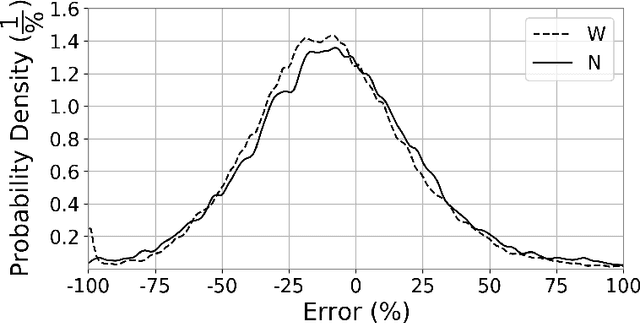
The applications of Artificial Intelligence (AI) surround decisions on increasingly many aspects of human lives. Society responds by imposing legal and social expectations for the accountability of such automated decision systems (ADSs). Fairness, a fundamental constituent of AI accountability, is concerned with just treatment of individuals and sensitive groups (e.g., based on sex, race). While many studies focus on fair learning and fairness testing for the classification tasks, the literature is rather limited on how to examine fairness in regression tasks. This work presents error parity as a regression fairness notion and introduces a testing methodology to assess group fairness based on a statistical hypothesis testing procedure. The error parity test checks whether prediction errors are distributed similarly across sensitive groups to determine if an ADS is fair. It is followed by a suitable permutation test to compare groups on several statistics to explore disparities and identify impacted groups. The usefulness and applicability of the proposed methodology are demonstrated via a case study on COVID-19 projections in the US at the county level, which revealed race-based differences in forecast errors. Overall, the proposed regression fairness testing methodology fills a gap in the fair machine learning literature and may serve as a part of larger accountability assessments and algorithm audits.
System Cards for AI-Based Decision-Making for Public Policy
Mar 01, 2022
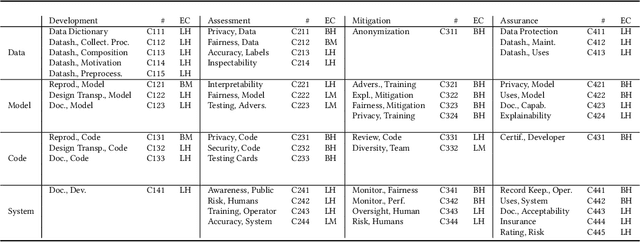
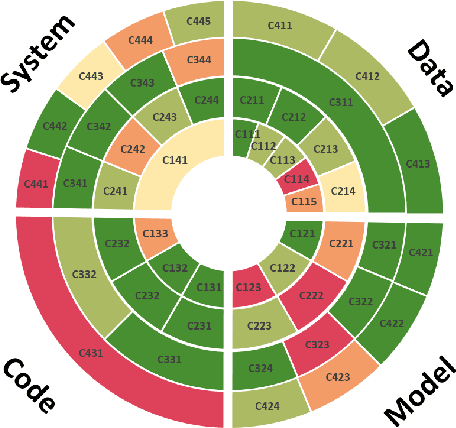
Decisions in public policy are increasingly being made or assisted by automated decision-making algorithms. Many of these algorithms process personal data for tasks such as predicting recidivism, assisting welfare decisions, identifying individuals using face recognition, and more. While potentially improving efficiency and effectiveness, such algorithms are not inherently free from issues such as bias, opaqueness, lack of explainability, maleficence, and the like. Given that the outcomes of these algorithms have significant impacts on individuals and society and are open to analysis and contestation after deployment, such issues must be accounted for before deployment. Formal audits are a way towards ensuring algorithms that are used in public policy meet the appropriate accountability standards. This work, based on an extensive analysis of the literature, proposes a unifying framework for system accountability benchmark for formal audits of artificial intelligence-based decision-aiding systems in public policy as well as system cards that serve as scorecards presenting the outcomes of such audits. The benchmark consists of 50 criteria organized within a four by four matrix consisting of the dimensions of (i) data, (ii) model, (iii) code, (iv) system and (a) development, (b) assessment, (c) mitigation, (d) assurance. Each criterion is described and discussed alongside a suggested measurement scale indicating whether the evaluations are to be performed by humans or computers and whether the evaluation outcomes are binary or on an ordinal scale. The proposed system accountability benchmark reflects the state-of-the-art developments for accountable systems, serves as a checklist for future algorithm audits, and paves the way for sequential work as future research.
Predicting Diffusion Reach Probabilities via Representation Learning on Social Networks
Jan 12, 2019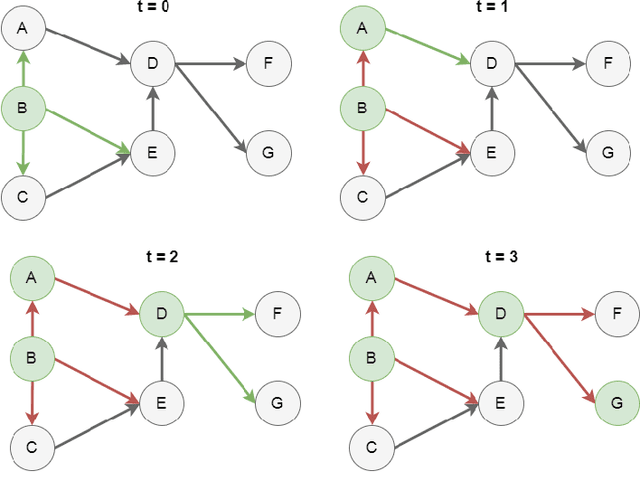
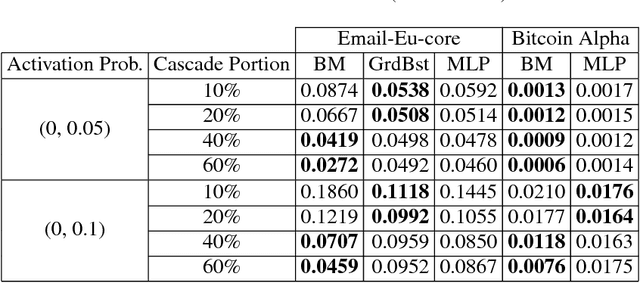

Diffusion reach probability between two nodes on a network is defined as the probability of a cascade originating from one node reaching to another node. An infinite number of cascades would enable calculation of true diffusion reach probabilities between any two nodes. However, there exists only a finite number of cascades and one usually has access only to a small portion of all available cascades. In this work, we addressed the problem of estimating diffusion reach probabilities given only a limited number of cascades and partial information about underlying network structure. Our proposed strategy employs node representation learning to generate and feed node embeddings into machine learning algorithms to create models that predict diffusion reach probabilities. We provide experimental analysis using synthetically generated cascades on two real-world social networks. Results show that proposed method is superior to using values calculated from available cascades when the portion of cascades is small.