 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-guided compact template learning for ensemble deep network-based pose-invariant face recognition
Paper and Code
Apr 15, 2019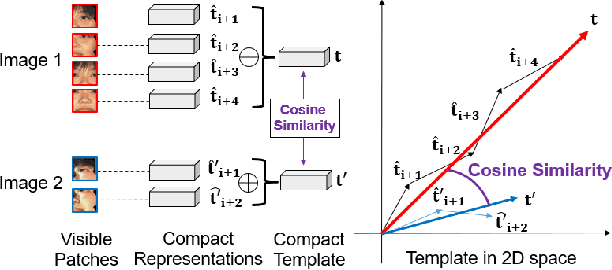

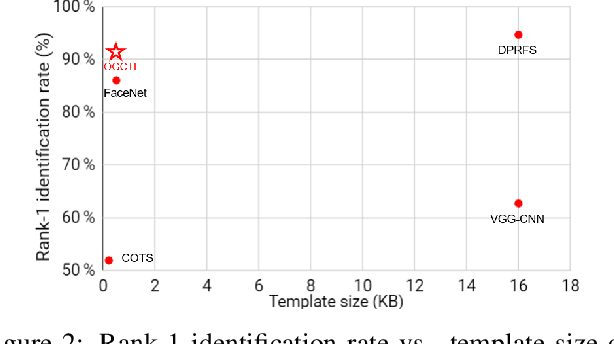
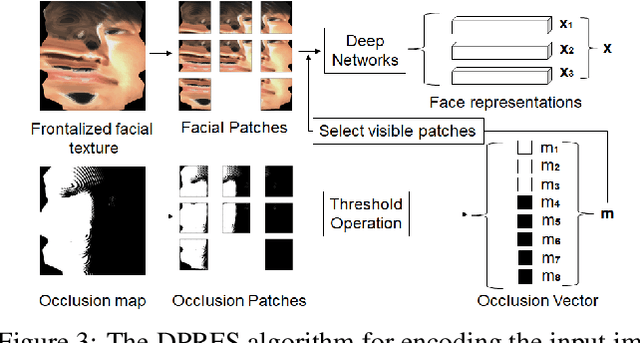
Concatenation of the deep network representations extracted from different facial patches helps to improve face recognition performance. However, the concatenated facial template increases in size and contains redundant information. Previous solutions aim to reduce the dimensionality of the facial template without considering the occlusion pattern of the facial patches. In this paper, we propose an occlusion-guided compact template learning (OGCTL) approach that only uses the information from visible patches to construct the compact template. The compact face representation is not sensitive to the number of patches that are used to construct the facial template and is more suitable for incorporating the information from different view angles for image-set based face recognition. Instead of using occlusion masks in face matching (e.g., DPRFS [38]), the proposed method uses occlusion masks in template construction and achieves significantly better image-set based face verification performance on a challenging database with a template size that is an order-of-magnitude smaller than DPRFS.