 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOAL: Fine-grained Contrastive Learning for Cross-domain Aspect Sentiment Triplet Extraction
Nov 17, 2023



Aspect Sentiment Triplet Extraction (ASTE) has achieved promising results while relying on sufficient annotation data in a specific domain. However, it is infeasible to annotate data for each individual domain. We propose to explore ASTE in the cross-domain setting, which transfers knowledge from a resource-rich source domain to a resource-poor target domain, thereby alleviating the reliance on labeled data in the target domain. To effectively transfer the knowledge across domains and extract the sentiment triplets accurately, we propose a method named Fine-grained cOntrAstive Learning (FOAL) to reduce the domain discrepancy and preserve the discriminability of each category. Experiments on six transfer pairs show that FOAL achieves 6% performance gains and reduces the domain discrepancy significantly compared with strong baselines. Our code will be publicly available once accepted.
Measuring Your ASTE Models in The Wild: A Diversified Multi-domain Dataset For Aspect Sentiment Triplet Extraction
May 27, 2023

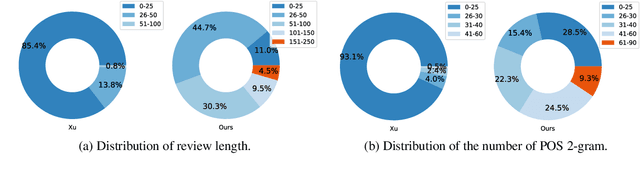

Aspect Sentiment Triplet Extraction (ASTE) is widely used in various applications. However, existing ASTE datasets are limited in their ability to represent real-world scenarios, hindering the advancement of research in this area. In this paper, we introduce a new dataset, named DMASTE, which is manually annotated to better fit real-world scenarios by providing more diverse and realistic reviews for the task. The dataset includes various lengths, diverse expressions, more aspect types, and more domains than existing datasets. We conduct extensive experiments on DMASTE in multiple settings to evaluate previous ASTE approaches. Empirical results demonstrate that DMASTE is a more challenging ASTE dataset. Further analyses of in-domain and cross-domain settings provide promising directions for future research. Our code and dataset are available at https://github.com/NJUNLP/DMASTE.
Enhancing Cross-lingual Transfer by Manifold Mixup
May 09, 2022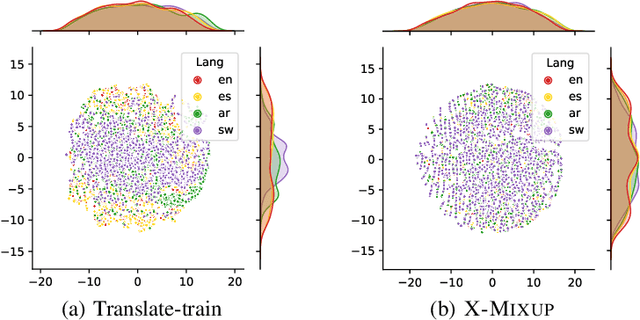
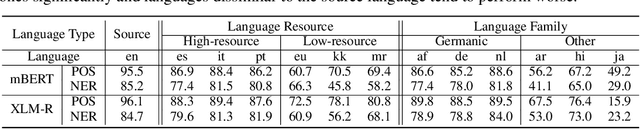


Based on large-scale pre-trained multilingual representations, recent cross-lingual transfer methods have achieved impressive transfer performances. However, the performance of target languages still lags far behind the source language. In this paper, our analyses indicate such a performance gap is strongly associated with the cross-lingual representation discrepancy. To achieve better cross-lingual transfer performance, we propose the cross-lingual manifold mixup (X-Mixup) method, which adaptively calibrates the representation discrepancy and gives a compromised representation for target languages. Experiments on the XTREME benchmark show X-Mixup achieves 1.8% performance gains on multiple text understanding tasks, compared with strong baselines, and significantly reduces the cross-lingual representation discrepancy.
Fine-grained Knowledge Fusion for Sequence Labeling Domain Adaptation
Sep 10, 2019
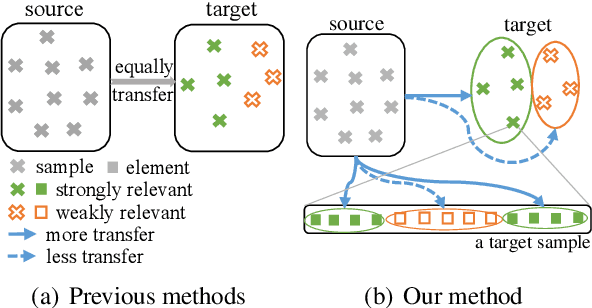


In sequence labeling, previous domain adaptation methods focus on the adaptation from the source domain to the entire target domain without considering the diversity of individual target domain samples, which may lead to negative transfer results for certain samples. Besides, an important characteristic of sequence labeling tasks is that different elements within a given sample may also have diverse domain relevance, which requires further consideration. To take the multi-level domain relevance discrepancy into account, in this paper, we propose a fine-grained knowledge fusion model with the domain relevance modeling scheme to control the balance between learning from the target domain data and learning from the source domain model. Experiments on three sequence labeling tasks show that our fine-grained knowledge fusion model outperforms strong baselines and other state-of-the-art sequence labeling domain adaptation methods.