 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-lingual Transfer by Manifold Mixup
May 09, 2022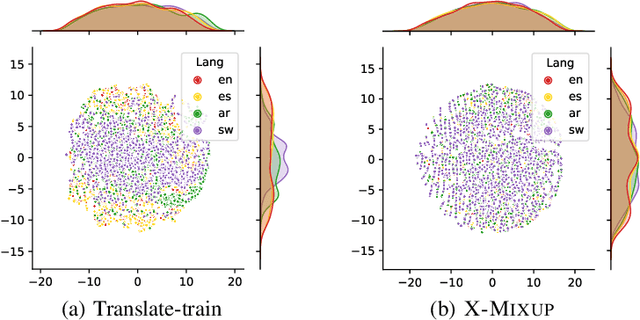


Based on large-scale pre-trained multilingual representations, recent cross-lingual transfer methods have achieved impressive transfer performances. However, the performance of target languages still lags far behind the source language. In this paper, our analyses indicate such a performance gap is strongly associated with the cross-lingual representation discrepancy. To achieve better cross-lingual transfer performance, we propose the cross-lingual manifold mixup (X-Mixup) method, which adaptively calibrates the representation discrepancy and gives a compromised representation for target languages. Experiments on the XTREME benchmark show X-Mixup achieves 1.8% performance gains on multiple text understanding tasks, compared with strong baselines, and significantly reduces the cross-lingual representation discrepancy.
Top-Rank Enhanced Listwise Optimization for Statistical Machine Translation
Jul 18, 2017
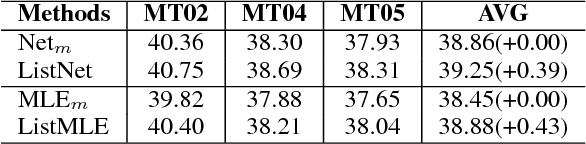

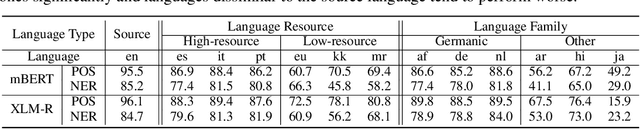
Pairwise ranking methods are the basis of many widely used discriminative training approaches for structure prediction problems in natural language processing(NLP). Decomposing the problem of ranking hypotheses into pairwise comparisons enables simple and efficient solutions. However, neglecting the global ordering of the hypothesis list may hinder learning. We propose a listwise learning framework for structure prediction problems such as machine translation. Our framework directly models the entire translation list's ordering to learn parameters which may better fit the given listwise samples. Furthermore, we propose top-rank enhanced loss functions, which are more sensitive to ranking errors at higher positions. Experiments on a large-scale Chinese-English translation task show that both our listwise learning framework and top-rank enhanced listwise losses lead to significant improvements in translation quality.
Improved Neural Machine Translation with a Syntax-Aware Encoder and Decoder
Jul 18, 2017

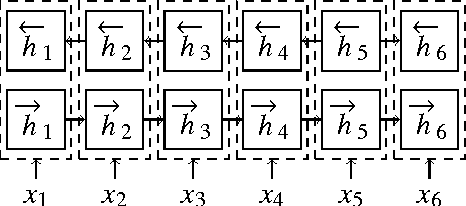

Most neural machine translation (NMT) models are based on the sequential encoder-decoder framework, which makes no use of syntactic information. In this paper, we improve this model by explicitly incorporating source-side syntactic trees. More specifically, we propose (1) a bidirectional tree encoder which learns both sequential and tree structured representations; (2) a tree-coverage model that lets the attention depend on the source-side syntax. Experiments on Chinese-English translation demonstrate that our proposed models outperform the sequential attentional model as well as a stronger baseline with a bottom-up tree encoder and word coverage.
Non-linear Learning for Statistical Machine Translation
Feb 28, 2015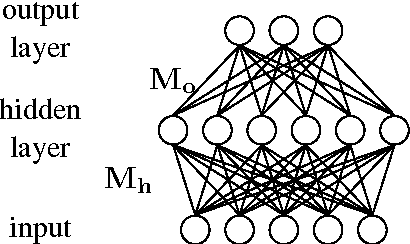
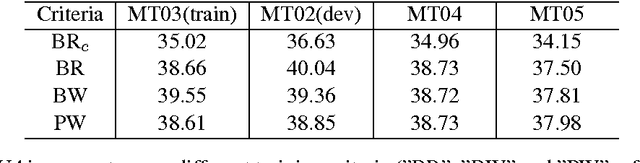
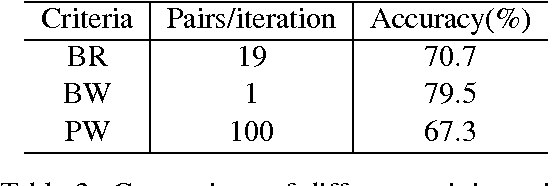
Modern statistical machine translation (SMT) systems usually use a linear combination of features to model the quality of each translation hypothesis. The linear combination assumes that all the features are in a linear relationship and constrains that each feature interacts with the rest features in an linear manner, which might limit the expressive power of the model and lead to a under-fit model on the current data. In this paper, we propose a non-linear modeling for the quality of translation hypotheses based on neural networks, which allows more complex interaction between features. A learning framework is presented for training the non-linear models. We also discuss possible heuristics in designing the network structure which may improve the non-linear learning performance. Experimental results show that with the basic features of a hierarchical phrase-based machine translation system, our method produce translations that are better than a linear model.