 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisRef: Visual Refocusing while Thinking Improves Test-Time Scaling in Multi-Modal Large Reasoning Models
Feb 27, 2026Advances in large reasoning models have shown strong performance on complex reasoning tasks by scaling test-time compute through extended reasoning. However, recent studies observe that in vision-dependent tasks, extended textual reasoning at inference time can degrade performance as models progressively lose attention to visual tokens and increasingly rely on textual priors alone. To address this, prior works use reinforcement learning (RL)-based fine-tuning to route visual tokens or employ refocusing mechanisms during reasoning. While effective, these methods are computationally expensive, requiring large-scale data generation and policy optimization. To leverage the benefits of test-time compute without additional RL fine-tuning, we propose VisRef, a visually grounded test-time scaling framework. Our key idea is to actively guide the reasoning process by re-injecting a coreset of visual tokens that are semantically relevant to the reasoning context while remaining diverse and globally representative of the image, enabling more grounded multi-modal reasoning. Experiments on three visual reasoning benchmarks with state-of-the-art multi-modal large reasoning models demonstrate that, under fixed test-time compute budgets, VisRef consistently outperforms existing test-time scaling approaches by up to 6.4%.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025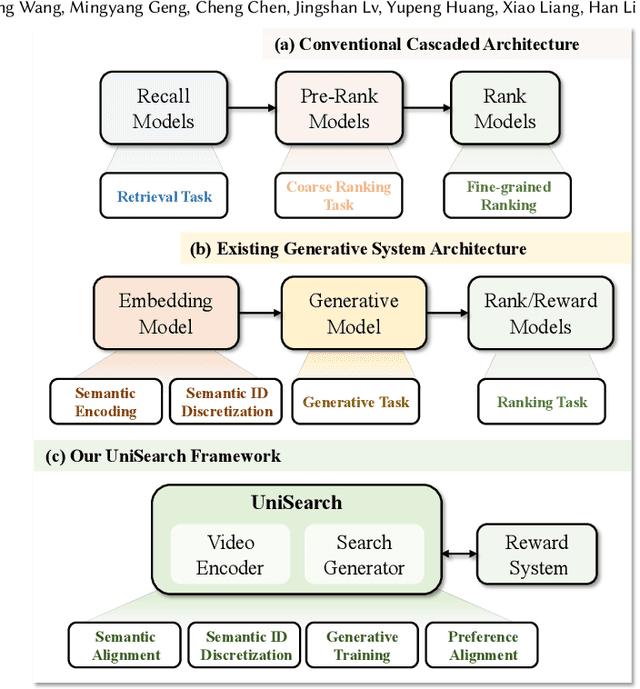
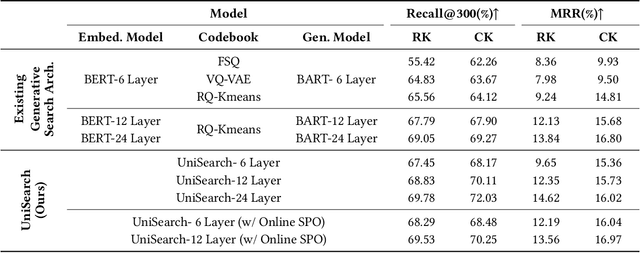
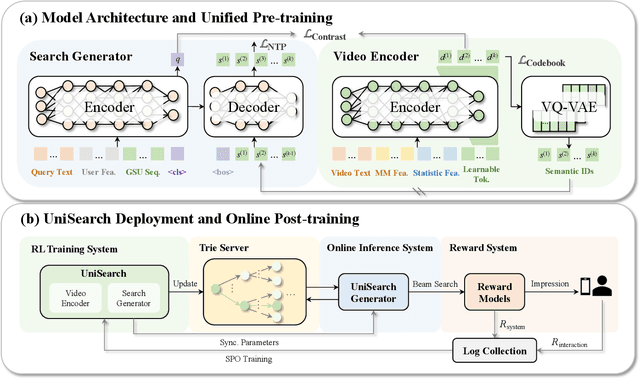
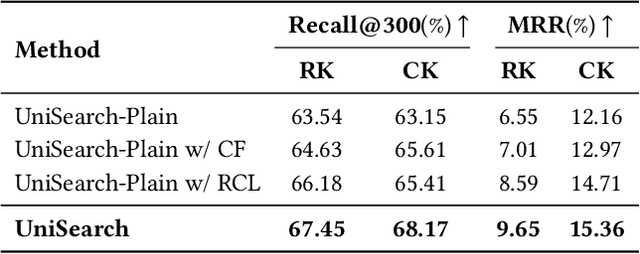
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Deep Fair Discriminative Clustering
May 28, 2021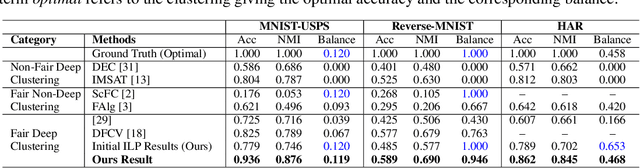

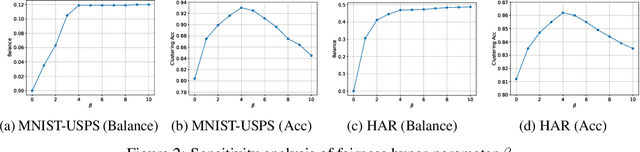
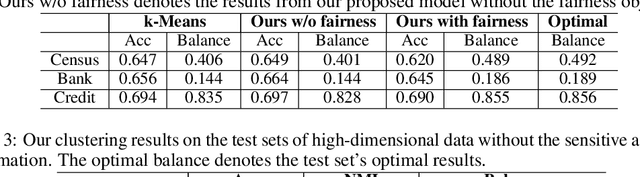
Deep clustering has the potential to learn a strong representation and hence better clustering performance compared to traditional clustering methods such as $k$-means and spectral clustering. However, this strong representation learning ability may make the clustering unfair by discovering surrogates for protected information which we empirically show in our experiments. In this work, we study a general notion of group-level fairness for both binary and multi-state protected status variables (PSVs). We begin by formulating the group-level fairness problem as an integer linear programming formulation whose totally unimodular constraint matrix means it can be efficiently solved via linear programming. We then show how to inject this solver into a discriminative deep clustering backbone and hence propose a refinement learning algorithm to combine the clustering goal with the fairness objective to learn fair clusters adaptively. Experimental results on real-world datasets demonstrate that our model consistently outperforms state-of-the-art fair clustering algorithms. Our framework shows promising results for novel clustering tasks including flexible fairness constraints, multi-state PSVs and predictive clustering.
Deep Descriptive Clustering
May 24, 2021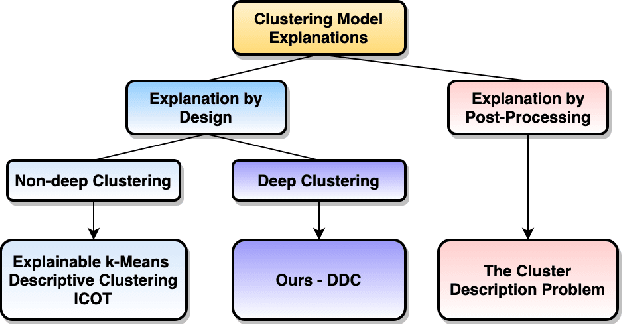

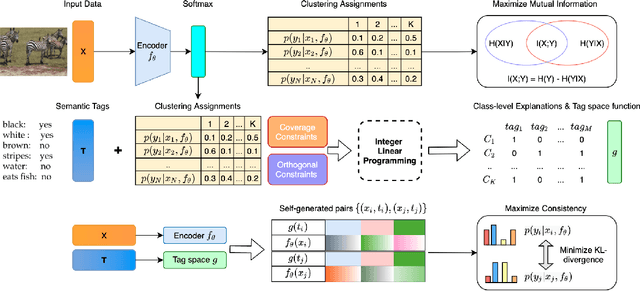

Recent work on explainable clustering allows describing clusters when the features are interpretable. However, much modern machine learning focuses on complex data such as images, text, and graphs where deep learning is used but the raw features of data are not interpretable. This paper explores a novel setting for performing clustering on complex data while simultaneously generating explanations using interpretable tags. We propose deep descriptive clustering that performs sub-symbolic representation learning on complex data while generating explanations based on symbolic data. We form good clusters by maximizing the mutual information between empirical distribution on the inputs and the induced clustering labels for clustering objectives. We generate explanations by solving an integer linear programming that generates concise and orthogonal descriptions for each cluster. Finally, we allow the explanation to inform better clustering by proposing a novel pairwise loss with self-generated constraints to maximize the clustering and explanation module's consistency. Experimental results on public data demonstrate that our model outperforms competitive baselines in clustering performance while offering high-quality cluster-level explanations.
A Framework for Deep Constrained Clustering
Jan 07, 2021

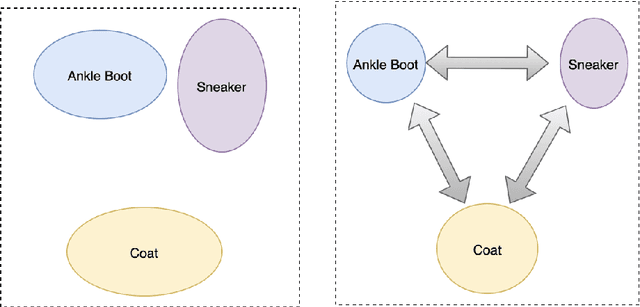
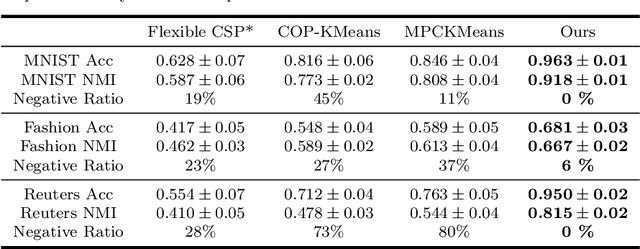
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. A fundamental strength of deep learning is its flexibility, and here we explore a deep learning framework for constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our framework can not only handle standard together/apart constraints (without the well documented negative effects reported earlier) generated from labeled side information but more complex constraints generated from new types of side information such as continuous values and high-level domain knowledge. Furthermore, we propose an efficient training paradigm that is generally applicable to these four types of constraints. We validate the effectiveness of our approach by empirical results on both image and text datasets. We also study the robustness of our framework when learning with noisy constraints and show how different components of our framework contribute to the final performance. Our source code is available at $\href{https://github.com/blueocean92/deep_constrained_clustering}{\text{URL}}$.
Towards Fair Deep Anomaly Detection
Dec 29, 2020


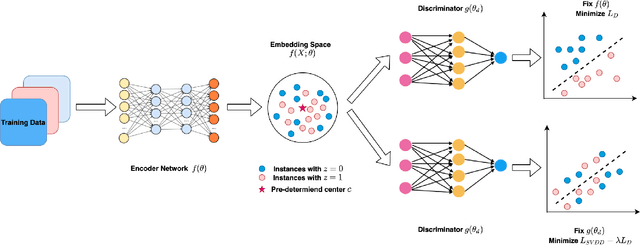
Anomaly detection aims to find instances that are considered unusual and is a fundamental problem of data science. Recently, deep anomaly detection methods were shown to achieve superior results particularly in complex data such as images. Our work focuses on deep one-class classification for anomaly detection which learns a mapping only from the normal samples. However, the non-linear transformation performed by deep learning can potentially find patterns associated with social bias. The challenge with adding fairness to deep anomaly detection is to ensure both making fair and correct anomaly predictions simultaneously. In this paper, we propose a new architecture for the fair anomaly detection approach (Deep Fair SVDD) and train it using an adversarial network to de-correlate the relationships between the sensitive attributes and the learned representations. This differs from how fairness is typically added namely as a regularizer or a constraint. Further, we propose two effective fairness measures and empirically demonstrate that existing deep anomaly detection methods are unfair. We show that our proposed approach can remove the unfairness largely with minimal loss on the anomaly detection performance. Lastly, we conduct an in-depth analysis to show the strength and limitations of our proposed model, including parameter analysis, feature visualization, and run-time analysis.
A Graph-Based Approach for Active Learning in Regression
Jan 30, 2020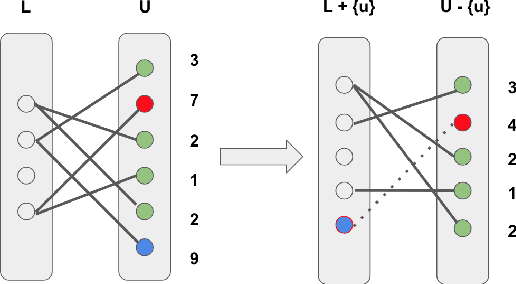
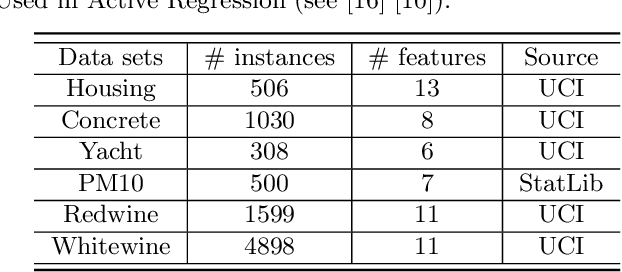
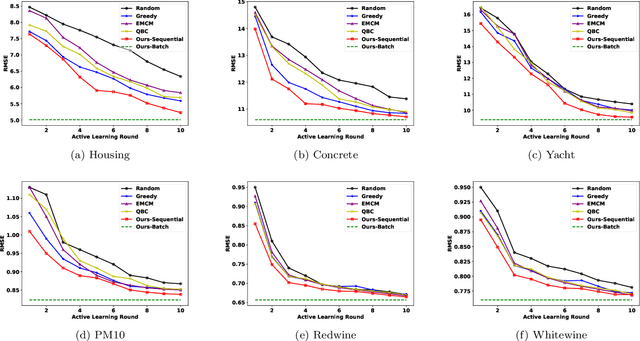
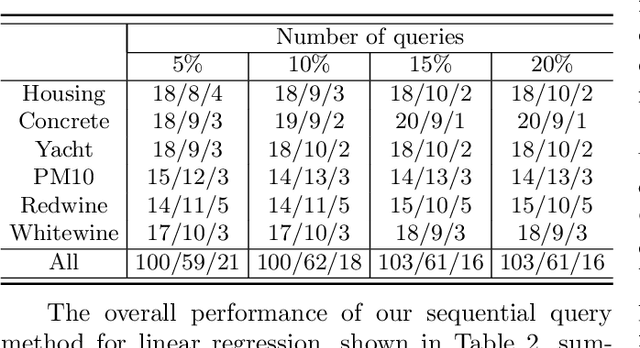
Active learning aims to reduce labeling efforts by selectively asking humans to annotate the most important data points from an unlabeled pool and is an example of human-machine interaction. Though active learning has been extensively researched for classification and ranking problems, it is relatively understudied for regression problems. Most existing active learning for regression methods use the regression function learned at each active learning iteration to select the next informative point to query. This introduces several challenges such as handling noisy labels, parameter uncertainty and overcoming initially biased training data. Instead, we propose a feature-focused approach that formulates both sequential and batch-mode active regression as a novel bipartite graph optimization problem. We conduct experiments on both noise-free and noisy settings. Our experimental results on benchmark data sets demonstrate the effectiveness of our proposed approach.
Deep Constrained Clustering - Algorithms and Advances
Jan 29, 2019


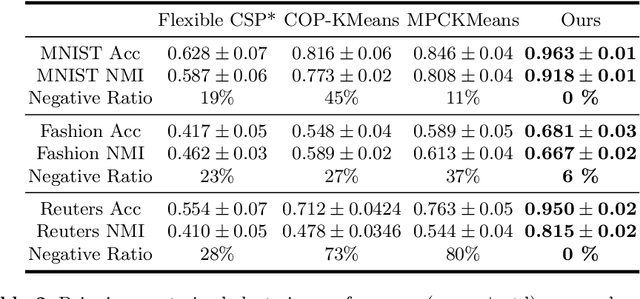
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. We explore a deep learning formulation of constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our formulation can not only handle standard together/apart constraints without the well documented negative effects reported but can also model instance level constraints (level-of-difficulty), cluster level constraints (balancing cluster size) and triplet constraints. The first two are new ways for domain experts to enforce guidance whilst the later importantly allows generating ordering constraints from continuous side-information.