 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mixtures of Spherical Gaussians via Fourier Analysis
Apr 13, 2020Suppose that we are given independent, identically distributed samples $x_l$ from a mixture $\mu$ of no more than $k$ of $d$-dimensional spherical gaussian distributions $\mu_i$ with variance $1$, such that the minimum $\ell_2$ distance between two distinct centers $y_l$ and $y_j$ is greater than $\sqrt{d} \Delta$ for some $c \leq \Delta $, where $c\in (0,1)$ is a small positive universal constant. We develop a randomized algorithm that learns the centers $y_l$ of the gaussians, to within an $\ell_2$ distance of $\delta < \frac{\Delta\sqrt{d}}{2}$ and the weights $w_l$ to within $cw_{min}$ with probability greater than $1 - \exp(-k/c)$. The number of samples and the computational time is bounded above by $poly(k, d, \frac{1}{\delta})$. Such a bound on the sample and computational complexity was previously unknown when $\omega(1) \leq d \leq O(\log k)$. When $d = O(1)$, this follows from work of Regev and Vijayaraghavan. These authors also show that the sample complexity of learning a random mixture of gaussians in a ball of radius $\Theta(\sqrt{d})$ in $d$ dimensions, when $d$ is $\Theta( \log k)$ is at least $poly(k, \frac{1}{\delta})$, showing that our result is tight in this case.
Structural Risk Minimization for $C^{1,1}$ Regression
Mar 30, 2018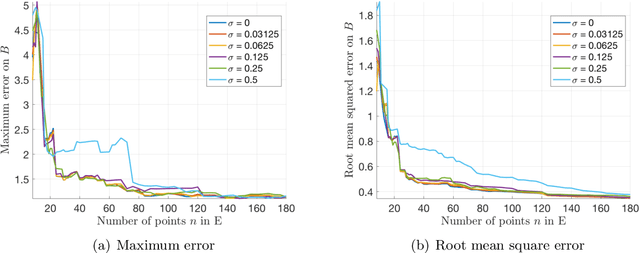
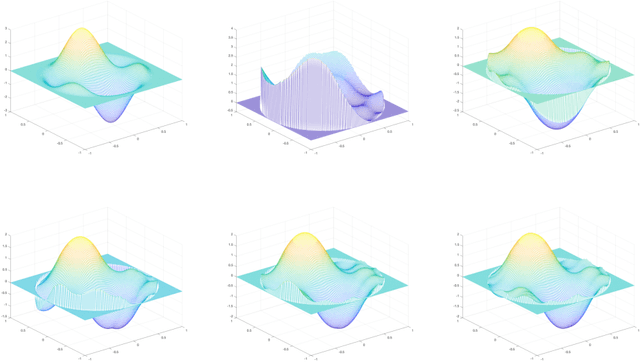
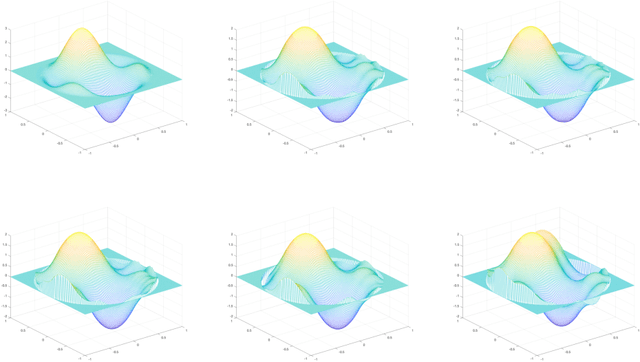
One means of fitting functions to high-dimensional data is by providing smoothness constraints. Recently, the following smooth function approximation problem was proposed: given a finite set $E \subset \mathbb{R}^d$ and a function $f: E \rightarrow \mathbb{R}$, interpolate the given information with a function $\widehat{f} \in \dot{C}^{1, 1}(\mathbb{R}^d)$ (the class of first-order differentiable functions with Lipschitz gradients) such that $\widehat{f}(a) = f(a)$ for all $a \in E$, and the value of $\mathrm{Lip}(\nabla \widehat{f})$ is minimal. An algorithm is provided that constructs such an approximating function $\widehat{f}$ and estimates the optimal Lipschitz constant $\mathrm{Lip}(\nabla \widehat{f})$ in the noiseless setting. We address statistical aspects of reconstructing the approximating function $\widehat{f}$ from a closely-related class $C^{1, 1}(\mathbb{R}^d)$ given samples from noisy data. We observe independent and identically distributed samples $y(a) = f(a) + \xi(a)$ for $a \in E$, where $\xi(a)$ is a noise term and the set $E \subset \mathbb{R}^d$ is fixed and known. We obtain uniform bounds relating the empirical risk and true risk over the class $\mathcal{F}_{\widetilde{M}} = \{f \in C^{1, 1}(\mathbb{R}^d) \mid \mathrm{Lip}(\nabla f) \leq \widetilde{M}\}$, where the quantity $\widetilde{M}$ grows with the number of samples at a rate governed by the metric entropy of the class $C^{1, 1}(\mathbb{R}^d)$. Finally, we provide an implementation using Vaidya's algorithm, supporting our results via numerical experiments on simulated data.
John's Walk
Mar 06, 2018We present an affine-invariant random walk for drawing uniform random samples from a convex body $\mathcal{K} \subset \mathbb{R}^n$ for which the maximum volume inscribed ellipsoid, known as John's ellipsoid, may be computed. We consider a polytope $\mathcal{P} = \{x \in \mathbb{R}^n \mid Ax \leq 1\}$ where $A \in \mathbb{R}^{m \times n}$ as a special case. Our algorithm makes steps using uniform sampling from the John's ellipsoid of the symmetrization of $\mathcal{K}$ at the current point. We show that from a warm start, the random walk mixes in $\widetilde{O}(n^7)$ steps where the log factors depend only on constants determined by the warm start and error parameters (and not on the dimension or number of constraints defining the body). This sampling algorithm thus offers improvement over the affine-invariant Dikin Walk for polytopes (which mixes in $\widetilde{O}(mn)$ steps from a warm start) for applications in which $m \gg n$. Furthermore, we describe an $\widetilde{O}(mn^{\omega+1} + n^{2\omega+2})$ algorithm for finding a suitably approximate John's ellipsoid for a symmetric polytope based on Vaidya's algorithm, and show the mixing time is retained using these approximate ellipsoids (where $\omega < 2.373$ is the current value of the fast matrix multiplication constant).
Manifold Learning Using Kernel Density Estimation and Local Principal Components Analysis
Sep 11, 2017

We consider the problem of recovering a $d-$dimensional manifold $\mathcal{M} \subset \mathbb{R}^n$ when provided with noiseless samples from $\mathcal{M}$. There are many algorithms (e.g., Isomap) that are used in practice to fit manifolds and thus reduce the dimensionality of a given data set. Ideally, the estimate $\mathcal{M}_\mathrm{put}$ of $\mathcal{M}$ should be an actual manifold of a certain smoothness; furthermore, $\mathcal{M}_\mathrm{put}$ should be arbitrarily close to $\mathcal{M}$ in Hausdorff distance given a large enough sample. Generally speaking, existing manifold learning algorithms do not meet these criteria. Fefferman, Mitter, and Narayanan (2016) have developed an algorithm whose output is provably a manifold. The key idea is to define an approximate squared-distance function (asdf) to $\mathcal{M}$. Then, $\mathcal{M}_\mathrm{put}$ is given by the set of points where the gradient of the asdf is orthogonal to the subspace spanned by the largest $n - d$ eigenvectors of the Hessian of the asdf. As long as the asdf meets certain regularity conditions, $\mathcal{M}_\mathrm{put}$ is a manifold that is arbitrarily close in Hausdorff distance to $\mathcal{M}$. In this paper, we define two asdfs that can be calculated from the data and show that they meet the required regularity conditions. The first asdf is based on kernel density estimation, and the second is based on estimation of tangent spaces using local principal components analysis.
Escaping the Local Minima via Simulated Annealing: Optimization of Approximately Convex Functions
Jun 15, 2015We consider the problem of optimizing an approximately convex function over a bounded convex set in $\mathbb{R}^n$ using only function evaluations. The problem is reduced to sampling from an \emph{approximately} log-concave distribution using the Hit-and-Run method, which is shown to have the same $\mathcal{O}^*$ complexity as sampling from log-concave distributions. In addition to extend the analysis for log-concave distributions to approximate log-concave distributions, the implementation of the 1-dimensional sampler of the Hit-and-Run walk requires new methods and analysis. The algorithm then is based on simulated annealing which does not relies on first order conditions which makes it essentially immune to local minima. We then apply the method to different motivating problems. In the context of zeroth order stochastic convex optimization, the proposed method produces an $\epsilon$-minimizer after $\mathcal{O}^*(n^{7.5}\epsilon^{-2})$ noisy function evaluations by inducing a $\mathcal{O}(\epsilon/n)$-approximately log concave distribution. We also consider in detail the case when the "amount of non-convexity" decays towards the optimum of the function. Other applications of the method discussed in this work include private computation of empirical risk minimizers, two-stage stochastic programming, and approximate dynamic programming for online learning.
* 27 pages
On Zeroth-Order Stochastic Convex Optimization via Random Walks
Feb 11, 2014
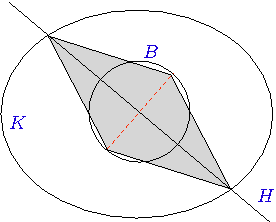
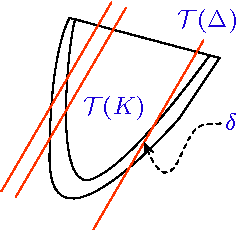
We propose a method for zeroth order stochastic convex optimization that attains the suboptimality rate of $\tilde{\mathcal{O}}(n^{7}T^{-1/2})$ after $T$ queries for a convex bounded function $f:{\mathbb R}^n\to{\mathbb R}$. The method is based on a random walk (the \emph{Ball Walk}) on the epigraph of the function. The randomized approach circumvents the problem of gradient estimation, and appears to be less sensitive to noisy function evaluations compared to noiseless zeroth order methods.
Efficient Sampling from Time-Varying Log-Concave Distributions
Sep 23, 2013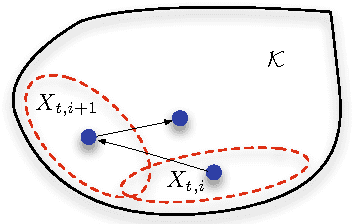
We propose a computationally efficient random walk on a convex body which rapidly mixes and closely tracks a time-varying log-concave distribution. We develop general theoretical guarantees on the required number of steps; this number can be calculated on the fly according to the distance from and the shape of the next distribution. We then illustrate the technique on several examples. Within the context of exponential families, the proposed method produces samples from a posterior distribution which is updated as data arrive in a streaming fashion. The sampling technique can be used to track time-varying truncated distributions, as well as to obtain samples from a changing mixture model, fitted in a streaming fashion to data. In the setting of linear optimization, the proposed method has oracle complexity with best known dependence on the dimension for certain geometries. In the context of online learning and repeated games, the algorithm is an efficient method for implementing no-regret mixture forecasting strategies. Remarkably, in some of these examples, only one step of the random walk is needed to track the next distribution.
Learning with Spectral Kernels and Heavy-Tailed Data
May 10, 2010Two ubiquitous aspects of large-scale data analysis are that the data often have heavy-tailed properties and that diffusion-based or spectral-based methods are often used to identify and extract structure of interest. Perhaps surprisingly, popular distribution-independent methods such as those based on the VC dimension fail to provide nontrivial results for even simple learning problems such as binary classification in these two settings. In this paper, we develop distribution-dependent learning methods that can be used to provide dimension-independent sample complexity bounds for the binary classification problem in these two popular settings. In particular, we provide bounds on the sample complexity of maximum margin classifiers when the magnitude of the entries in the feature vector decays according to a power law and also when learning is performed with the so-called Diffusion Maps kernel. Both of these results rely on bounding the annealed entropy of gap-tolerant classifiers in a Hilbert space. We provide such a bound, and we demonstrate that our proof technique generalizes to the case when the margin is measured with respect to more general Banach space norms. The latter result is of potential interest in cases where modeling the relationship between data elements as a dot product in a Hilbert space is too restrictive.