 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Risk Minimization for $C^{1,1}$ Regression
Paper and Code
Mar 30, 2018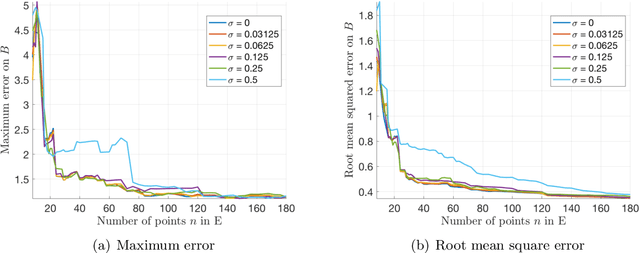
One means of fitting functions to high-dimensional data is by providing smoothness constraints. Recently, the following smooth function approximation problem was proposed: given a finite set $E \subset \mathbb{R}^d$ and a function $f: E \rightarrow \mathbb{R}$, interpolate the given information with a function $\widehat{f} \in \dot{C}^{1, 1}(\mathbb{R}^d)$ (the class of first-order differentiable functions with Lipschitz gradients) such that $\widehat{f}(a) = f(a)$ for all $a \in E$, and the value of $\mathrm{Lip}(\nabla \widehat{f})$ is minimal. An algorithm is provided that constructs such an approximating function $\widehat{f}$ and estimates the optimal Lipschitz constant $\mathrm{Lip}(\nabla \widehat{f})$ in the noiseless setting. We address statistical aspects of reconstructing the approximating function $\widehat{f}$ from a closely-related class $C^{1, 1}(\mathbb{R}^d)$ given samples from noisy data. We observe independent and identically distributed samples $y(a) = f(a) + \xi(a)$ for $a \in E$, where $\xi(a)$ is a noise term and the set $E \subset \mathbb{R}^d$ is fixed and known. We obtain uniform bounds relating the empirical risk and true risk over the class $\mathcal{F}_{\widetilde{M}} = \{f \in C^{1, 1}(\mathbb{R}^d) \mid \mathrm{Lip}(\nabla f) \leq \widetilde{M}\}$, where the quantity $\widetilde{M}$ grows with the number of samples at a rate governed by the metric entropy of the class $C^{1, 1}(\mathbb{R}^d)$. Finally, we provide an implementation using Vaidya's algorithm, supporting our results via numerical experiments on simulated data.