 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Outlier Rejection for Self-Supervised Keypoint Learning
Dec 23, 2019
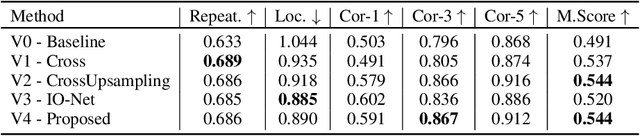
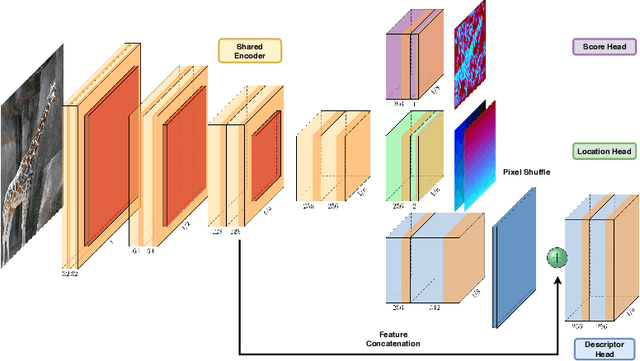
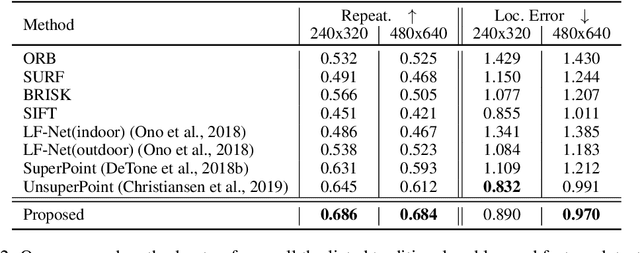
Identifying salient points in images is a crucial component for visual odometry, Structure-from-Motion or SLAM algorithms. Recently, several learned keypoint methods have demonstrated compelling performance on challenging benchmarks. However, generating consistent and accurate training data for interest-point detection in natural images still remains challenging, especially for human annotators. We introduce IO-Net (i.e. InlierOutlierNet), a novel proxy task for the self-supervision of keypoint detection, description and matching. By making the sampling of inlier-outlier sets from point-pair correspondences fully differentiable within the keypoint learning framework, we show that are able to simultaneously self-supervise keypoint description and improve keypoint matching. Second, we introduce KeyPointNet, a keypoint-network architecture that is especially amenable to robust keypoint detection and description. We design the network to allow local keypoint aggregation to avoid artifacts due to spatial discretizations commonly used for this task, and we improve fine-grained keypoint descriptor performance by taking advantage of efficient sub-pixel convolutions to upsample the descriptor feature-maps to a higher operating resolution. Through extensive experiments and ablative analysis, we show that the proposed self-supervised keypoint learning method greatly improves the quality of feature matching and homography estimation on challenging benchmarks over the state-of-the-art.
Self-Supervised 3D Keypoint Learning for Ego-motion Estimation
Dec 07, 2019
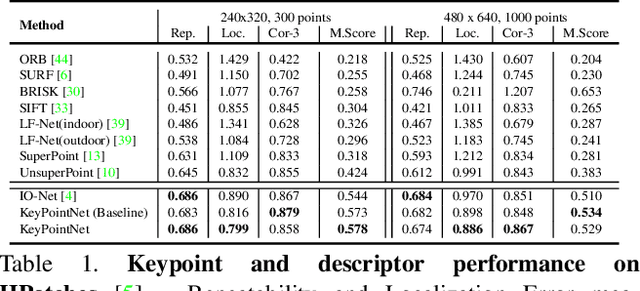
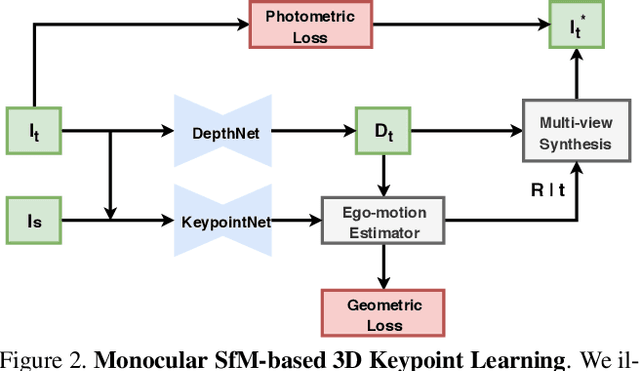

Generating reliable illumination and viewpoint invariant keypoints is critical for feature-based SLAM and SfM. State-of-the-art learning-based methods often rely on generating training samples by employing homography adaptation to create 2D synthetic views. While such approaches trivially solve data association between views, they cannot effectively learn from real illumination and non-planar 3D scenes. In this work, we propose a fully self-supervised approach towards learning depth-aware keypoints \textit{purely} from unlabeled videos by incorporating a differentiable pose estimation module that jointly optimizes the keypoints and their depths in a Structure-from-Motion setting. We introduce 3D Multi-View Adaptation, a technique that exploits the temporal context in videos to self-supervise keypoint detection and matching in an end-to-end differentiable manner. Finally, we show how a fully self-supervised keypoint detection and description network can be trivially incorporated as a front-end into a state-of-the-art visual odometry framework that is robust and accurate.
Place Recognition with Event-based Cameras and a Neural Implementation of SeqSLAM
May 18, 2015

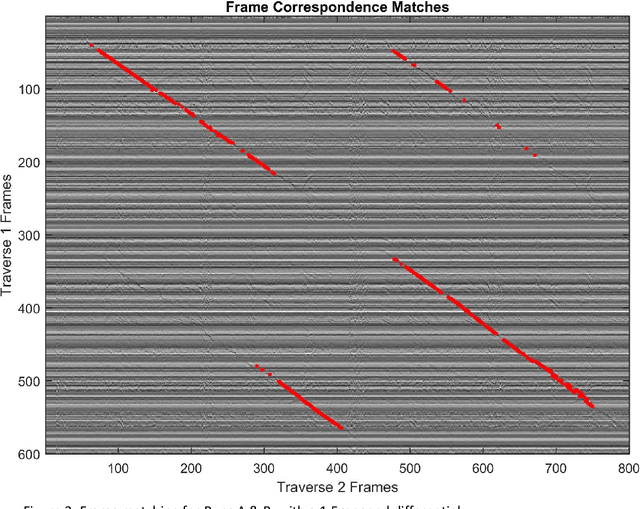
Event-based cameras offer much potential to the fields of robotics and computer vision, in part due to their large dynamic range and extremely high "frame rates". These attributes make them, at least in theory, particularly suitable for enabling tasks like navigation and mapping on high speed robotic platforms under challenging lighting conditions, a task which has been particularly challenging for traditional algorithms and camera sensors. Before these tasks become feasible however, progress must be made towards adapting and innovating current RGB-camera-based algorithms to work with event-based cameras. In this paper we present ongoing research investigating two distinct approaches to incorporating event-based cameras for robotic navigation: the investigation of suitable place recognition / loop closure techniques, and the development of efficient neural implementations of place recognition techniques that enable the possibility of place recognition using event-based cameras at very high frame rates using neuromorphic computing hardware.