 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Outlier Rejection for Self-Supervised Keypoint Learning
Dec 23, 2019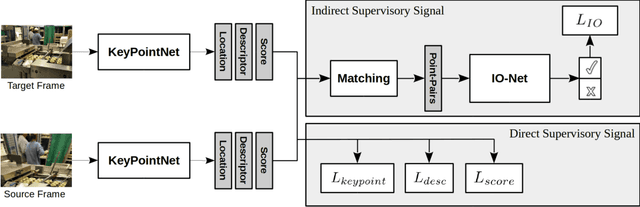
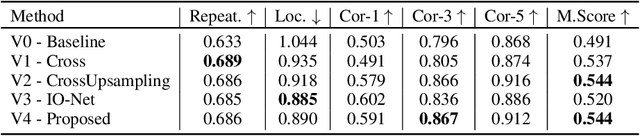
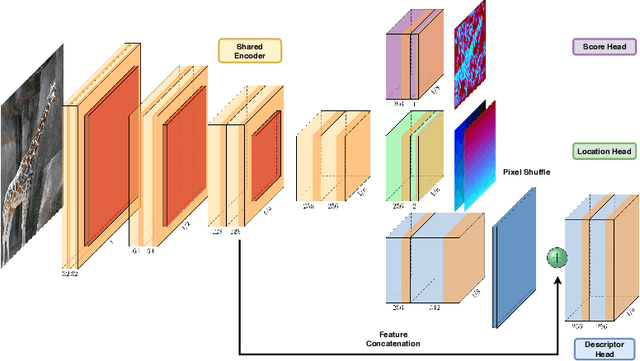
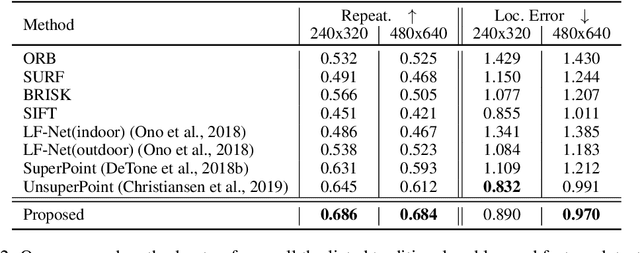
Identifying salient points in images is a crucial component for visual odometry, Structure-from-Motion or SLAM algorithms. Recently, several learned keypoint methods have demonstrated compelling performance on challenging benchmarks. However, generating consistent and accurate training data for interest-point detection in natural images still remains challenging, especially for human annotators. We introduce IO-Net (i.e. InlierOutlierNet), a novel proxy task for the self-supervision of keypoint detection, description and matching. By making the sampling of inlier-outlier sets from point-pair correspondences fully differentiable within the keypoint learning framework, we show that are able to simultaneously self-supervise keypoint description and improve keypoint matching. Second, we introduce KeyPointNet, a keypoint-network architecture that is especially amenable to robust keypoint detection and description. We design the network to allow local keypoint aggregation to avoid artifacts due to spatial discretizations commonly used for this task, and we improve fine-grained keypoint descriptor performance by taking advantage of efficient sub-pixel convolutions to upsample the descriptor feature-maps to a higher operating resolution. Through extensive experiments and ablative analysis, we show that the proposed self-supervised keypoint learning method greatly improves the quality of feature matching and homography estimation on challenging benchmarks over the state-of-the-art.
Self-Supervised 3D Keypoint Learning for Ego-motion Estimation
Dec 07, 2019
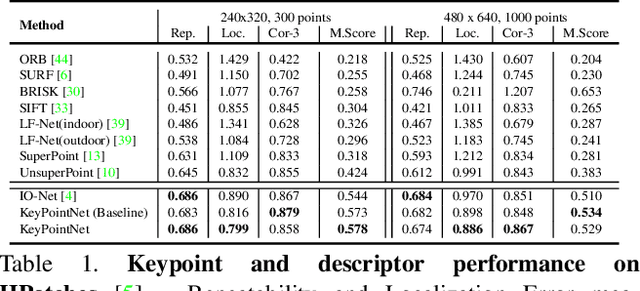
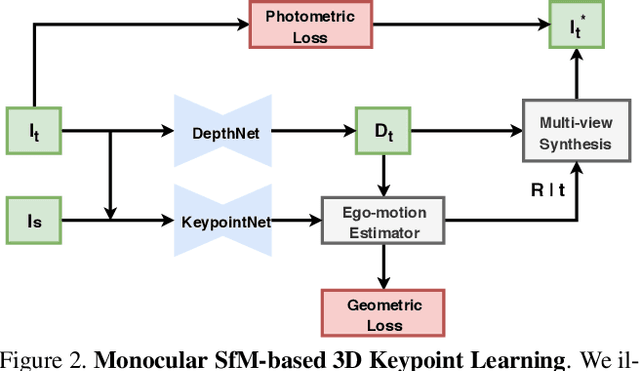

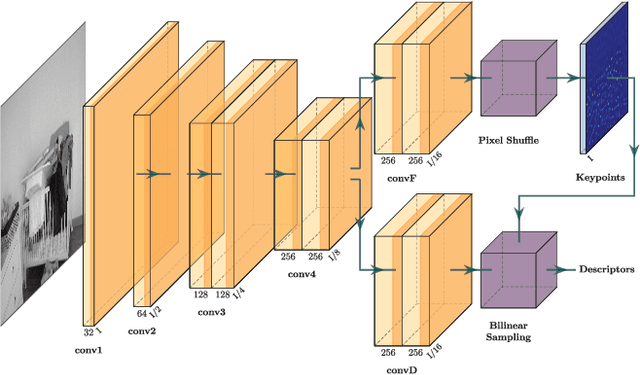
Generating reliable illumination and viewpoint invariant keypoints is critical for feature-based SLAM and SfM. State-of-the-art learning-based methods often rely on generating training samples by employing homography adaptation to create 2D synthetic views. While such approaches trivially solve data association between views, they cannot effectively learn from real illumination and non-planar 3D scenes. In this work, we propose a fully self-supervised approach towards learning depth-aware keypoints \textit{purely} from unlabeled videos by incorporating a differentiable pose estimation module that jointly optimizes the keypoints and their depths in a Structure-from-Motion setting. We introduce 3D Multi-View Adaptation, a technique that exploits the temporal context in videos to self-supervise keypoint detection and matching in an end-to-end differentiable manner. Finally, we show how a fully self-supervised keypoint detection and description network can be trivially incorporated as a front-end into a state-of-the-art visual odometry framework that is robust and accurate.
GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
Mar 23, 2019

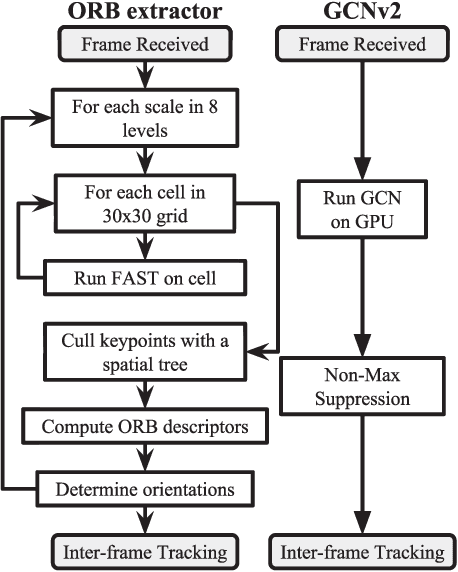
In this paper, we present a deep learning-based network, GCNv2, for generation of keypoints and descriptors. GCNv2 is built on our previous method, GCN, a network trained for 3D projective geometry. GCNv2 is designed with a binary descriptor vector as the ORB feature so that it can easily replace ORB in systems such as ORB-SLAM. GCNv2 significantly improves the computational efficiency over GCN that was only able to run on desktop hardware. We show how a modified version of ORB-SLAM using GCNv2 features runs on a Jetson TX2, an embdded low-power platform. Experimental results show that GCNv2 retains almost the same accuracy as GCN and that it is robust enough to use for control of a flying drone.
Sparse2Dense: From direct sparse odometry to dense 3D reconstruction
Mar 21, 2019



In this paper, we proposed a new deep learning based dense monocular SLAM method. Compared to existing methods, the proposed framework constructs a dense 3D model via a sparse to dense mapping using learned surface normals. With single view learned depth estimation as prior for monocular visual odometry, we obtain both accurate positioning and high quality depth reconstruction. The depth and normal are predicted by a single network trained in a tightly coupled manner.Experimental results show that our method significantly improves the performance of visual tracking and depth prediction in comparison to the state-of-the-art in deep monocular dense SLAM.