 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Deep Image Matting with Flexible Guidance Input
Oct 21, 2021
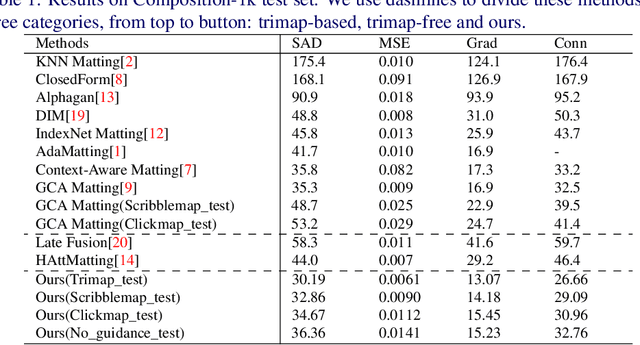
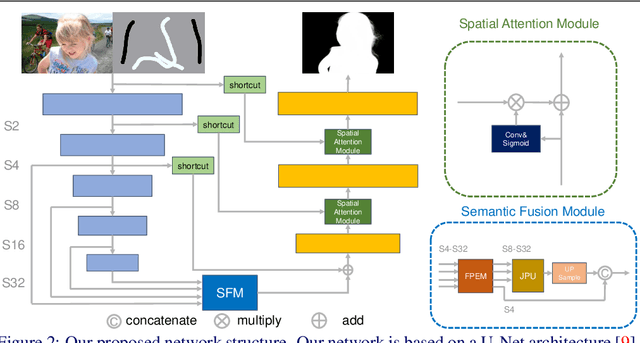

Image matting is an important computer vision problem. Many existing matting methods require a hand-made trimap to provide auxiliary information, which is very expensive and limits the real world usage. Recently, some trimap-free methods have been proposed, which completely get rid of any user input. However, their performance lag far behind trimap-based methods due to the lack of guidance information. In this paper, we propose a matting method that use Flexible Guidance Input as user hint, which means our method can use trimap, scribblemap or clickmap as guidance information or even work without any guidance input. To achieve this, we propose Progressive Trimap Deformation(PTD) scheme that gradually shrink the area of the foreground and background of the trimap with the training step increases and finally become a scribblemap. To make our network robust to any user scribble and click, we randomly sample points on foreground and background and perform curve fitting. Moreover, we propose Semantic Fusion Module(SFM) which utilize the Feature Pyramid Enhancement Module(FPEM) and Joint Pyramid Upsampling(JPU) in matting task for the first time. The experiments show that our method can achieve state-of-the-art results comparing with existing trimap-based and trimap-free methods.