 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Matting with Flexible Guidance Input
Paper and Code

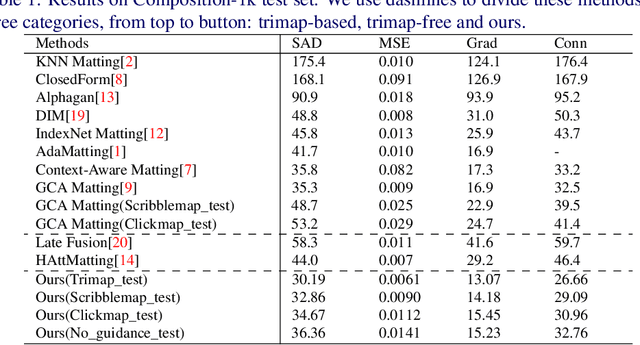
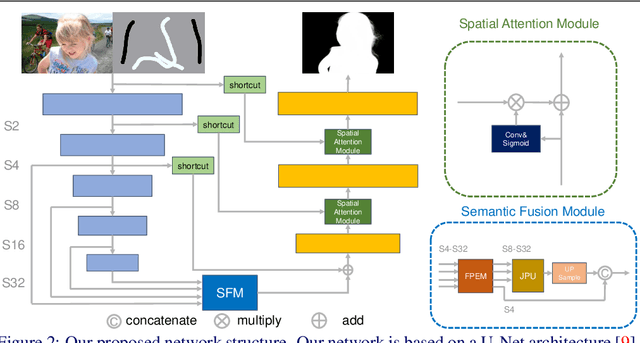

Image matting is an important computer vision problem. Many existing matting methods require a hand-made trimap to provide auxiliary information, which is very expensive and limits the real world usage. Recently, some trimap-free methods have been proposed, which completely get rid of any user input. However, their performance lag far behind trimap-based methods due to the lack of guidance information. In this paper, we propose a matting method that use Flexible Guidance Input as user hint, which means our method can use trimap, scribblemap or clickmap as guidance information or even work without any guidance input. To achieve this, we propose Progressive Trimap Deformation(PTD) scheme that gradually shrink the area of the foreground and background of the trimap with the training step increases and finally become a scribblemap. To make our network robust to any user scribble and click, we randomly sample points on foreground and background and perform curve fitting. Moreover, we propose Semantic Fusion Module(SFM) which utilize the Feature Pyramid Enhancement Module(FPEM) and Joint Pyramid Upsampling(JPU) in matting task for the first time. The experiments show that our method can achieve state-of-the-art results comparing with existing trimap-based and trimap-free methods.