 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Matting with Flexible Guidance Input
Oct 21, 2021
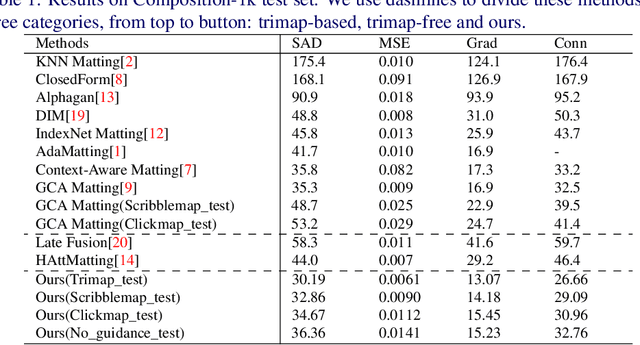
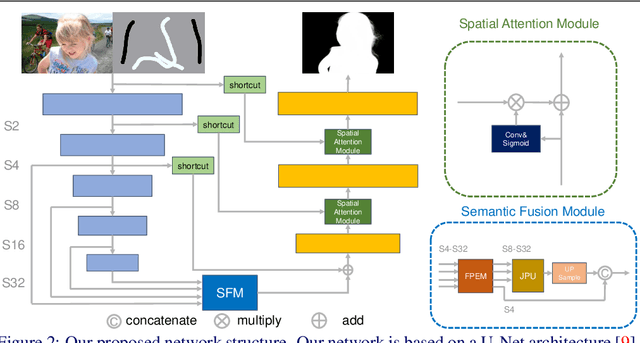

Image matting is an important computer vision problem. Many existing matting methods require a hand-made trimap to provide auxiliary information, which is very expensive and limits the real world usage. Recently, some trimap-free methods have been proposed, which completely get rid of any user input. However, their performance lag far behind trimap-based methods due to the lack of guidance information. In this paper, we propose a matting method that use Flexible Guidance Input as user hint, which means our method can use trimap, scribblemap or clickmap as guidance information or even work without any guidance input. To achieve this, we propose Progressive Trimap Deformation(PTD) scheme that gradually shrink the area of the foreground and background of the trimap with the training step increases and finally become a scribblemap. To make our network robust to any user scribble and click, we randomly sample points on foreground and background and perform curve fitting. Moreover, we propose Semantic Fusion Module(SFM) which utilize the Feature Pyramid Enhancement Module(FPEM) and Joint Pyramid Upsampling(JPU) in matting task for the first time. The experiments show that our method can achieve state-of-the-art results comparing with existing trimap-based and trimap-free methods.
Arbitrary-Shaped Text Detection withAdaptive Text Region Representation
Apr 01, 2021
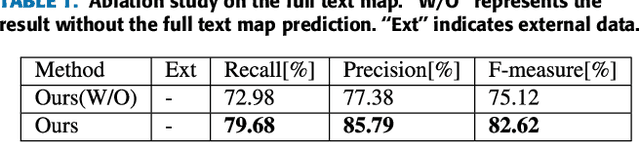

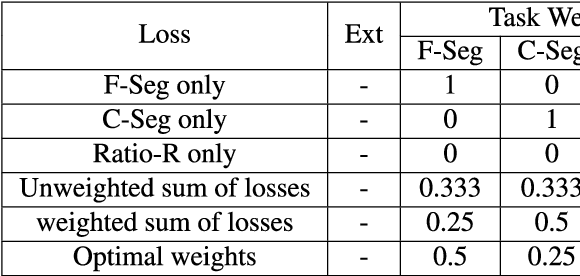
Text detection/localization, as an important task in computer vision, has witnessed substantialadvancements in methodology and performance with convolutional neural networks. However, the vastmajority of popular methods use rectangles or quadrangles to describe text regions. These representationshave inherent drawbacks, especially relating to dense adjacent text and loose regional text boundaries,which usually cause difficulty detecting arbitrarily shaped text. In this paper, we propose a novel text regionrepresentation method, with a robust pipeline, which can precisely detect dense adjacent text instances witharbitrary shapes. We consider a text instance to be composed of an adaptive central text region mask anda corresponding expanding ratio between the central text region and the full text region. More specifically,our pipeline generates adaptive central text regions and corresponding expanding ratios with a proposedtraining strategy, followed by a new proposed post-processing algorithm which expands central text regionsto the complete text instance with the corresponding expanding ratios. We demonstrated that our new textregion representation is effective, and that the pipeline can precisely detect closely adjacent text instances ofarbitrary shapes. Experimental results on common datasets demonstrate superior performance o
Tracking Based Semi-Automatic Annotation for Scene Text Videos
Mar 29, 2021
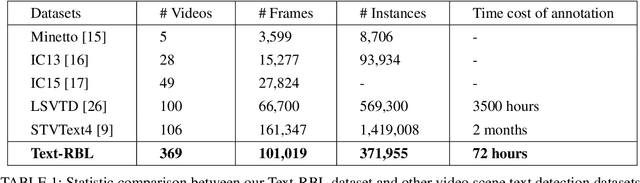

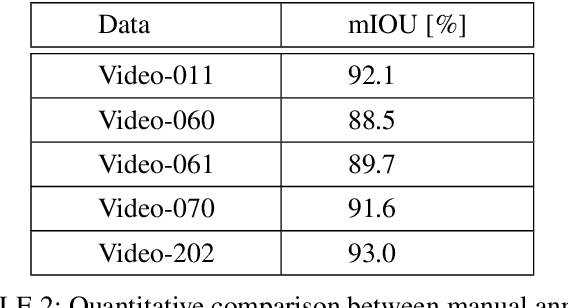
Recently, video scene text detection has received increasing attention due to its comprehensive applications. However, the lack of annotated scene text video datasets has become one of the most important problems, which hinders the development of video scene text detection. The existing scene text video datasets are not large-scale due to the expensive cost caused by manual labeling. In addition, the text instances in these datasets are too clear to be a challenge. To address the above issues, we propose a tracking based semi-automatic labeling strategy for scene text videos in this paper. We get semi-automatic scene text annotation by labeling manually for the first frame and tracking automatically for the subsequent frames, which avoid the huge cost of manual labeling. Moreover, a paired low-quality scene text video dataset named Text-RBL is proposed, consisting of raw videos, blurry videos, and low-resolution videos, labeled by the proposed convenient semi-automatic labeling strategy. Through an averaging operation and bicubic down-sampling operation over the raw videos, we can efficiently obtain blurry videos and low-resolution videos paired with raw videos separately. To verify the effectiveness of Text-RBL, we propose a baseline model combined with the text detector and tracker for video scene text detection. Moreover, a failure detection scheme is designed to alleviate the baseline model drift issue caused by complex scenes. Extensive experiments demonstrate that Text-RBL with paired low-quality videos labeled by the semi-automatic method can significantly improve the performance of the text detector in low-quality scenes.