 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAscend HiFloat8 Format for Deep Learning
Sep 26, 2024



This preliminary white paper proposes a novel 8-bit floating-point data format HiFloat8 (abbreviated as HiF8) for deep learning. HiF8 features tapered precision. For normal value encoding, it provides 7 exponent values with 3-bit mantissa, 8 exponent values with 2-bit mantissa, and 16 exponent values with 1-bit mantissa. For denormal value encoding, it extends the dynamic range by 7 extra powers of 2, from 31 to 38 binades (notice that FP16 covers 40 binades). Meanwhile, HiF8 encodes all the special values except that positive zero and negative zero are represented by only one bit-pattern. Thanks to the better balance between precision and dynamic range, HiF8 can be simultaneously used in both forward and backward passes of AI training. In this paper, we will describe the definition and rounding methods of HiF8, as well as the tentative training and inference solutions. To demonstrate the efficacy of HiF8, massive simulation results on various neural networks, including traditional neural networks and large language models (LLMs), will also be presented.
On the Integration of Self-Attention and Convolution
Nov 29, 2021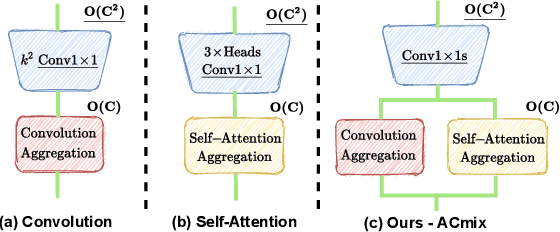

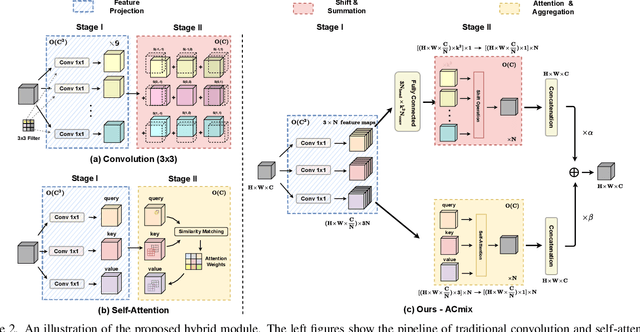

Convolution and self-attention are two powerful techniques for representation learning, and they are usually considered as two peer approaches that are distinct from each other. In this paper, we show that there exists a strong underlying relation between them, in the sense that the bulk of computations of these two paradigms are in fact done with the same operation. Specifically, we first show that a traditional convolution with kernel size k x k can be decomposed into k^2 individual 1x1 convolutions, followed by shift and summation operations. Then, we interpret the projections of queries, keys, and values in self-attention module as multiple 1x1 convolutions, followed by the computation of attention weights and aggregation of the values. Therefore, the first stage of both two modules comprises the similar operation. More importantly, the first stage contributes a dominant computation complexity (square of the channel size) comparing to the second stage. This observation naturally leads to an elegant integration of these two seemingly distinct paradigms, i.e., a mixed model that enjoys the benefit of both self-Attention and Convolution (ACmix), while having minimum computational overhead compared to the pure convolution or self-attention counterpart. Extensive experiments show that our model achieves consistently improved results over competitive baselines on image recognition and downstream tasks. Code and pre-trained models will be released at https://github.com/Panxuran/ACmix and https://gitee.com/mindspore/models.