 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining an NLP Scholar at a Small Liberal Arts College: A Backwards Designed Course Proposal
Aug 11, 2024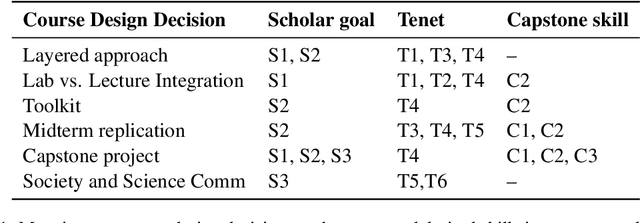

The rapid growth in natural language processing (NLP) over the last couple years has generated student interest and excitement in learning more about the field. In this paper, we present two types of students that NLP courses might want to train. First, an "NLP engineer" who is able to flexibly design, build and apply new technologies in NLP for a wide range of tasks. Second, an "NLP scholar" who is able to pose, refine and answer questions in NLP and how it relates to the society, while also learning to effectively communicate these answers to a broader audience. While these two types of skills are not mutually exclusive -- NLP engineers should be able to think critically, and NLP scholars should be able to build systems -- we think that courses can differ in the balance of these skills. As educators at Small Liberal Arts Colleges, the strengths of our students and our institution favors an approach that is better suited to train NLP scholars. In this paper we articulate what kinds of skills an NLP scholar should have, and then adopt a backwards design to propose course components that can aid the acquisition of these skills.
SPAWNing Structural Priming Predictions from a Cognitively Motivated Parser
Mar 11, 2024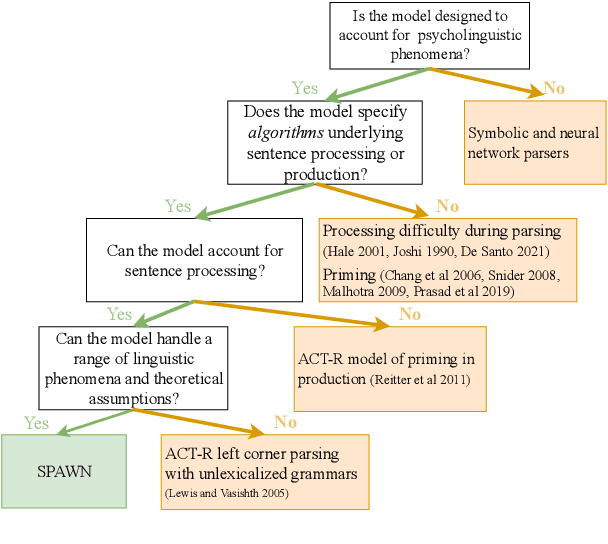

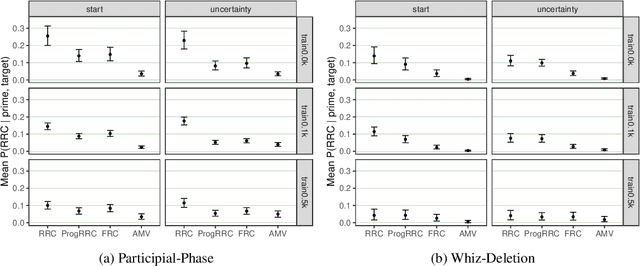

Structural priming is a widely used psycholinguistic paradigm to study human sentence representations. In this work we propose a framework for using empirical priming patterns to build a theory characterizing the structural representations humans construct when processing sentences. This framework uses a new cognitively motivated parser, SPAWN, to generate quantitative priming predictions from theoretical syntax and evaluate these predictions with empirical human behavior. As a case study, we apply this framework to study reduced relative clause representations in English. We use SPAWN to generate priming predictions from two theoretical accounts which make different assumptions about the structure of relative clauses. We find that the predictions from only one of these theories (Participial-Phase) align with empirical priming patterns, thus highlighting which assumptions about relative clause better capture human sentence representations.
Can training neural language models on a curriculum with developmentally plausible data improve alignment with human reading behavior?
Nov 30, 2023The use of neural language models to model human behavior has met with mixed success. While some work has found that the surprisal estimates from these models can be used to predict a wide range of human neural and behavioral responses, other work studying more complex syntactic phenomena has found that these surprisal estimates generate incorrect behavioral predictions. This paper explores the extent to which the misalignment between empirical and model-predicted behavior can be minimized by training models on more developmentally plausible data, such as in the BabyLM Challenge. We trained teacher language models on the BabyLM "strict-small" dataset and used sentence level surprisal estimates from these teacher models to create a curriculum. We found tentative evidence that our curriculum made it easier for models to acquire linguistic knowledge from the training data: on the subset of tasks in the BabyLM challenge suite evaluating models' grammatical knowledge of English, models first trained on the BabyLM data curriculum and then on a few randomly ordered training epochs performed slightly better than models trained on randomly ordered epochs alone. This improved linguistic knowledge acquisition did not result in better alignment with human reading behavior, however: models trained on the BabyLM dataset (with or without a curriculum) generated predictions that were as misaligned with human behavior as models trained on larger less curated datasets. This suggests that training on developmentally plausible datasets alone is likely insufficient to generate language models capable of accurately predicting human language processing.
Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction
May 19, 2021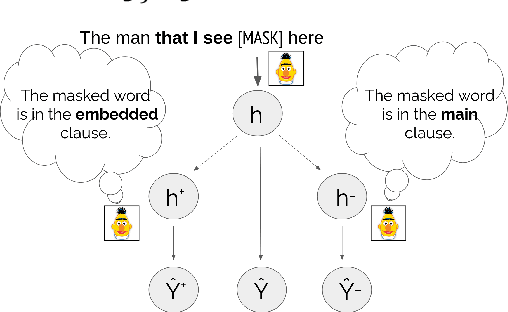

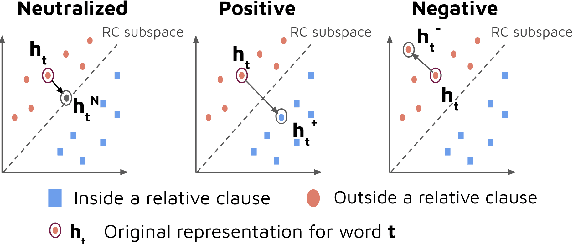
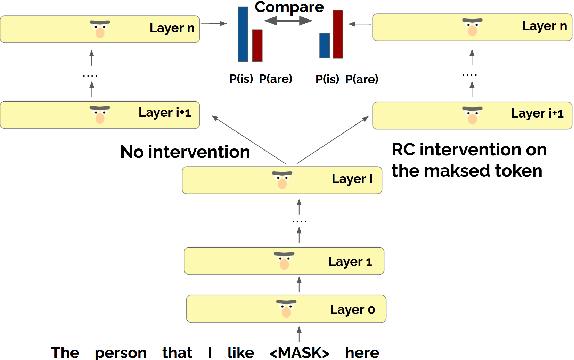
When language models process syntactically complex sentences, do they use abstract syntactic information present in these sentences in a manner that is consistent with the grammar of English, or do they rely solely on a set of heuristics? We propose a method to tackle this question, AlterRep. For any linguistic feature in the sentence, AlterRep allows us to generate counterfactual representations by altering how this feature is encoded, while leaving all other aspects of the original representation intact. Then, by measuring the change in a models' word prediction with these counterfactual representations in different sentences, we can draw causal conclusions about the contexts in which the model uses the linguistic feature (if any). Applying this method to study how BERT uses relative clause (RC) span information, we found that BERT uses information about RC spans during agreement prediction using the linguistically correct strategy. We also found that counterfactual representations generated for a specific RC subtype influenced the number prediction in sentences with other RC subtypes, suggesting that information about RC boundaries was encoded abstractly in BERT's representation.
Dynabench: Rethinking Benchmarking in NLP
Apr 07, 2021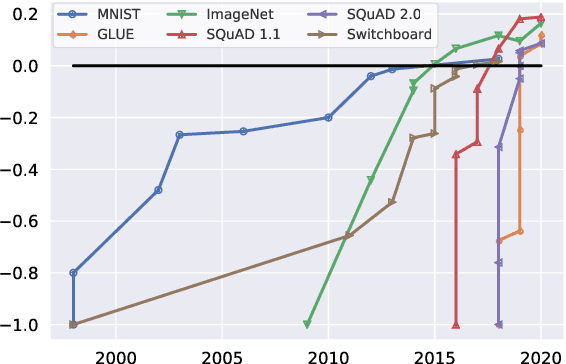
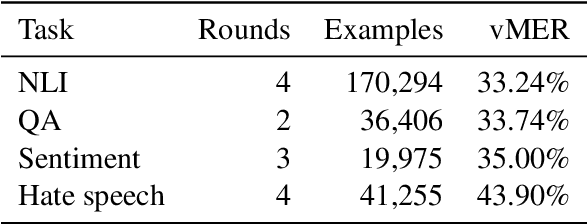
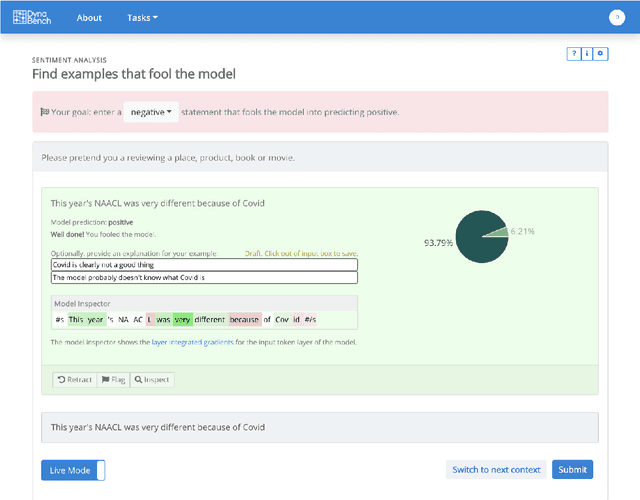
We introduce Dynabench, an open-source platform for dynamic dataset creation and model benchmarking. Dynabench runs in a web browser and supports human-and-model-in-the-loop dataset creation: annotators seek to create examples that a target model will misclassify, but that another person will not. In this paper, we argue that Dynabench addresses a critical need in our community: contemporary models quickly achieve outstanding performance on benchmark tasks but nonetheless fail on simple challenge examples and falter in real-world scenarios. With Dynabench, dataset creation, model development, and model assessment can directly inform each other, leading to more robust and informative benchmarks. We report on four initial NLP tasks, illustrating these concepts and highlighting the promise of the platform, and address potential objections to dynamic benchmarking as a new standard for the field.
To what extent do human explanations of model behavior align with actual model behavior?
Dec 24, 2020

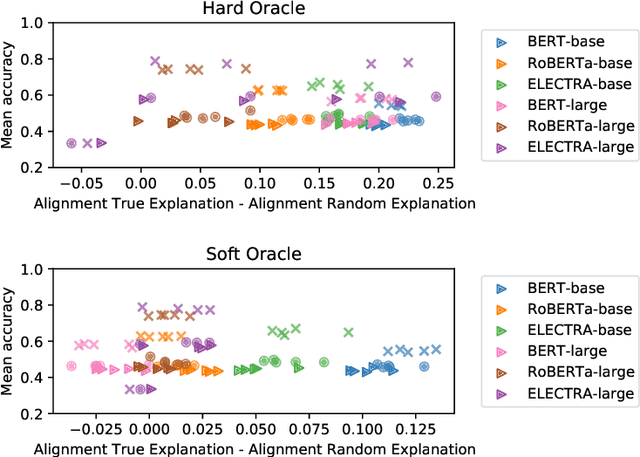
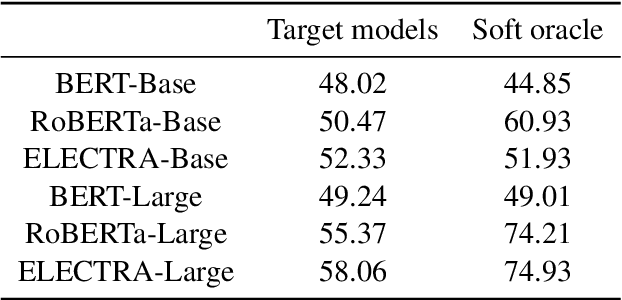
Given the increasingly prominent role NLP models (will) play in our lives, it is important to evaluate models on their alignment with human expectations of how models behave. Using Natural Language Inference (NLI) as a case study, we investigated the extent to which human-generated explanations of models' inference decisions align with how models actually make these decisions. More specifically, we defined two alignment metrics that quantify how well natural language human explanations align with model sensitivity to input words, as measured by integrated gradients. Then, we evaluated six different transformer models (the base and large versions of BERT, RoBERTa and ELECTRA), and found that the BERT-base model has the highest alignment with human-generated explanations, for both alignment metrics. Additionally, the base versions of the models we surveyed tended to have higher alignment with human-generated explanations than their larger counterparts, suggesting that increasing the number model parameters could result in worse alignment with human explanations. Finally, we find that a model's alignment with human explanations is not predicted by the model's accuracy on NLI, suggesting that accuracy and alignment are orthogonal, and both are important ways to evaluate models.
Using Priming to Uncover the Organization of Syntactic Representations in Neural Language Models
Sep 23, 2019
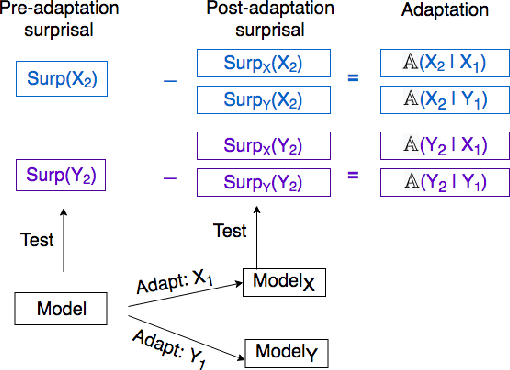


Neural language models (LMs) perform well on tasks that require sensitivity to syntactic structure. Drawing on the syntactic priming paradigm from psycholinguistics, we propose a novel technique to analyze the representations that enable such success. By establishing a gradient similarity metric between structures, this technique allows us to reconstruct the organization of the LMs' syntactic representational space. We use this technique to demonstrate that LSTM LMs' representations of different types of sentences with relative clauses are organized hierarchically in a linguistically interpretable manner, suggesting that the LMs track abstract properties of the sentence.
* 9 pages paper, 2 pages references and 3 pages supplementary materials. Code for the templates and analyses can be found here: https://github.com/grushaprasad/RNN-Priming