 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Group Brainstorming using Conversational Swarm Intelligence (CSI) versus Traditional Chat
Dec 16, 2024Conversational Swarm Intelligence (CSI) is an AI-facilitated method for enabling real-time conversational deliberations and prioritizations among networked human groups of potentially unlimited size. Based on the biological principle of Swarm Intelligence and modelled on the decision-making dynamics of fish schools, CSI has been shown in prior studies to amplify group intelligence, increase group participation, and facilitate productive collaboration among hundreds of participants at once. It works by dividing a large population into a set of small subgroups that are woven together by real-time AI agents called Conversational Surrogates. The present study focuses on the use of a CSI platform called Thinkscape to enable real-time brainstorming and prioritization among groups of 75 networked users. The study employed a variant of a common brainstorming intervention called an Alternative Use Task (AUT) and was designed to compare through subjective feedback, the experience of participants brainstorming using a CSI structure vs brainstorming in a single large chat room. This comparison revealed that participants significantly preferred brainstorming with the CSI structure and reported that it felt (i) more collaborative, (ii) more productive, and (iii) was better at surfacing quality answers. In addition, participants using the CSI structure reported (iv) feeling more ownership and more buy-in in the final answers the group converged on and (v) reported feeling more heard as compared to brainstorming in a traditional text chat environment. Overall, the results suggest that CSI is a very promising AI-facilitated method for brainstorming and prioritization among large-scale, networked human groups.
Towards Collective Superintelligence: Amplifying Group IQ using Conversational Swarms
Jan 25, 2024



Swarm Intelligence (SI) is a natural phenomenon that enables biological groups to amplify their combined intellect by forming real-time systems. Artificial Swarm Intelligence (or Swarm AI) is a technology that enables networked human groups to amplify their combined intelligence by forming similar systems. In the past, swarm-based methods were constrained to narrowly defined tasks like probabilistic forecasting and multiple-choice decision making. A new technology called Conversational Swarm Intelligence (CSI) was developed in 2023 that amplifies the decision-making accuracy of networked human groups through natural conversational deliberations. The current study evaluated the ability of real-time groups using a CSI platform to take a common IQ test known as Raven's Advanced Progressive Matrices (RAPM). First, a baseline group of participants took the Raven's IQ test by traditional survey. This group averaged 45.6% correct. Then, groups of approximately 35 individuals answered IQ test questions together using a CSI platform called Thinkscape. These groups averaged 80.5% correct. This places the CSI groups in the 97th percentile of IQ test-takers and corresponds to an effective IQ increase of 28 points (p<0.001). This is an encouraging result and suggests that CSI is a powerful method for enabling conversational collective intelligence in large, networked groups. In addition, because CSI is scalable across groups of potentially any size, this technology may provide a viable pathway to building a Collective Superintelligence.
Conversational Swarm Intelligence, a Pilot Study
Aug 31, 2023


Conversational Swarm Intelligence (CSI) is a new method for enabling large human groups to hold real-time networked conversations using a technique modeled on the dynamics of biological swarms. Through the novel use of conversational agents powered by Large Language Models (LLMs), the CSI structure simultaneously enables local dialog among small deliberative groups and global propagation of conversational content across a larger population. In this way, CSI combines the benefits of small-group deliberative reasoning and large-scale collective intelligence. In this pilot study, participants deliberating in conversational swarms (via text chat) (a) produced 30% more contributions (p<0.05) than participants deliberating in a standard centralized chat room and (b) demonstrated 7.2% less variance in contribution quantity. These results indicate that users contributed more content and participated more evenly when using the CSI structure.
DECISIVE Benchmarking Data Report: sUAS Performance Results from Phase I
Jan 20, 2023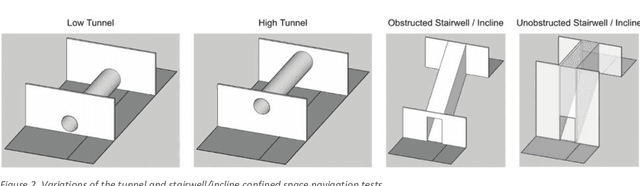
This report reviews all results derived from performance benchmarking conducted during Phase I of the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell, using the test methods specified in the DECISIVE Test Methods Handbook v1.1 for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. Using those 20 test methods, over 230 tests were conducted across 8 sUAS platforms: Cleo Robotics Dronut X1P (P = prototype), FLIR Black Hornet PRS, Flyability Elios 2 GOV, Lumenier Nighthawk V3, Parrot ANAFI USA GOV, Skydio X2D, Teal Golden Eagle, and Vantage Robotics Vesper. Best in class criteria is specified for each applicable test method and the sUAS that match this criteria are named for each test method, including a high-level executive summary of their performance.
DECISIVE Test Methods Handbook: Test Methods for Evaluating sUAS in Subterranean and Constrained Indoor Environments, Version 1.1
Nov 01, 2022
This handbook outlines all test methods developed under the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. For sUAS deployment in subterranean and constrained indoor environments, this puts forth two assumptions about applicable sUAS to be evaluated using these test methods: (1) able to operate without access to GPS signal, and (2) width from prop top to prop tip does not exceed 91 cm (36 in) wide (i.e., can physically fit through a typical doorway, although successful navigation through is not guaranteed). All test methods are specified using a common format: Purpose, Summary of Test Method, Apparatus and Artifacts, Equipment, Metrics, Procedure, and Example Data. All test methods are designed to be run in real-world environments (e.g., MOUT sites) or using fabricated apparatuses (e.g., test bays built from wood, or contained inside of one or more shipping containers).