 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCPO: Uncertainty-Aware Policy Optimization
Jan 30, 2026The key to building trustworthy Large Language Models (LLMs) lies in endowing them with inherent uncertainty expression capabilities to mitigate the hallucinations that restrict their high-stakes applications. However, existing RL paradigms such as GRPO often suffer from Advantage Bias due to binary decision spaces and static uncertainty rewards, inducing either excessive conservatism or overconfidence. To tackle this challenge, this paper unveils the root causes of reward hacking and overconfidence in current RL paradigms incorporating uncertainty-based rewards, based on which we propose the UnCertainty-Aware Policy Optimization (UCPO) framework. UCPO employs Ternary Advantage Decoupling to separate and independently normalize deterministic and uncertain rollouts, thereby eliminating advantage bias. Furthermore, a Dynamic Uncertainty Reward Adjustment mechanism is introduced to calibrate uncertainty weights in real-time according to model evolution and instance difficulty. Experimental results in mathematical reasoning and general tasks demonstrate that UCPO effectively resolves the reward imbalance, significantly improving the reliability and calibration of the model beyond their knowledge boundaries.
Exploiting the Partly Scratch-off Lottery Ticket for Quantization-Aware Training
Nov 21, 2022



Quantization-aware training (QAT) receives extensive popularity as it well retains the performance of quantized networks. In QAT, the contemporary experience is that all quantized weights are updated for an entire training process. In this paper, this experience is challenged based on an interesting phenomenon we observed. Specifically, a large portion of quantized weights reaches the optimal quantization level after a few training epochs, which we refer to as the partly scratch-off lottery ticket. This straightforward-yet-valuable observation naturally inspires us to zero out gradient calculations of these weights in the remaining training period to avoid meaningless updating. To effectively find the ticket, we develop a heuristic method, dubbed as lottery ticket scratcher (LTS), which freezes a weight once the distance between the full-precision one and its quantization level is smaller than a controllable threshold. Surprisingly, the proposed LTS typically eliminates 30%-60% weight updating and 15%-30% FLOPs of the backward pass, while still resulting on par with or even better performance than the compared baseline. For example, compared with the baseline, LTS improves 2-bit ResNet-18 by 1.41%, eliminating 56% weight updating and 28% FLOPs of the backward pass. Code is at https://github.com/zysxmu/LTS.
LAB-Net: LAB Color-Space Oriented Lightweight Network for Shadow Removal
Aug 27, 2022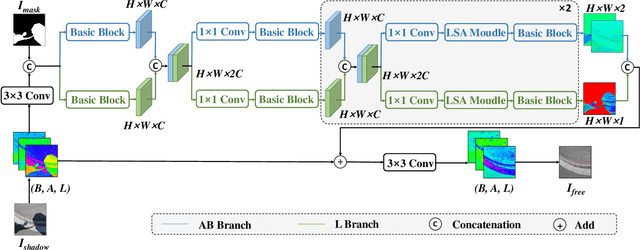
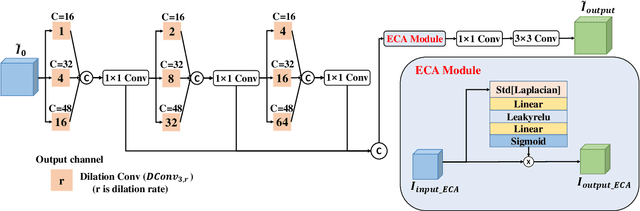
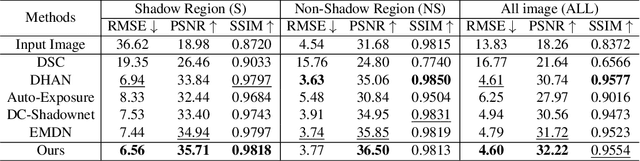

This paper focuses on the limitations of current over-parameterized shadow removal models. We present a novel lightweight deep neural network that processes shadow images in the LAB color space. The proposed network termed "LAB-Net", is motivated by the following three observations: First, the LAB color space can well separate the luminance information and color properties. Second, sequentially-stacked convolutional layers fail to take full use of features from different receptive fields. Third, non-shadow regions are important prior knowledge to diminish the drastic color difference between shadow and non-shadow regions. Consequently, we design our LAB-Net by involving a two-branch structure: L and AB branches. Thus the shadow-related luminance information can well be processed in the L branch, while the color property is well retained in the AB branch. In addition, each branch is composed of several Basic Blocks, local spatial attention modules (LSA), and convolutional filters. Each Basic Block consists of multiple parallelized dilated convolutions of divergent dilation rates to receive different receptive fields that are operated with distinct network widths to save model parameters and computational costs. Then, an enhanced channel attention module (ECA) is constructed to aggregate features from different receptive fields for better shadow removal. Finally, the LSA modules are further developed to fully use the prior information in non-shadow regions to cleanse the shadow regions. We perform extensive experiments on the both ISTD and SRD datasets. Experimental results show that our LAB-Net well outperforms state-of-the-art methods. Also, our model's parameters and computational costs are reduced by several orders of magnitude. Our code is available at https://github.com/ngrxmu/LAB-Net.
IntraQ: Learning Synthetic Images with Intra-Class Heterogeneity for Zero-Shot Network Quantization
Dec 03, 2021

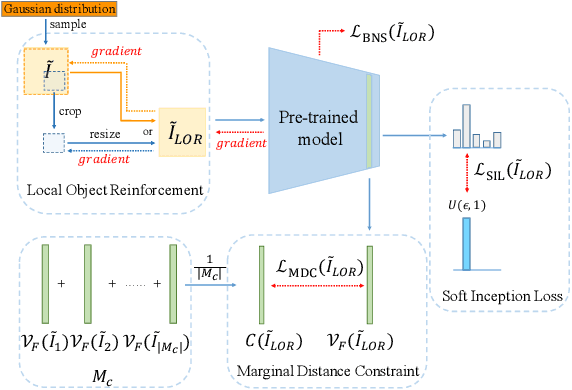

Learning to synthesize data has emerged as a promising direction in zero-shot quantization (ZSQ), which represents neural networks by low-bit integer without accessing any of the real data. In this paper, we observe an interesting phenomenon of intra-class heterogeneity in real data and show that existing methods fail to retain this property in their synthetic images, which causes a limited performance increase. To address this issue, we propose a novel zero-shot quantization method referred to as IntraQ. First, we propose a local object reinforcement that locates the target objects at different scales and positions of the synthetic images. Second, we introduce a marginal distance constraint to form class-related features distributed in a coarse area. Lastly, we devise a soft inception loss which injects a soft prior label to prevent the synthetic images from being overfitting to a fixed object. Our IntraQ is demonstrated to well retain the intra-class heterogeneity in the synthetic images and also observed to perform state-of-the-art. For example, compared to the advanced ZSQ, our IntraQ obtains 9.17\% increase of the top-1 accuracy on ImageNet when all layers of MobileNetV1 are quantized to 4-bit. Code is at https://github.com/zysxmu/InterQ.