 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLICKER: A Computational LInguistics Classification Scheme for Educational Resources
Dec 16, 2021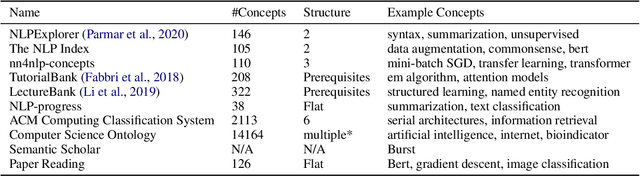
A classification scheme of a scientific subject gives an overview of its body of knowledge. It can also be used to facilitate access to research articles and other materials related to the subject. For example, the ACM Computing Classification System (CCS) is used in the ACM Digital Library search interface and also for indexing computer science papers. We observed that a comprehensive classification system like CCS or Mathematics Subject Classification (MSC) does not exist for Computational Linguistics (CL) and Natural Language Processing (NLP). We propose a classification scheme -- CLICKER for CL/NLP based on the analysis of online lectures from 77 university courses on this subject. The currently proposed taxonomy includes 334 topics and focuses on educational aspects of CL/NLP; it is based primarily, but not exclusively, on lecture notes from NLP courses. We discuss how such a taxonomy can help in various real-world applications, including tutoring platforms, resource retrieval, resource recommendation, prerequisite chain learning, and survey generation.
Techniques for Jointly Extracting Entities and Relations: A Survey
Mar 10, 2021
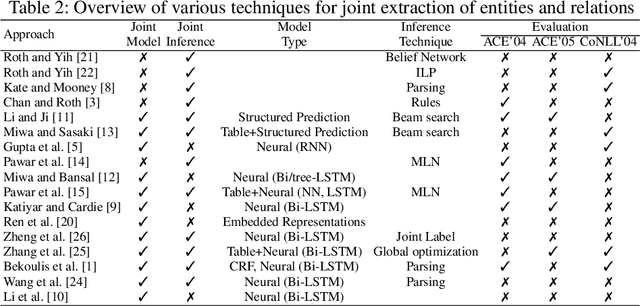
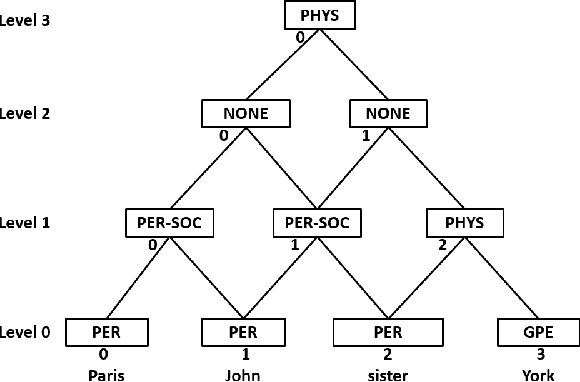
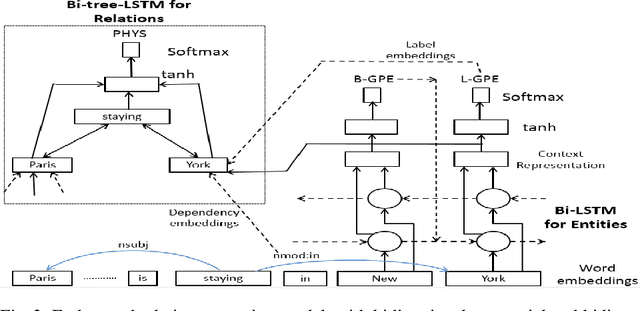
Relation Extraction is an important task in Information Extraction which deals with identifying semantic relations between entity mentions. Traditionally, relation extraction is carried out after entity extraction in a "pipeline" fashion, so that relation extraction only focuses on determining whether any semantic relation exists between a pair of extracted entity mentions. This leads to propagation of errors from entity extraction stage to relation extraction stage. Also, entity extraction is carried out without any knowledge about the relations. Hence, it was observed that jointly performing entity and relation extraction is beneficial for both the tasks. In this paper, we survey various techniques for jointly extracting entities and relations. We categorize techniques based on the approach they adopt for joint extraction, i.e. whether they employ joint inference or joint modelling or both. We further describe some representative techniques for joint inference and joint modelling. We also describe two standard datasets, evaluation techniques and performance of the joint extraction approaches on these datasets. We present a brief analysis of application of a general domain joint extraction approach to a Biomedical dataset. This survey is useful for researchers as well as practitioners in the field of Information Extraction, by covering a broad landscape of joint extraction techniques.
Knowledge-based Extraction of Cause-Effect Relations from Biomedical Text
Mar 10, 2021


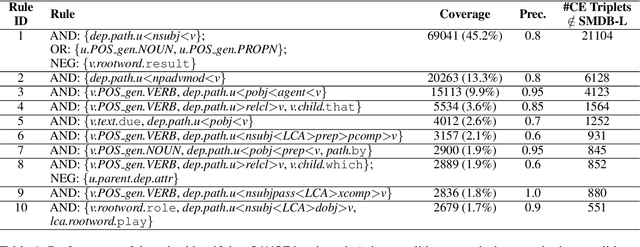
We propose a knowledge-based approach for extraction of Cause-Effect (CE) relations from biomedical text. Our approach is a combination of an unsupervised machine learning technique to discover causal triggers and a set of high-precision linguistic rules to identify cause/effect arguments of these causal triggers. We evaluate our approach using a corpus of 58,761 Leukaemia-related PubMed abstracts consisting of 568,528 sentences. We could extract 152,655 CE triplets from this corpus where each triplet consists of a cause phrase, an effect phrase and a causal trigger. As compared to the existing knowledge base - SemMedDB (Kilicoglu et al., 2012), the number of extractions are almost twice. Moreover, the proposed approach outperformed the existing technique SemRep (Rindflesch and Fiszman, 2003) on a dataset of 500 sentences.
Extracting N-ary Cross-sentence Relations using Constrained Subsequence Kernel
Jun 15, 2020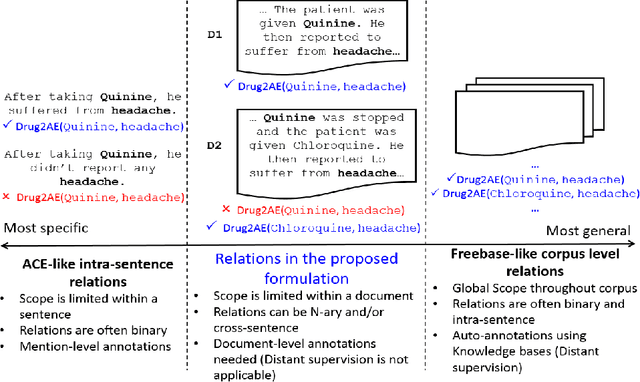



Most of the past work in relation extraction deals with relations occurring within a sentence and having only two entity arguments. We propose a new formulation of the relation extraction task where the relations are more general than intra-sentence relations in the sense that they may span multiple sentences and may have more than two arguments. Moreover, the relations are more specific than corpus-level relations in the sense that their scope is limited only within a document and not valid globally throughout the corpus. We propose a novel sequence representation to characterize instances of such relations. We then explore various classifiers whose features are derived from this sequence representation. For SVM classifier, we design a Constrained Subsequence Kernel which is a variant of Generalized Subsequence Kernel. We evaluate our approach on three datasets across two domains: biomedical and general domain.
Multi-Task Learning for Extraction of Adverse Drug Reaction Mentions from Tweets
Feb 14, 2018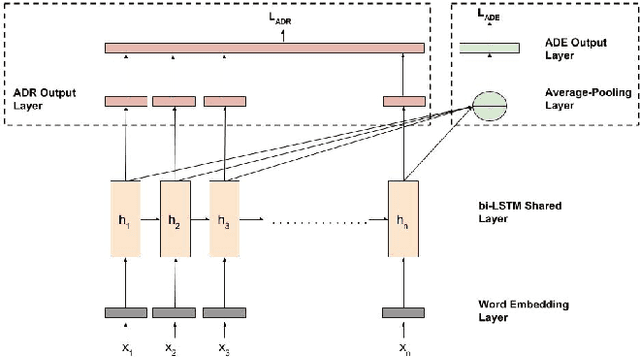
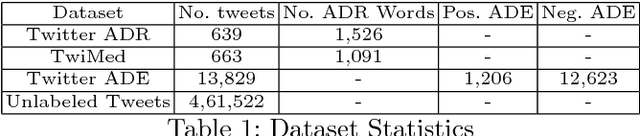
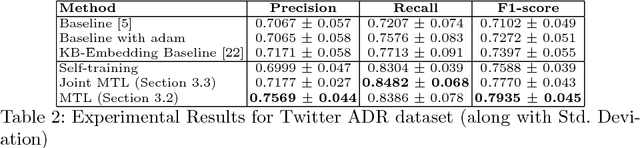

Adverse drug reactions (ADRs) are one of the leading causes of mortality in health care. Current ADR surveillance systems are often associated with a substantial time lag before such events are officially published. On the other hand, online social media such as Twitter contain information about ADR events in real-time, much before any official reporting. Current state-of-the-art in ADR mention extraction uses Recurrent Neural Networks (RNN), which typically need large labeled corpora. Towards this end, we propose a multi-task learning based method which can utilize a similar auxiliary task (adverse drug event detection) to enhance the performance of the main task, i.e., ADR extraction. Furthermore, in the absence of auxiliary task dataset, we propose a novel joint multi-task learning method to automatically generate weak supervision dataset for the auxiliary task when a large pool of unlabeled tweets is available. Experiments with 0.48M tweets show that the proposed approach outperforms the state-of-the-art methods for the ADR mention extraction task by 7.2% in terms of F1 score.
Co-training for Extraction of Adverse Drug Reaction Mentions from Tweets
Feb 14, 2018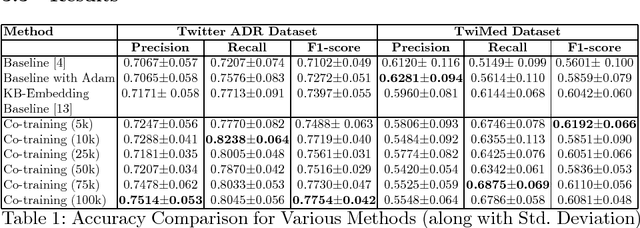
Adverse drug reactions (ADRs) are one of the leading causes of mortality in health care. Current ADR surveillance systems are often associated with a substantial time lag before such events are officially published. On the other hand, online social media such as Twitter contain information about ADR events in real-time, much before any official reporting. Current state-of-the-art methods in ADR mention extraction use Recurrent Neural Networks (RNN), which typically need large labeled corpora. Towards this end, we propose a semi-supervised method based on co-training which can exploit a large pool of unlabeled tweets to augment the limited supervised training data, and as a result enhance the performance. Experiments with 0.1M tweets show that the proposed approach outperforms the state-of-the-art methods for the ADR mention extraction task by 5% in terms of F1 score.
Relation Extraction : A Survey
Dec 14, 2017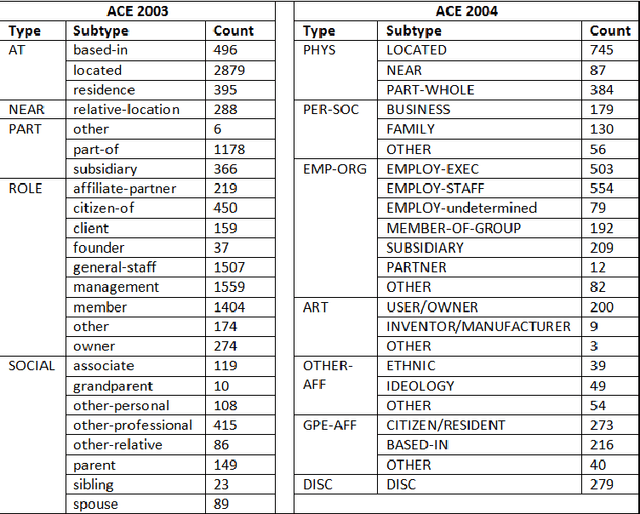

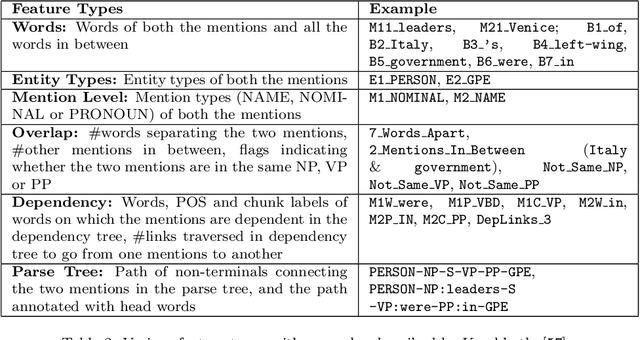
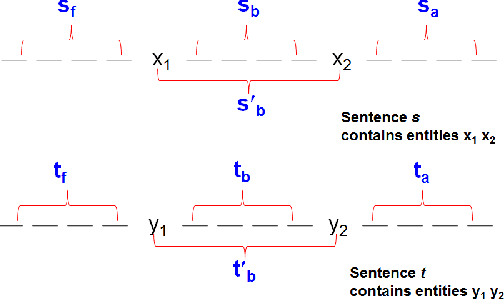
With the advent of the Internet, large amount of digital text is generated everyday in the form of news articles, research publications, blogs, question answering forums and social media. It is important to develop techniques for extracting information automatically from these documents, as lot of important information is hidden within them. This extracted information can be used to improve access and management of knowledge hidden in large text corpora. Several applications such as Question Answering, Information Retrieval would benefit from this information. Entities like persons and organizations, form the most basic unit of the information. Occurrences of entities in a sentence are often linked through well-defined relations; e.g., occurrences of person and organization in a sentence may be linked through relations such as employed at. The task of Relation Extraction (RE) is to identify such relations automatically. In this paper, we survey several important supervised, semi-supervised and unsupervised RE techniques. We also cover the paradigms of Open Information Extraction (OIE) and Distant Supervision. Finally, we describe some of the recent trends in the RE techniques and possible future research directions. This survey would be useful for three kinds of readers - i) Newcomers in the field who want to quickly learn about RE; ii) Researchers who want to know how the various RE techniques evolved over time and what are possible future research directions and iii) Practitioners who just need to know which RE technique works best in various settings.
End-to-End Relation Extraction using Markov Logic Networks
Dec 04, 2017



The task of end-to-end relation extraction consists of two sub-tasks: i) identifying entity mentions along with their types and ii) recognizing semantic relations among the entity mention pairs. %Identifying entity mentions along with their types and recognizing semantic relations among the entity mentions, are two very important problems in Information Extraction. It has been shown that for better performance, it is necessary to address these two sub-tasks jointly. We propose an approach for simultaneous extraction of entity mentions and relations in a sentence, by using inference in Markov Logic Networks (MLN). We learn three different classifiers : i) local entity classifier, ii) local relation classifier and iii) "pipeline" relation classifier which uses predictions of the local entity classifier. Predictions of these classifiers may be inconsistent with each other. We represent these predictions along with some domain knowledge using weighted first-order logic rules in an MLN and perform joint inference over the MLN to obtain a global output with minimum inconsistencies. Experiments on the ACE (Automatic Content Extraction) 2004 dataset demonstrate that our approach of joint extraction using MLNs outperforms the baselines of individual classifiers. Our end-to-end relation extraction performance is better than 2 out of 3 previous results reported on the ACE 2004 dataset.
Topics and Label Propagation: Best of Both Worlds for Weakly Supervised Text Classification
Dec 04, 2017
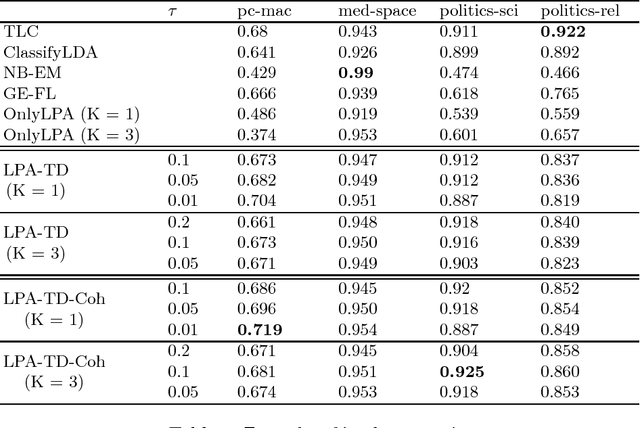


We propose a Label Propagation based algorithm for weakly supervised text classification. We construct a graph where each document is represented by a node and edge weights represent similarities among the documents. Additionally, we discover underlying topics using Latent Dirichlet Allocation (LDA) and enrich the document graph by including the topics in the form of additional nodes. The edge weights between a topic and a text document represent level of "affinity" between them. Our approach does not require document level labelling, instead it expects manual labels only for topic nodes. This significantly minimizes the level of supervision needed as only a few topics are observed to be enough for achieving sufficiently high accuracy. The Label Propagation Algorithm is employed on this enriched graph to propagate labels among the nodes. Our approach combines the advantages of Label Propagation (through document-document similarities) and Topic Modelling (for minimal but smart supervision). We demonstrate the effectiveness of our approach on various datasets and compare with state-of-the-art weakly supervised text classification approaches.