 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Statute Prediction via Attention-based Model and LLM Prompting
Dec 26, 2025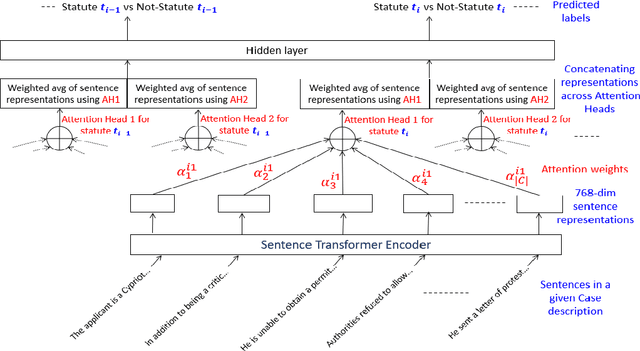

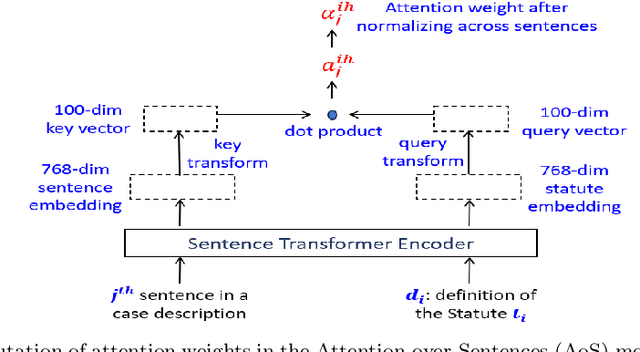
In this paper, we explore the problem of automatic statute prediction where for a given case description, a subset of relevant statutes are to be predicted. Here, the term "statute" refers to a section, a sub-section, or an article of any specific Act. Addressing this problem would be useful in several applications such as AI-assistant for lawyers and legal question answering system. For better user acceptance of such Legal AI systems, we believe the predictions should also be accompanied by human understandable explanations. We propose two techniques for addressing this problem of statute prediction with explanations -- (i) AoS (Attention-over-Sentences) which uses attention over sentences in a case description to predict statutes relevant for it and (ii) LLMPrompt which prompts an LLM to predict as well as explain relevance of a certain statute. AoS uses smaller language models, specifically sentence transformers and is trained in a supervised manner whereas LLMPrompt uses larger language models in a zero-shot manner and explores both standard as well as Chain-of-Thought (CoT) prompting techniques. Both these models produce explanations for their predictions in human understandable forms. We compare statute prediction performance of both the proposed techniques with each other as well as with a set of competent baselines, across two popular datasets. Also, we evaluate the quality of the generated explanations through an automated counter-factual manner as well as through human evaluation.
Broken Words, Broken Performance: Effect of Tokenization on Performance of LLMs
Dec 26, 2025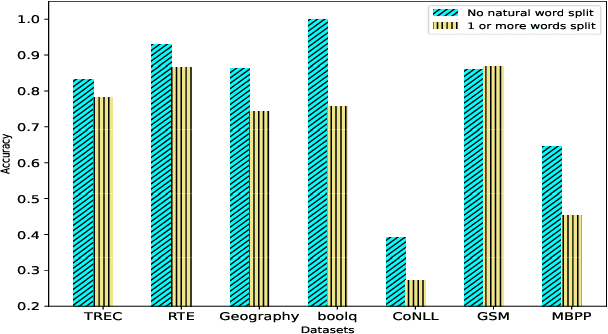


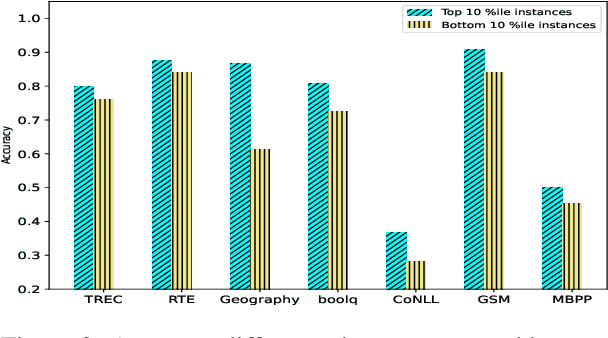
Tokenization is the first step in training any Large Language Model (LLM), where the text is split into a sequence of tokens as per the model's fixed vocabulary. This tokenization in LLMs is different from the traditional tokenization in NLP where the text is split into a sequence of "natural" words. In LLMs, a natural word may also be broken into multiple tokens due to limited vocabulary size of the LLMs (e.g., Mistral's tokenizer splits "martial" into "mart" and "ial"). In this paper, we hypothesize that such breaking of natural words negatively impacts LLM performance on various NLP tasks. To quantify this effect, we propose a set of penalty functions that compute a tokenization penalty for a given text for a specific LLM, indicating how "bad" the tokenization is. We establish statistical significance of our hypothesis on multiple NLP tasks for a set of different LLMs.
Multi-Task Learning for Extraction of Adverse Drug Reaction Mentions from Tweets
Feb 14, 2018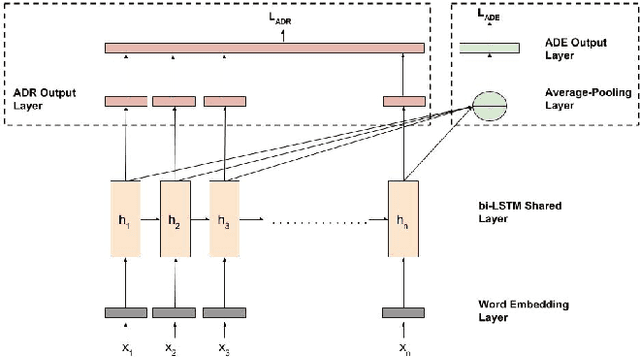
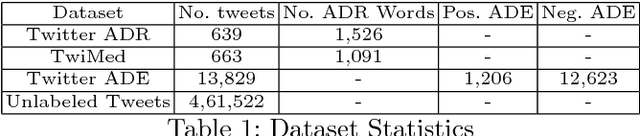
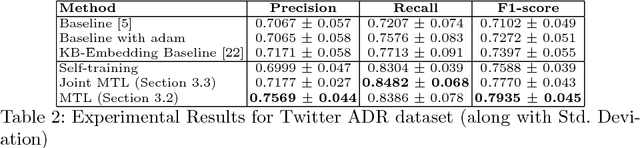

Adverse drug reactions (ADRs) are one of the leading causes of mortality in health care. Current ADR surveillance systems are often associated with a substantial time lag before such events are officially published. On the other hand, online social media such as Twitter contain information about ADR events in real-time, much before any official reporting. Current state-of-the-art in ADR mention extraction uses Recurrent Neural Networks (RNN), which typically need large labeled corpora. Towards this end, we propose a multi-task learning based method which can utilize a similar auxiliary task (adverse drug event detection) to enhance the performance of the main task, i.e., ADR extraction. Furthermore, in the absence of auxiliary task dataset, we propose a novel joint multi-task learning method to automatically generate weak supervision dataset for the auxiliary task when a large pool of unlabeled tweets is available. Experiments with 0.48M tweets show that the proposed approach outperforms the state-of-the-art methods for the ADR mention extraction task by 7.2% in terms of F1 score.
Co-training for Extraction of Adverse Drug Reaction Mentions from Tweets
Feb 14, 2018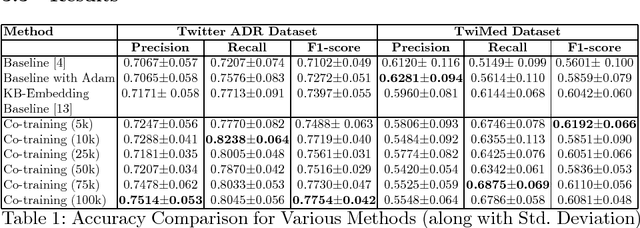
Adverse drug reactions (ADRs) are one of the leading causes of mortality in health care. Current ADR surveillance systems are often associated with a substantial time lag before such events are officially published. On the other hand, online social media such as Twitter contain information about ADR events in real-time, much before any official reporting. Current state-of-the-art methods in ADR mention extraction use Recurrent Neural Networks (RNN), which typically need large labeled corpora. Towards this end, we propose a semi-supervised method based on co-training which can exploit a large pool of unlabeled tweets to augment the limited supervised training data, and as a result enhance the performance. Experiments with 0.1M tweets show that the proposed approach outperforms the state-of-the-art methods for the ADR mention extraction task by 5% in terms of F1 score.
Mining Supervisor Evaluation and Peer Feedback in Performance Appraisals
Dec 04, 2017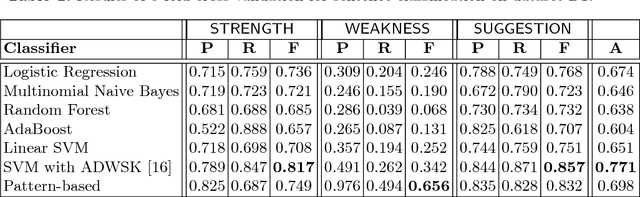
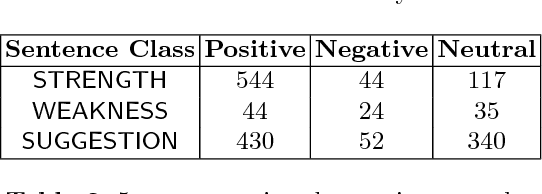
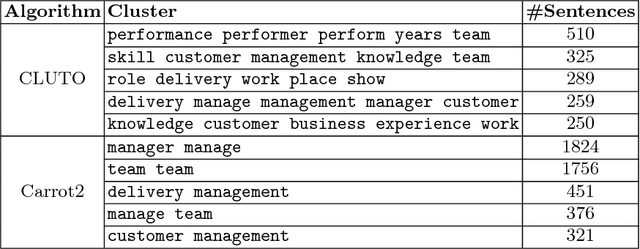
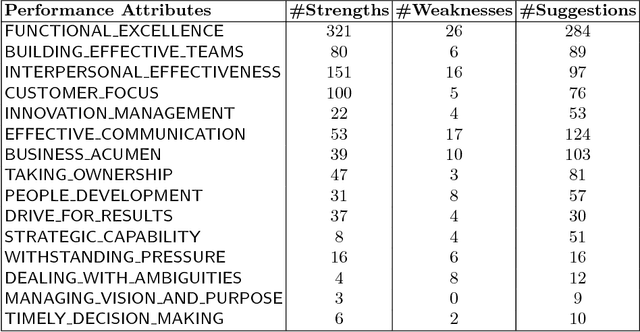
Performance appraisal (PA) is an important HR process to periodically measure and evaluate every employee's performance vis-a-vis the goals established by the organization. A PA process involves purposeful multi-step multi-modal communication between employees, their supervisors and their peers, such as self-appraisal, supervisor assessment and peer feedback. Analysis of the structured data and text produced in PA is crucial for measuring the quality of appraisals and tracking actual improvements. In this paper, we apply text mining techniques to produce insights from PA text. First, we perform sentence classification to identify strengths, weaknesses and suggestions of improvements found in the supervisor assessments and then use clustering to discover broad categories among them. Next we use multi-class multi-label classification techniques to match supervisor assessments to predefined broad perspectives on performance. Finally, we propose a short-text summarization technique to produce a summary of peer feedback comments for a given employee and compare it with manual summaries. All techniques are illustrated using a real-life dataset of supervisor assessment and peer feedback text produced during the PA of 4528 employees in a large multi-national IT company.
Topics and Label Propagation: Best of Both Worlds for Weakly Supervised Text Classification
Dec 04, 2017
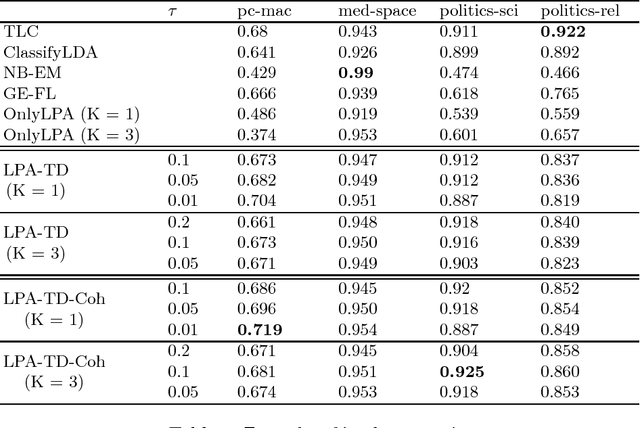


We propose a Label Propagation based algorithm for weakly supervised text classification. We construct a graph where each document is represented by a node and edge weights represent similarities among the documents. Additionally, we discover underlying topics using Latent Dirichlet Allocation (LDA) and enrich the document graph by including the topics in the form of additional nodes. The edge weights between a topic and a text document represent level of "affinity" between them. Our approach does not require document level labelling, instead it expects manual labels only for topic nodes. This significantly minimizes the level of supervision needed as only a few topics are observed to be enough for achieving sufficiently high accuracy. The Label Propagation Algorithm is employed on this enriched graph to propagate labels among the nodes. Our approach combines the advantages of Label Propagation (through document-document similarities) and Topic Modelling (for minimal but smart supervision). We demonstrate the effectiveness of our approach on various datasets and compare with state-of-the-art weakly supervised text classification approaches.
Semi-Supervised Recurrent Neural Network for Adverse Drug Reaction Mention Extraction
Sep 06, 2017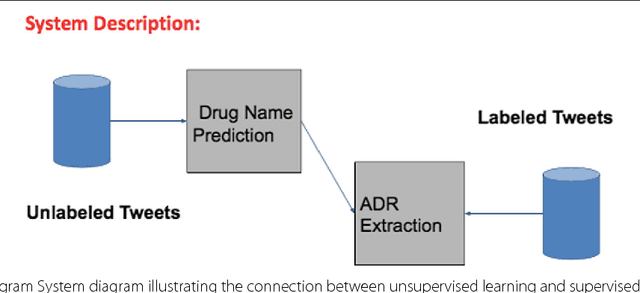


Social media is an useful platform to share health-related information due to its vast reach. This makes it a good candidate for public-health monitoring tasks, specifically for pharmacovigilance. We study the problem of extraction of Adverse-Drug-Reaction (ADR) mentions from social media, particularly from twitter. Medical information extraction from social media is challenging, mainly due to short and highly information nature of text, as compared to more technical and formal medical reports. Current methods in ADR mention extraction relies on supervised learning methods, which suffers from labeled data scarcity problem. The State-of-the-art method uses deep neural networks, specifically a class of Recurrent Neural Network (RNN) which are Long-Short-Term-Memory networks (LSTMs) \cite{hochreiter1997long}. Deep neural networks, due to their large number of free parameters relies heavily on large annotated corpora for learning the end task. But in real-world, it is hard to get large labeled data, mainly due to heavy cost associated with manual annotation. Towards this end, we propose a novel semi-supervised learning based RNN model, which can leverage unlabeled data also present in abundance on social media. Through experiments we demonstrate the effectiveness of our method, achieving state-of-the-art performance in ADR mention extraction.