 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Contextual Multi-Armed Bandit: a Real-World Application to Diagnose Apple Diseases
Feb 08, 2021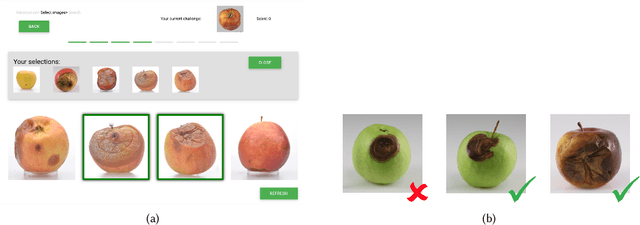
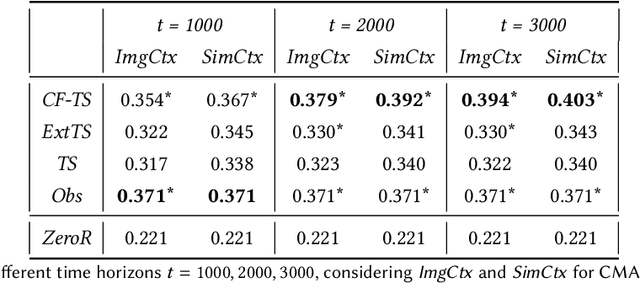
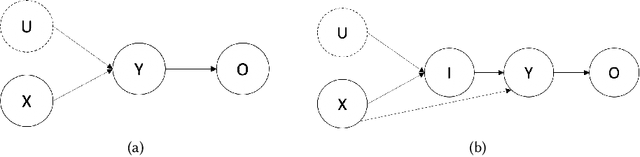
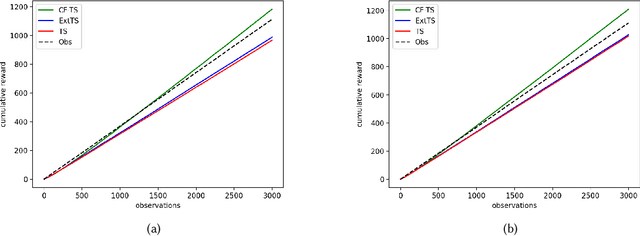
Post-harvest diseases of apple are one of the major issues in the economical sector of apple production, causing severe economical losses to producers. Thus, we developed DSSApple, a picture-based decision support system able to help users in the diagnosis of apple diseases. Specifically, this paper addresses the problem of sequentially optimizing for the best diagnosis, leveraging past interactions with the system and their contextual information (i.e. the evidence provided by the users). The problem of learning an online model while optimizing for its outcome is commonly addressed in the literature through a stochastic active learning paradigm - i.e. Contextual Multi-Armed Bandit (CMAB). This methodology interactively updates the decision model considering the success of each past interaction with respect to the context provided in each round. However, this information is very often partial and inadequate to handle such complex decision making problems. On the other hand, human decisions implicitly include unobserved factors (referred in the literature as unobserved confounders) that significantly contribute to the human's final decision. In this paper, we take advantage of the information embedded in the observed human decisions to marginalize confounding factors and improve the capability of the CMAB model to identify the correct diagnosis. Specifically, we propose a Counterfactual Contextual Multi-Armed Bandit, a model based on the causal concept of counterfactual. The proposed model is validated with offline experiments based on data collected through a large user study on the application. The results prove that our model is able to outperform both traditional CMAB algorithms and observed user decisions, in real-world tasks of predicting the correct apple disease.
Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Apr 28, 2020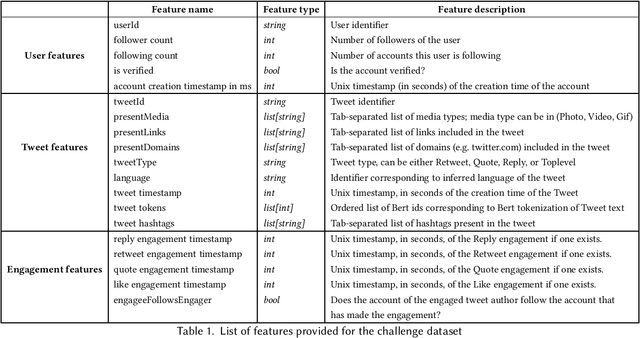
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.