 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial magic! Hermite polynomials for private data generation
Jun 09, 2021

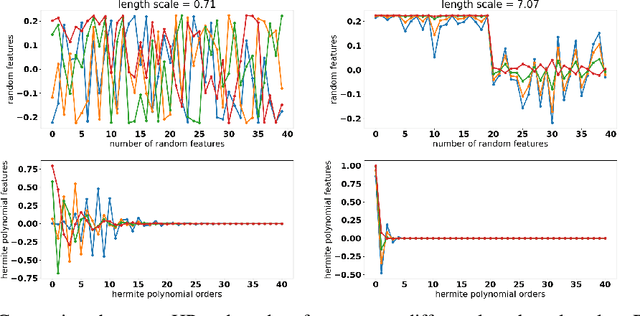

Kernel mean embedding is a useful tool to compare probability measures. Despite its usefulness, kernel mean embedding considers infinite-dimensional features, which are challenging to handle in the context of differentially private data generation. A recent work proposes to approximate the kernel mean embedding of data distribution using finite-dimensional random features, where the sensitivity of the features becomes analytically tractable. More importantly, this approach significantly reduces the privacy cost, compared to other known privatization methods (e.g., DP-SGD), as the approximate kernel mean embedding of the data distribution is privatized only once and can then be repeatedly used during training of a generator without incurring any further privacy cost. However, the required number of random features is excessively high, often ten thousand to a hundred thousand, which worsens the sensitivity of the approximate kernel mean embedding. To improve the sensitivity, we propose to replace random features with Hermite polynomial features. Unlike the random features, the Hermite polynomial features are ordered, where the features at the low orders contain more information on the distribution than those at the high orders. Hence, a relatively low order of Hermite polynomial features can more accurately approximate the mean embedding of the data distribution compared to a significantly higher number of random features. As a result, using the Hermite polynomial features, we significantly improve the privacy-accuracy trade-off, reflected in the high quality and diversity of the generated data, when tested on several heterogeneous tabular datasets, as well as several image benchmark datasets.
Q-FIT: The Quantifiable Feature Importance Technique for Explainable Machine Learning
Oct 26, 2020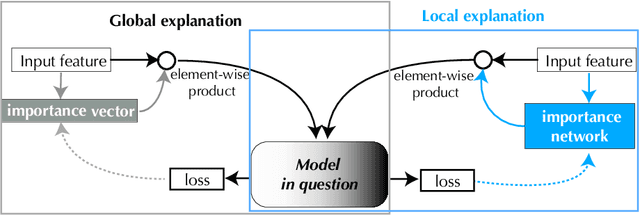
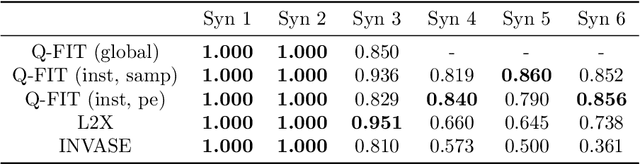
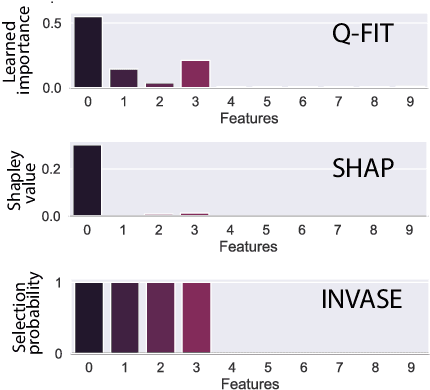

We introduce a novel framework to quantify the importance of each input feature for model explainability. A user of our framework can choose between two modes: (a) global explanation: providing feature importance globally across all the data points; and (b) local explanation: providing feature importance locally for each individual data point. The core idea of our method comes from utilizing the Dirichlet distribution to define a distribution over the importance of input features. This particular distribution is useful in ranking the importance of the input features as a sample from this distribution is a probability vector (i.e., the vector components sum to 1), Thus, the ranking uncovered by our framework which provides a \textit{quantifiable explanation} of how significant each input feature is to a model's output. This quantifiable explainability differentiates our method from existing feature-selection methods, which simply determine whether a feature is relevant or not. Furthermore, a distribution over the explanation allows to define a closed-form divergence to measure the similarity between learned feature importance under different models. We use this divergence to study how the feature importance trade-offs with essential notions in modern machine learning, such as privacy and fairness. We show the effectiveness of our method on a variety of synthetic and real datasets, taking into account both tabular and image datasets.
Differentially Private Mean Embeddings with Random Features (DP-MERF) for Simple & Practical Synthetic Data Generation
Mar 10, 2020

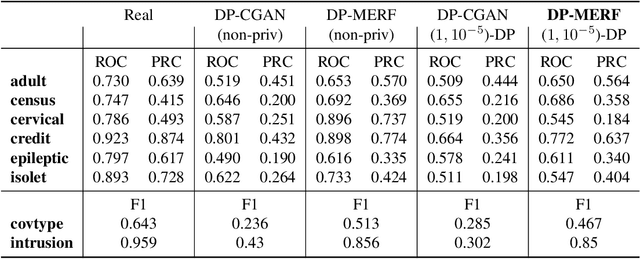

We present a differentially private data generation paradigm using random feature representations of kernel mean embeddings when comparing the distribution of true data with that of synthetic data. We exploit the random feature representations for two important benefits. First, we require a very low privacy cost for training deep generative models. This is because unlike kernel-based distance metrics that require computing the kernel matrix on all pairs of true and synthetic data points, we can detach the data-dependent term from the term solely dependent on synthetic data. Hence, we need to perturb the data-dependent term once-for-all and then use it until the end of the generator training. Second, we can obtain an analytic sensitivity of the kernel mean embedding as the random features are norm bounded by construction. This removes the necessity of hyperparameter search for a clipping norm to handle the unknown sensitivity of an encoder network when dealing with high-dimensional data. We provide several variants of our algorithm, differentially private mean embeddings with random features (DP-MERF) to generate (a) heterogeneous tabular data, (b) input features and corresponding labels jointly; and (c) high-dimensional data. Our algorithm achieves better privacy-utility trade-offs than existing methods tested on several datasets.
DP-MAC: The Differentially Private Method of Auxiliary Coordinates for Deep Learning
Oct 15, 2019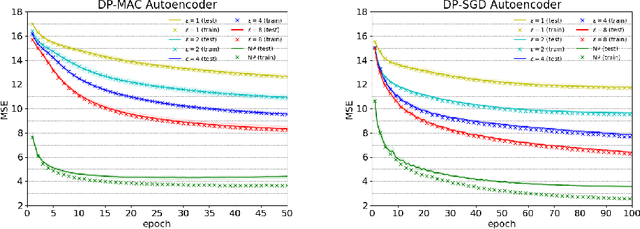
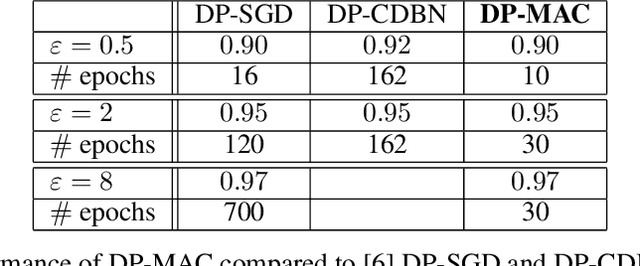
Developing a differentially private deep learning algorithm is challenging, due to the difficulty in analyzing the sensitivity of objective functions that are typically used to train deep neural networks. Many existing methods resort to the stochastic gradient descent algorithm and apply a pre-defined sensitivity to the gradients for privatizing weights. However, their slow convergence typically yields a high cumulative privacy loss. Here, we take a different route by employing the method of auxiliary coordinates, which allows us to independently update the weights per layer by optimizing a per-layer objective function. This objective function can be well approximated by a low-order Taylor's expansion, in which sensitivity analysis becomes tractable. We perturb the coefficients of the expansion for privacy, which we optimize using more advanced optimization routines than SGD for faster convergence. We empirically show that our algorithm provides a decent trained model quality under a modest privacy budget.
Interpretable and Differentially Private Predictions
Jun 05, 2019



Interpretable predictions, where it is clear why a machine learning model has made a particular decision, can compromise privacy by revealing the characteristics of individual data points. This raises the central question addressed in this paper: Can models be interpretable without compromising privacy? For complex big data fit by correspondingly rich models, balancing privacy and explainability is particularly challenging, such that this question has remained largely unexplored. In this paper, we propose a family of simple models in the aim of approximating complex models using several locally linear maps per class to provide high classification accuracy, as well as differentially private explanations on the classification. We illustrate the usefulness of our approach on several image benchmark datasets as well as a medical dataset.