 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial magic! Hermite polynomials for private data generation
Paper and Code


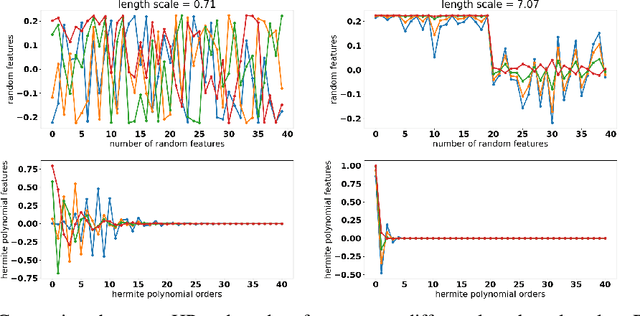

Kernel mean embedding is a useful tool to compare probability measures. Despite its usefulness, kernel mean embedding considers infinite-dimensional features, which are challenging to handle in the context of differentially private data generation. A recent work proposes to approximate the kernel mean embedding of data distribution using finite-dimensional random features, where the sensitivity of the features becomes analytically tractable. More importantly, this approach significantly reduces the privacy cost, compared to other known privatization methods (e.g., DP-SGD), as the approximate kernel mean embedding of the data distribution is privatized only once and can then be repeatedly used during training of a generator without incurring any further privacy cost. However, the required number of random features is excessively high, often ten thousand to a hundred thousand, which worsens the sensitivity of the approximate kernel mean embedding. To improve the sensitivity, we propose to replace random features with Hermite polynomial features. Unlike the random features, the Hermite polynomial features are ordered, where the features at the low orders contain more information on the distribution than those at the high orders. Hence, a relatively low order of Hermite polynomial features can more accurately approximate the mean embedding of the data distribution compared to a significantly higher number of random features. As a result, using the Hermite polynomial features, we significantly improve the privacy-accuracy trade-off, reflected in the high quality and diversity of the generated data, when tested on several heterogeneous tabular datasets, as well as several image benchmark datasets.