 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Mean Embeddings with Random Features (DP-MERF) for Simple & Practical Synthetic Data Generation
Paper and Code


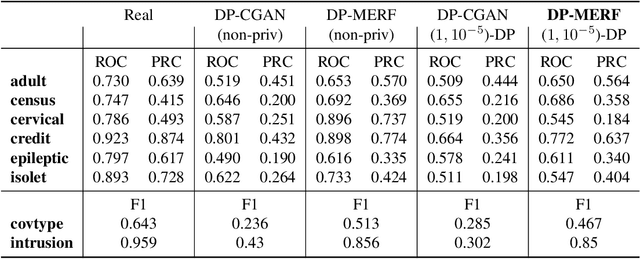

We present a differentially private data generation paradigm using random feature representations of kernel mean embeddings when comparing the distribution of true data with that of synthetic data. We exploit the random feature representations for two important benefits. First, we require a very low privacy cost for training deep generative models. This is because unlike kernel-based distance metrics that require computing the kernel matrix on all pairs of true and synthetic data points, we can detach the data-dependent term from the term solely dependent on synthetic data. Hence, we need to perturb the data-dependent term once-for-all and then use it until the end of the generator training. Second, we can obtain an analytic sensitivity of the kernel mean embedding as the random features are norm bounded by construction. This removes the necessity of hyperparameter search for a clipping norm to handle the unknown sensitivity of an encoder network when dealing with high-dimensional data. We provide several variants of our algorithm, differentially private mean embeddings with random features (DP-MERF) to generate (a) heterogeneous tabular data, (b) input features and corresponding labels jointly; and (c) high-dimensional data. Our algorithm achieves better privacy-utility trade-offs than existing methods tested on several datasets.