 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Insights and Legal Considerations for Advancing Federated Learning in Bioinformatics
Mar 12, 2025



Federated learning leverages data across institutions to improve clinical discovery while complying with data-sharing restrictions and protecting patient privacy. As the evolution of biobanks in genetics and systems biology has proved, accessing more extensive and varied data pools leads to a faster and more robust exploration and translation of results. More widespread use of federated learning may have the same impact in bioinformatics, allowing access to many combinations of genotypic, phenotypic and environmental information that are undercovered or not included in existing biobanks. This paper reviews the methodological, infrastructural and legal issues that academic and clinical institutions must address before implementing it. Finally, we provide recommendations for the reliable use of federated learning and its effective translation into clinical practice.
Intelligent tutoring systems by Bayesian nets with noisy gates
Sep 09, 2024

Directed graphical models such as Bayesian nets are often used to implement intelligent tutoring systems able to interact in real-time with learners in a purely automatic way. When coping with such models, keeping a bound on the number of parameters might be important for multiple reasons. First, as these models are typically based on expert knowledge, a huge number of parameters to elicit might discourage practitioners from adopting them. Moreover, the number of model parameters affects the complexity of the inferences, while a fast computation of the queries is needed for real-time feedback. We advocate logical gates with uncertainty for a compact parametrization of the conditional probability tables in the underlying Bayesian net used by tutoring systems. We discuss the semantics of the model parameters to elicit and the assumptions required to apply such approach in this domain. We also derive a dedicated inference scheme to speed up computations.
Rubric-based Learner Modelling via Noisy Gates Bayesian Networks for Computational Thinking Skills Assessment
Aug 02, 2024In modern and personalised education, there is a growing interest in developing learners' competencies and accurately assessing them. In a previous work, we proposed a procedure for deriving a learner model for automatic skill assessment from a task-specific competence rubric, thus simplifying the implementation of automated assessment tools. The previous approach, however, suffered two main limitations: (i) the ordering between competencies defined by the assessment rubric was only indirectly modelled; (ii) supplementary skills, not under assessment but necessary for accomplishing the task, were not included in the model. In this work, we address issue (i) by introducing dummy observed nodes, strictly enforcing the skills ordering without changing the network's structure. In contrast, for point (ii), we design a network with two layers of gates, one performing disjunctive operations by noisy-OR gates and the other conjunctive operations through logical ANDs. Such changes improve the model outcomes' coherence and the modelling tool's flexibility without compromising the model's compact parametrisation, interpretability and simple experts' elicitation. We used this approach to develop a learner model for Computational Thinking (CT) skills assessment. The CT-cube skills assessment framework and the Cross Array Task (CAT) are used to exemplify it and demonstrate its feasibility.
Modelling Assessment Rubrics through Bayesian Networks: a Pragmatic Approach
Sep 07, 2022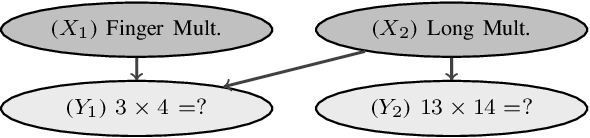



Automatic assessment of learner competencies is a fundamental task in intelligent tutoring systems. An assessment rubric typically and effectively describes relevant competencies and competence levels. This paper presents an approach to deriving a learner model directly from an assessment rubric defining some (partial) ordering of competence levels. The model is based on Bayesian networks and exploits logical gates with uncertainty (often referred to as noisy gates) to reduce the number of parameters of the model, so to simplify their elicitation by experts and allow real-time inference in intelligent tutoring systems. We illustrate how the approach can be applied to automatize the human assessment of an activity developed for testing computational thinking skills. The simple elicitation of the model starting from the assessment rubric opens up the possibility of quickly automating the assessment of several tasks, making them more easily exploitable in the context of adaptive assessment tools and intelligent tutoring systems.
ADAPQUEST: A Software for Web-Based Adaptive Questionnaires based on Bayesian Networks
Dec 29, 2021
We introduce ADAPQUEST, a software tool written in Java for the development of adaptive questionnaires based on Bayesian networks. Adaptiveness is intended here as the dynamical choice of the question sequence on the basis of an evolving model of the skill level of the test taker. Bayesian networks offer a flexible and highly interpretable framework to describe such testing process, especially when coping with multiple skills. ADAPQUEST embeds dedicated elicitation strategies to simplify the elicitation of the questionnaire parameters. An application of this tool for the diagnosis of mental disorders is also discussed together with some implementation details.
A New Score for Adaptive Tests in Bayesian and Credal Networks
May 25, 2021

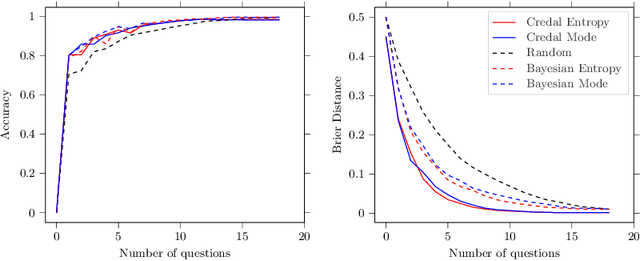
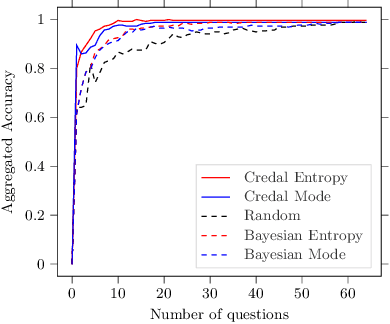
A test is adaptive when its sequence and number of questions is dynamically tuned on the basis of the estimated skills of the taker. Graphical models, such as Bayesian networks, are used for adaptive tests as they allow to model the uncertainty about the questions and the skills in an explainable fashion, especially when coping with multiple skills. A better elicitation of the uncertainty in the question/skills relations can be achieved by interval probabilities. This turns the model into a credal network, thus making more challenging the inferential complexity of the queries required to select questions. This is especially the case for the information theoretic quantities used as scores to drive the adaptive mechanism. We present an alternative family of scores, based on the mode of the posterior probabilities, and hence easier to explain. This makes considerably simpler the evaluation in the credal case, without significantly affecting the quality of the adaptive process. Numerical tests on synthetic and real-world data are used to support this claim.
A Bayesian Approach to Conversational Recommendation Systems
Feb 12, 2020
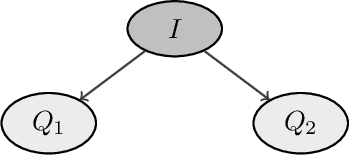

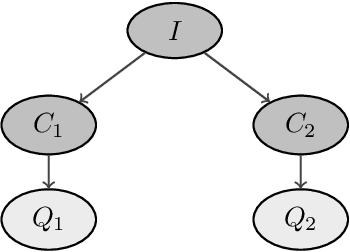
We present a conversational recommendation system based on a Bayesian approach. A probability mass function over the items is updated after any interaction with the user, with information-theoretic criteria optimally shaping the interaction and deciding when the conversation should be terminated and the most probable item consequently recommended. Dedicated elicitation techniques for the prior probabilities of the parameters modeling the interactions are derived from basic structural judgements. Such prior information can be combined with historical data to discriminate items with different recommendation histories. A case study based on the application of this approach to \emph{stagend.com}, an online platform for booking entertainers, is finally discussed together with an empirical analysis showing the advantages in terms of recommendation quality and efficiency.
Statistical comparison of classifiers through Bayesian hierarchical modelling
Nov 22, 2016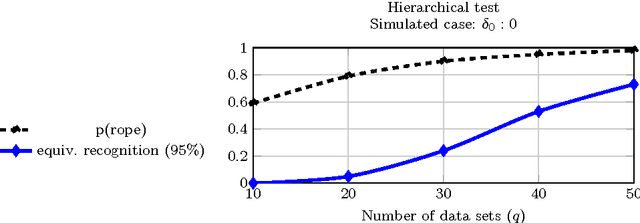


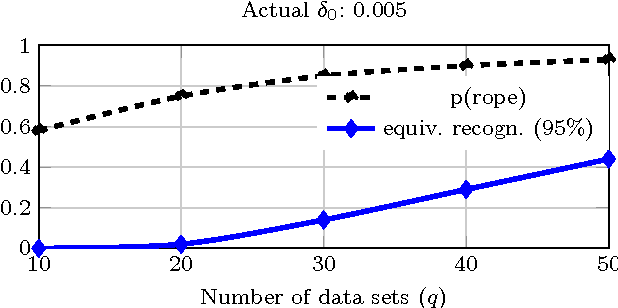
Usually one compares the accuracy of two competing classifiers via null hypothesis significance tests (nhst). Yet the nhst tests suffer from important shortcomings, which can be overcome by switching to Bayesian hypothesis testing. We propose a Bayesian hierarchical model which jointly analyzes the cross-validation results obtained by two classifiers on multiple data sets. It returns the posterior probability of the accuracies of the two classifiers being practically equivalent or significantly different. A further strength of the hierarchical model is that, by jointly analyzing the results obtained on all data sets, it reduces the estimation error compared to the usual approach of averaging the cross-validation results obtained on a given data set.
Should we really use post-hoc tests based on mean-ranks?
May 09, 2015
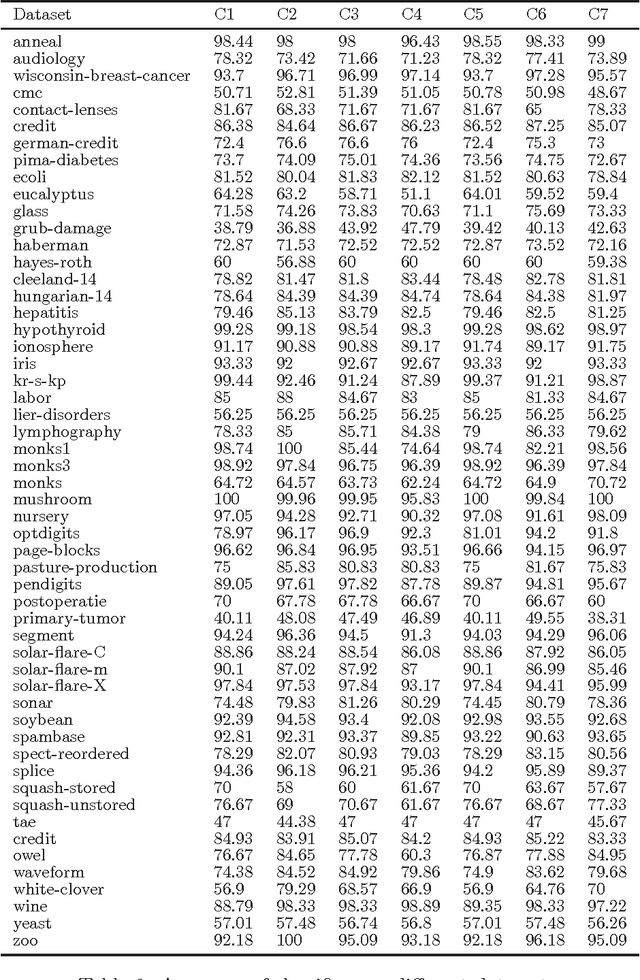
The statistical comparison of multiple algorithms over multiple data sets is fundamental in machine learning. This is typically carried out by the Friedman test. When the Friedman test rejects the null hypothesis, multiple comparisons are carried out to establish which are the significant differences among algorithms. The multiple comparisons are usually performed using the mean-ranks test. The aim of this technical note is to discuss the inconsistencies of the mean-ranks post-hoc test with the goal of discouraging its use in machine learning as well as in medicine, psychology, etc.. We show that the outcome of the mean-ranks test depends on the pool of algorithms originally included in the experiment. In other words, the outcome of the comparison between algorithms A and B depends also on the performance of the other algorithms included in the original experiment. This can lead to paradoxical situations. For instance the difference between A and B could be declared significant if the pool comprises algorithms C, D, E and not significant if the pool comprises algorithms F, G, H. To overcome these issues, we suggest instead to perform the multiple comparison using a test whose outcome only depends on the two algorithms being compared, such as the sign-test or the Wilcoxon signed-rank test.