 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould we really use post-hoc tests based on mean-ranks?
Paper and Code
May 09, 2015
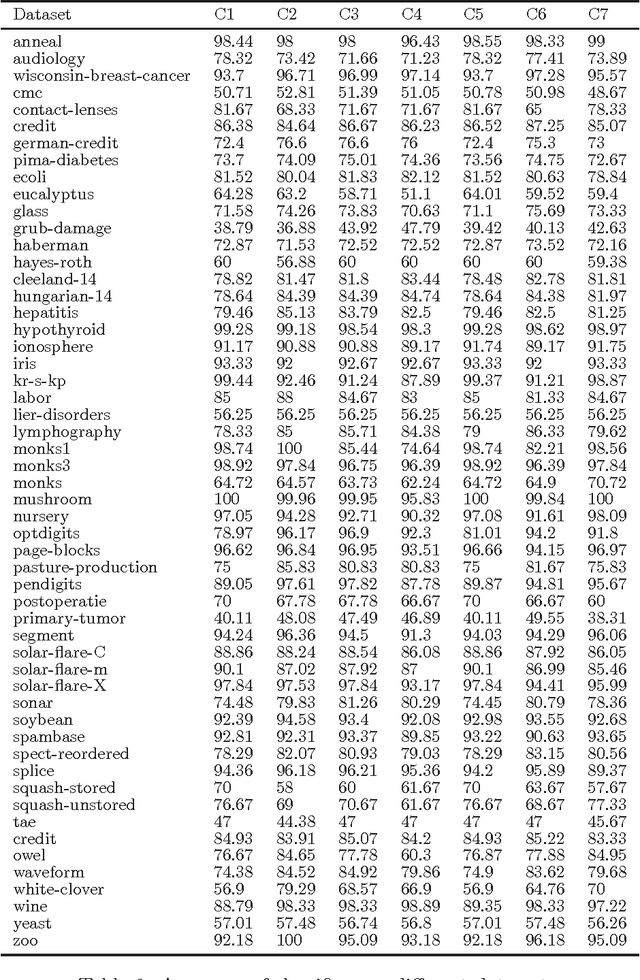
The statistical comparison of multiple algorithms over multiple data sets is fundamental in machine learning. This is typically carried out by the Friedman test. When the Friedman test rejects the null hypothesis, multiple comparisons are carried out to establish which are the significant differences among algorithms. The multiple comparisons are usually performed using the mean-ranks test. The aim of this technical note is to discuss the inconsistencies of the mean-ranks post-hoc test with the goal of discouraging its use in machine learning as well as in medicine, psychology, etc.. We show that the outcome of the mean-ranks test depends on the pool of algorithms originally included in the experiment. In other words, the outcome of the comparison between algorithms A and B depends also on the performance of the other algorithms included in the original experiment. This can lead to paradoxical situations. For instance the difference between A and B could be declared significant if the pool comprises algorithms C, D, E and not significant if the pool comprises algorithms F, G, H. To overcome these issues, we suggest instead to perform the multiple comparison using a test whose outcome only depends on the two algorithms being compared, such as the sign-test or the Wilcoxon signed-rank test.