 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an intelligent assessment system for evaluating the development of algorithmic thinking skills: An exploratory study in Swiss compulsory schools
Mar 27, 2025The rapid digitalisation of contemporary society has profoundly impacted various facets of our lives, including healthcare, communication, business, and education. The ability to engage with new technologies and solve problems has become crucial, making CT skills, such as pattern recognition, decomposition, and algorithm design, essential competencies. In response, Switzerland is conducting research and initiatives to integrate CT into its educational system. This study aims to develop a comprehensive framework for large-scale assessment of CT skills, particularly focusing on AT, the ability to design algorithms. To achieve this, we first developed a competence model capturing the situated and developmental nature of CT, guiding the design of activities tailored to cognitive abilities, age, and context. This framework clarifies how activity characteristics influence CT development and how to assess these competencies. Additionally, we developed an activity for large-scale assessment of AT skills, offered in two variants: one based on non-digital artefacts (unplugged) and manual expert assessment, and the other based on digital artefacts (virtual) and automatic assessment. To provide a more comprehensive evaluation of students' competencies, we developed an IAS based on BNs with noisy gates, which offers real-time probabilistic assessment for each skill rather than a single overall score. The results indicate that the proposed instrument can measure AT competencies across different age groups and educational contexts in Switzerland, demonstrating its applicability for large-scale use. AT competencies exhibit a progressive development, with no overall gender differences, though variations are observed at the school level, significantly influenced by the artefact-based environment and its context, underscoring the importance of creating accessible and adaptable assessment tools.
Intelligent tutoring systems by Bayesian nets with noisy gates
Sep 09, 2024

Directed graphical models such as Bayesian nets are often used to implement intelligent tutoring systems able to interact in real-time with learners in a purely automatic way. When coping with such models, keeping a bound on the number of parameters might be important for multiple reasons. First, as these models are typically based on expert knowledge, a huge number of parameters to elicit might discourage practitioners from adopting them. Moreover, the number of model parameters affects the complexity of the inferences, while a fast computation of the queries is needed for real-time feedback. We advocate logical gates with uncertainty for a compact parametrization of the conditional probability tables in the underlying Bayesian net used by tutoring systems. We discuss the semantics of the model parameters to elicit and the assumptions required to apply such approach in this domain. We also derive a dedicated inference scheme to speed up computations.
The virtual CAT: A tool for algorithmic thinking assessment in Swiss compulsory education
Aug 02, 2024In today's digital era, holding algorithmic thinking (AT) skills is crucial, not only in computer science-related fields. These abilities enable individuals to break down complex problems into more manageable steps and create a sequence of actions to solve them. To address the increasing demand for AT assessments in educational settings and the limitations of current methods, this paper introduces the virtual Cross Array Task (CAT), a digital adaptation of an unplugged assessment activity designed to evaluate algorithmic skills in Swiss compulsory education. This tool offers scalable and automated assessment, reducing human involvement and mitigating potential data collection errors. The platform features gesture-based and visual block-based programming interfaces, ensuring its usability for diverse learners, further supported by multilingual capabilities. To evaluate the virtual CAT platform, we conducted a pilot evaluation in Switzerland involving a heterogeneous group of students. The findings show the platform's usability, proficiency and suitability for assessing AT skills among students of diverse ages, development stages, and educational backgrounds, as well as the feasibility of large-scale data collection.
Rubric-based Learner Modelling via Noisy Gates Bayesian Networks for Computational Thinking Skills Assessment
Aug 02, 2024In modern and personalised education, there is a growing interest in developing learners' competencies and accurately assessing them. In a previous work, we proposed a procedure for deriving a learner model for automatic skill assessment from a task-specific competence rubric, thus simplifying the implementation of automated assessment tools. The previous approach, however, suffered two main limitations: (i) the ordering between competencies defined by the assessment rubric was only indirectly modelled; (ii) supplementary skills, not under assessment but necessary for accomplishing the task, were not included in the model. In this work, we address issue (i) by introducing dummy observed nodes, strictly enforcing the skills ordering without changing the network's structure. In contrast, for point (ii), we design a network with two layers of gates, one performing disjunctive operations by noisy-OR gates and the other conjunctive operations through logical ANDs. Such changes improve the model outcomes' coherence and the modelling tool's flexibility without compromising the model's compact parametrisation, interpretability and simple experts' elicitation. We used this approach to develop a learner model for Computational Thinking (CT) skills assessment. The CT-cube skills assessment framework and the Cross Array Task (CAT) are used to exemplify it and demonstrate its feasibility.
Investigating GANsformer: A Replication Study of a State-of-the-Art Image Generation Model
Mar 15, 2023The field of image generation through generative modelling is abundantly discussed nowadays. It can be used for various applications, such as up-scaling existing images, creating non-existing objects, such as interior design scenes, products or even human faces, and achieving transfer-learning processes. In this context, Generative Adversarial Networks (GANs) are a class of widely studied machine learning frameworks first appearing in the paper "Generative adversarial nets" by Goodfellow et al. that achieve the goal above. In our work, we reproduce and evaluate a novel variation of the original GAN network, the GANformer, proposed in "Generative Adversarial Transformers" by Hudson and Zitnick. This project aimed to recreate the methods presented in this paper to reproduce the original results and comment on the authors' claims. Due to resources and time limitations, we had to constrain the network's training times, dataset types, and sizes. Our research successfully recreated both variations of the proposed GANformer model and found differences between the authors' and our results. Moreover, discrepancies between the publication methodology and the one implemented, made available in the code, allowed us to study two undisclosed variations of the presented procedures.
Simulation of robot swarms for learning communication-aware coordination
Feb 25, 2023


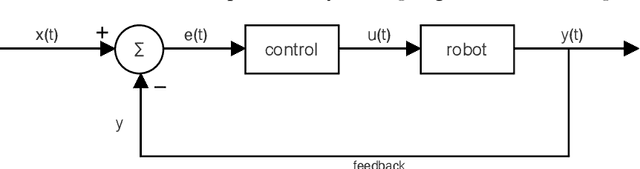
Robotics research has been focusing on cooperative multi-agent problems, where agents must work together and communicate to achieve a shared objective. To tackle this challenge, we explore imitation learning algorithms. These methods learn a controller by observing demonstrations of an expert, such as the behaviour of a centralised omniscient controller, which can perceive the entire environment, including the state and observations of all agents. Performing tasks with complete knowledge of the state of a system is relatively easy, but centralised solutions might not be feasible in real scenarios since agents do not have direct access to the state but only to their observations. To overcome this issue, we train end-to-end Neural Networks that take as input local observations obtained from an omniscient centralised controller, i.e., the agents' sensor readings and the communications received, producing as output the action to be performed and the communication to be transmitted. This study concentrates on two cooperative tasks using a distributed controller: distributing the robots evenly in space and colouring them based on their position relative to others. While an explicit exchange of messages between the agents is required to solve the second task, in the first one, a communication protocol is unnecessary, although it may increase performance. The experiments are run in Enki, a high-performance open-source simulator for planar robots, which provides collision detection and limited physics support for robots evolving on a flat surface. Moreover, it can simulate groups of robots hundreds of times faster than real-time. The results show how applying a communication strategy improves the performance of the distributed model, letting it decide which actions to take almost as precisely and quickly as the expert controller.
Neural networks for learning personality traits from natural language
Feb 23, 2023Personality is considered one of the most influential research topics in psychology, as it predicts many consequential outcomes such as mental and physical health and explains human behaviour. With the widespread use of social networks as a means of communication, it is becoming increasingly important to develop models that can automatically and accurately read the essence of individuals based solely on their writing. In particular, the convergence of social and computer sciences has led researchers to develop automatic approaches for extracting and studying "hidden" information in textual data on the internet. The nature of this thesis project is highly experimental, and the motivation behind this work is to present detailed analyses on the topic, as currently there are no significant investigations of this kind. The objective is to identify an adequate semantic space that allows for defining the personality of the object to which a certain text refers. The starting point is a dictionary of adjectives that psychological literature defines as markers of the five major personality traits, or Big Five. In this work, we started with the implementation of fully-connected neural networks as a basis for understanding how simple deep learning models can provide information on hidden personality characteristics. Finally, we use a class of distributional algorithms invented in 2013 by Tomas Mikolov, which consists of using a convolutional neural network that learns the contexts of words in an unsupervised way. In this way, we construct an embedding that contains the semantic information on the text, obtaining a kind of "geometry of meaning" in which concepts are translated into linear relationships. With this last experiment, we hypothesize that an individual writing style is largely coupled with their personality traits.
Modelling Assessment Rubrics through Bayesian Networks: a Pragmatic Approach
Sep 07, 2022



Automatic assessment of learner competencies is a fundamental task in intelligent tutoring systems. An assessment rubric typically and effectively describes relevant competencies and competence levels. This paper presents an approach to deriving a learner model directly from an assessment rubric defining some (partial) ordering of competence levels. The model is based on Bayesian networks and exploits logical gates with uncertainty (often referred to as noisy gates) to reduce the number of parameters of the model, so to simplify their elicitation by experts and allow real-time inference in intelligent tutoring systems. We illustrate how the approach can be applied to automatize the human assessment of an activity developed for testing computational thinking skills. The simple elicitation of the model starting from the assessment rubric opens up the possibility of quickly automating the assessment of several tasks, making them more easily exploitable in the context of adaptive assessment tools and intelligent tutoring systems.
Learning Relative Interactions through Imitation
Sep 24, 2021
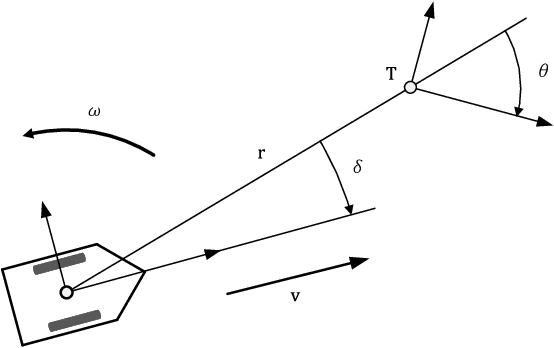
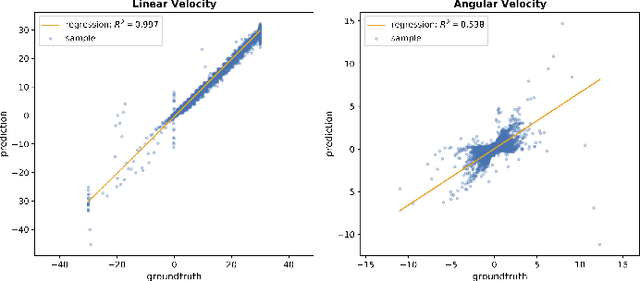

In this project we trained a neural network to perform specific interactions between a robot and objects in the environment, through imitation learning. In particular, we tackle the task of moving the robot to a fixed pose with respect to a certain object and later extend our method to handle any arbitrary pose around this object. We show that a simple network, with relatively little training data, is able to reach very good performance on the fixed-pose task, while more work is needed to perform the arbitrary-pose task satisfactorily. We also explore the effect of ambiguities in the sensor readings, in particular caused by symmetries in the target object, on the behaviour of the learned controller.
A New Score for Adaptive Tests in Bayesian and Credal Networks
May 25, 2021

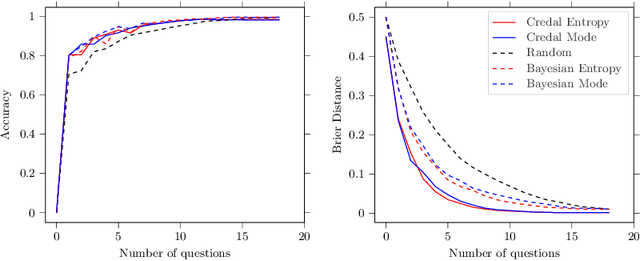
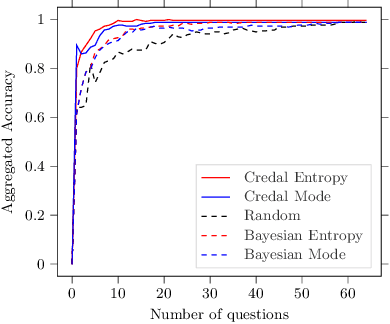
A test is adaptive when its sequence and number of questions is dynamically tuned on the basis of the estimated skills of the taker. Graphical models, such as Bayesian networks, are used for adaptive tests as they allow to model the uncertainty about the questions and the skills in an explainable fashion, especially when coping with multiple skills. A better elicitation of the uncertainty in the question/skills relations can be achieved by interval probabilities. This turns the model into a credal network, thus making more challenging the inferential complexity of the queries required to select questions. This is especially the case for the information theoretic quantities used as scores to drive the adaptive mechanism. We present an alternative family of scores, based on the mode of the posterior probabilities, and hence easier to explain. This makes considerably simpler the evaluation in the credal case, without significantly affecting the quality of the adaptive process. Numerical tests on synthetic and real-world data are used to support this claim.