 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubric-based Learner Modelling via Noisy Gates Bayesian Networks for Computational Thinking Skills Assessment
Aug 02, 2024In modern and personalised education, there is a growing interest in developing learners' competencies and accurately assessing them. In a previous work, we proposed a procedure for deriving a learner model for automatic skill assessment from a task-specific competence rubric, thus simplifying the implementation of automated assessment tools. The previous approach, however, suffered two main limitations: (i) the ordering between competencies defined by the assessment rubric was only indirectly modelled; (ii) supplementary skills, not under assessment but necessary for accomplishing the task, were not included in the model. In this work, we address issue (i) by introducing dummy observed nodes, strictly enforcing the skills ordering without changing the network's structure. In contrast, for point (ii), we design a network with two layers of gates, one performing disjunctive operations by noisy-OR gates and the other conjunctive operations through logical ANDs. Such changes improve the model outcomes' coherence and the modelling tool's flexibility without compromising the model's compact parametrisation, interpretability and simple experts' elicitation. We used this approach to develop a learner model for Computational Thinking (CT) skills assessment. The CT-cube skills assessment framework and the Cross Array Task (CAT) are used to exemplify it and demonstrate its feasibility.
The virtual CAT: A tool for algorithmic thinking assessment in Swiss compulsory education
Aug 02, 2024In today's digital era, holding algorithmic thinking (AT) skills is crucial, not only in computer science-related fields. These abilities enable individuals to break down complex problems into more manageable steps and create a sequence of actions to solve them. To address the increasing demand for AT assessments in educational settings and the limitations of current methods, this paper introduces the virtual Cross Array Task (CAT), a digital adaptation of an unplugged assessment activity designed to evaluate algorithmic skills in Swiss compulsory education. This tool offers scalable and automated assessment, reducing human involvement and mitigating potential data collection errors. The platform features gesture-based and visual block-based programming interfaces, ensuring its usability for diverse learners, further supported by multilingual capabilities. To evaluate the virtual CAT platform, we conducted a pilot evaluation in Switzerland involving a heterogeneous group of students. The findings show the platform's usability, proficiency and suitability for assessing AT skills among students of diverse ages, development stages, and educational backgrounds, as well as the feasibility of large-scale data collection.
Modelling Assessment Rubrics through Bayesian Networks: a Pragmatic Approach
Sep 07, 2022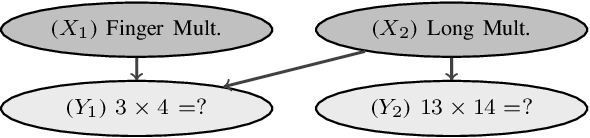



Automatic assessment of learner competencies is a fundamental task in intelligent tutoring systems. An assessment rubric typically and effectively describes relevant competencies and competence levels. This paper presents an approach to deriving a learner model directly from an assessment rubric defining some (partial) ordering of competence levels. The model is based on Bayesian networks and exploits logical gates with uncertainty (often referred to as noisy gates) to reduce the number of parameters of the model, so to simplify their elicitation by experts and allow real-time inference in intelligent tutoring systems. We illustrate how the approach can be applied to automatize the human assessment of an activity developed for testing computational thinking skills. The simple elicitation of the model starting from the assessment rubric opens up the possibility of quickly automating the assessment of several tasks, making them more easily exploitable in the context of adaptive assessment tools and intelligent tutoring systems.
Limits of Learning about a Categorical Latent Variable under Prior Near-Ignorance
Apr 29, 2009In this paper, we consider the coherent theory of (epistemic) uncertainty of Walley, in which beliefs are represented through sets of probability distributions, and we focus on the problem of modeling prior ignorance about a categorical random variable. In this setting, it is a known result that a state of prior ignorance is not compatible with learning. To overcome this problem, another state of beliefs, called \emph{near-ignorance}, has been proposed. Near-ignorance resembles ignorance very closely, by satisfying some principles that can arguably be regarded as necessary in a state of ignorance, and allows learning to take place. What this paper does, is to provide new and substantial evidence that also near-ignorance cannot be really regarded as a way out of the problem of starting statistical inference in conditions of very weak beliefs. The key to this result is focusing on a setting characterized by a variable of interest that is \emph{latent}. We argue that such a setting is by far the most common case in practice, and we provide, for the case of categorical latent variables (and general \emph{manifest} variables) a condition that, if satisfied, prevents learning to take place under prior near-ignorance. This condition is shown to be easily satisfied even in the most common statistical problems. We regard these results as a strong form of evidence against the possibility to adopt a condition of prior near-ignorance in real statistical problems.
* 27 LaTeX pages