 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023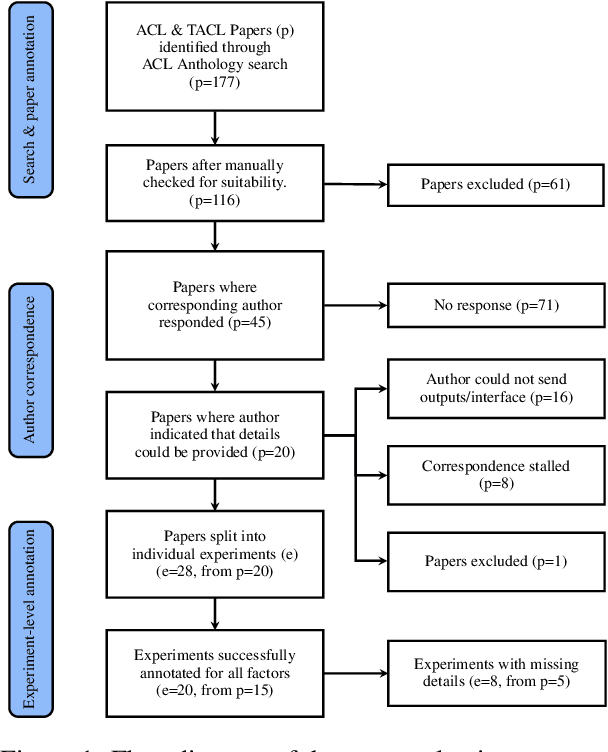
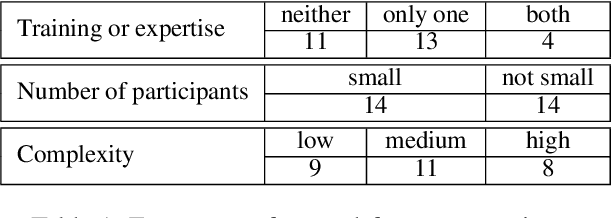


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Semantic Relatedness and Taxonomic Word Embeddings
Feb 14, 2020
This paper connects a series of papers dealing with taxonomic word embeddings. It begins by noting that there are different types of semantic relatedness and that different lexical representations encode different forms of relatedness. A particularly important distinction within semantic relatedness is that of thematic versus taxonomic relatedness. Next, we present a number of experiments that analyse taxonomic embeddings that have been trained on a synthetic corpus that has been generated via a random walk over a taxonomy. These experiments demonstrate how the properties of the synthetic corpus, such as the percentage of rare words, are affected by the shape of the knowledge graph the corpus is generated from. Finally, we explore the interactions between the relative sizes of natural and synthetic corpora on the performance of embeddings when taxonomic and thematic embeddings are combined.