 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Constrained Optimization in Differentiable Neural Architecture Search
Jul 03, 2021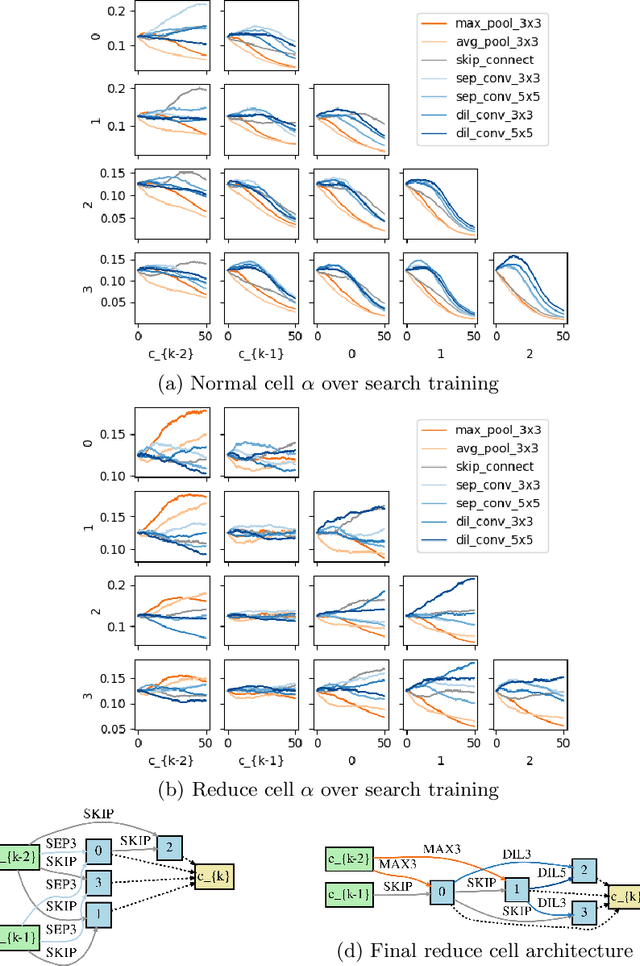
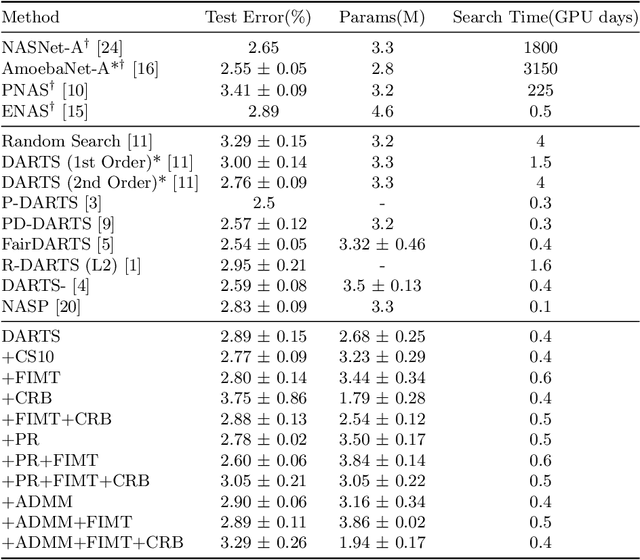
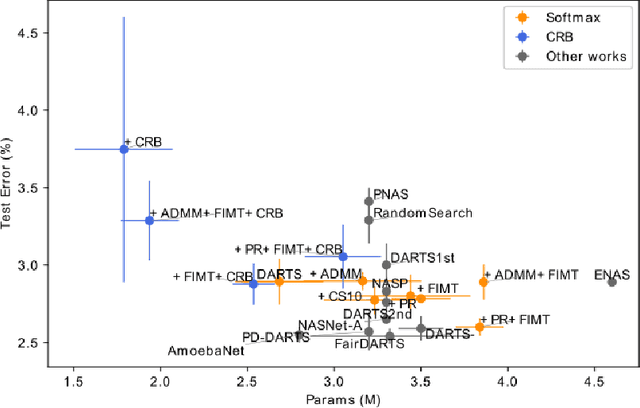
Differentiable Architecture Search (DARTS) is a recently proposed neural architecture search (NAS) method based on a differentiable relaxation. Due to its success, numerous variants analyzing and improving parts of the DARTS framework have recently been proposed. By considering the problem as a constrained bilevel optimization, we propose and analyze three improvements to architectural weight competition, update scheduling, and regularization towards discretization. First, we introduce a new approach to the activation of architecture weights, which prevents confounding competition within an edge and allows for fair comparison across edges to aid in discretization. Next, we propose a dynamic schedule based on per-minibatch network information to make architecture updates more informed. Finally, we consider two regularizations, based on proximity to discretization and the Alternating Directions Method of Multipliers (ADMM) algorithm, to promote early discretization. Our results show that this new activation scheme reduces final architecture size and the regularizations improve reliability in search results while maintaining comparable performance to state-of-the-art in NAS, especially when used with our new dynamic informed schedule.
Lipschitz Lifelong Reinforcement Learning
Jan 17, 2020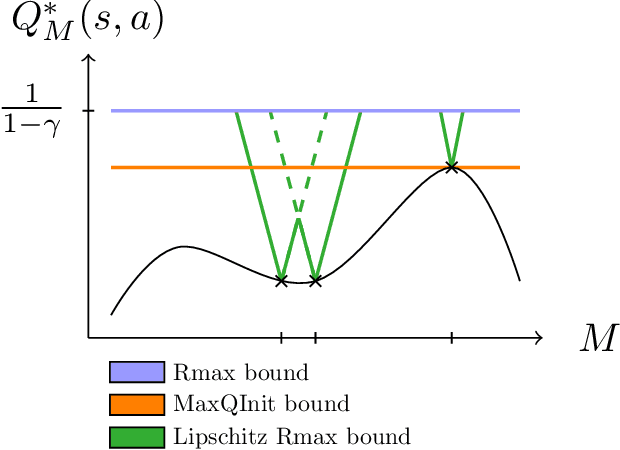
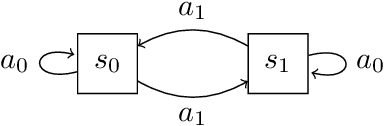
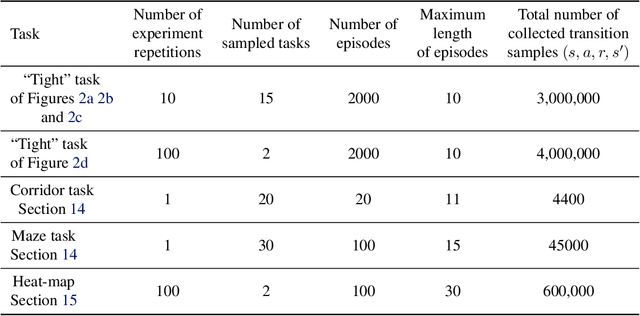
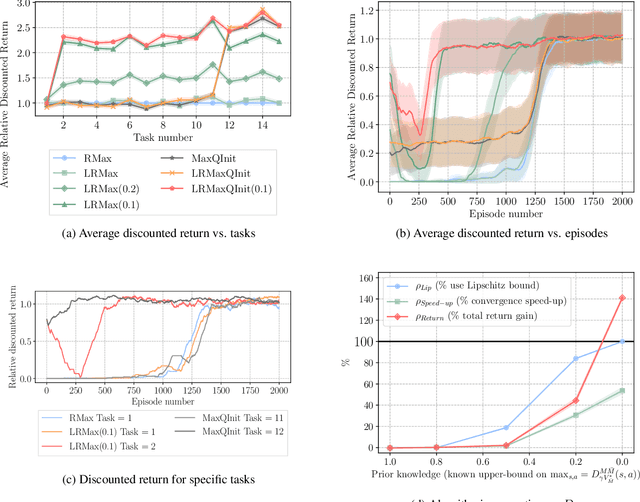
We consider the problem of knowledge transfer when an agent is facing a series of Reinforcement Learning (RL) tasks. We introduce a novel metric between Markov Decision Processes and establish that close MDPs have close optimal value functions. Formally, the optimal value functions are Lipschitz continuous with respect to the tasks space. These theoretical results lead us to a value transfer method for Lifelong RL, which we use to build a PAC-MDP algorithm with improved convergence rate. We illustrate the benefits of the method in Lifelong RL experiments.
Non-Stationary Markov Decision Processes, a Worst-Case Approach using Model-Based Reinforcement Learning, Extended version
May 24, 2019
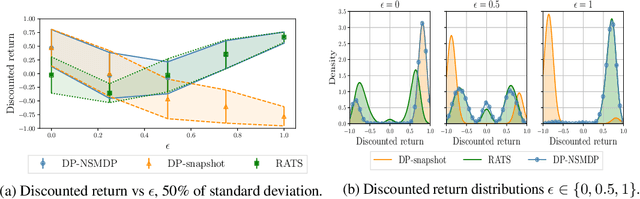
This work tackles the problem of robust zero-shot planning in non-stationary stochastic environments. We study Markov Decision Processes (MDPs) evolving over time and consider Model-Based Reinforcement Learning algorithms in this setting. We make two hypotheses: 1) the environment evolves continuously with a bounded evolution rate; 2) a current model is known at each decision epoch but not its evolution. Our contribution can be presented in four points. 1) we define a specific class of MDPs that we call Non-Stationary MDPs (NSMDPs). We introduce the notion of regular evolution by making an hypothesis of Lipschitz-Continuity on the transition and reward functions w.r.t. time; 2) we consider a planning agent using the current model of the environment but unaware of its future evolution. This leads us to consider a worst-case method where the environment is seen as an adversarial agent; 3) following this approach, we propose the Risk-Averse Tree-Search (RATS) algorithm, a zero-shot Model-Based method similar to Minimax search; 4) we illustrate the benefits brought by RATS empirically and compare its performance with reference Model-Based algorithms.
Open Loop Execution of Tree-Search Algorithms
May 03, 2018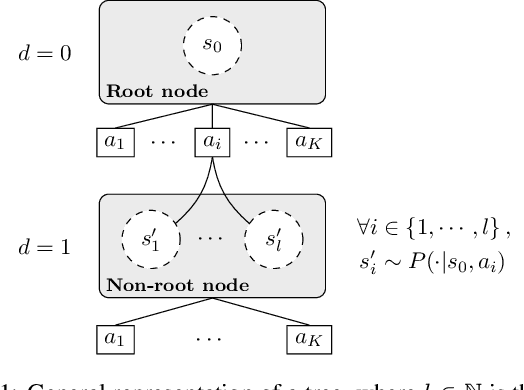
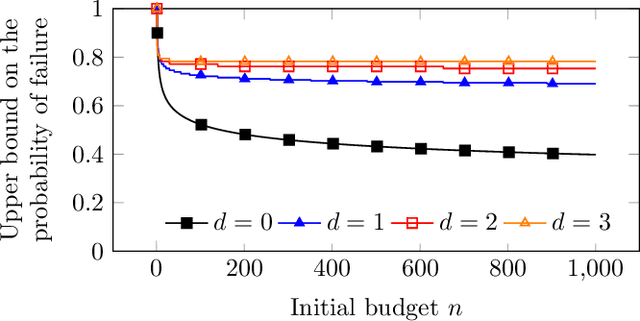
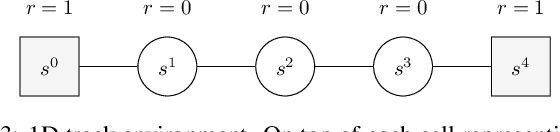
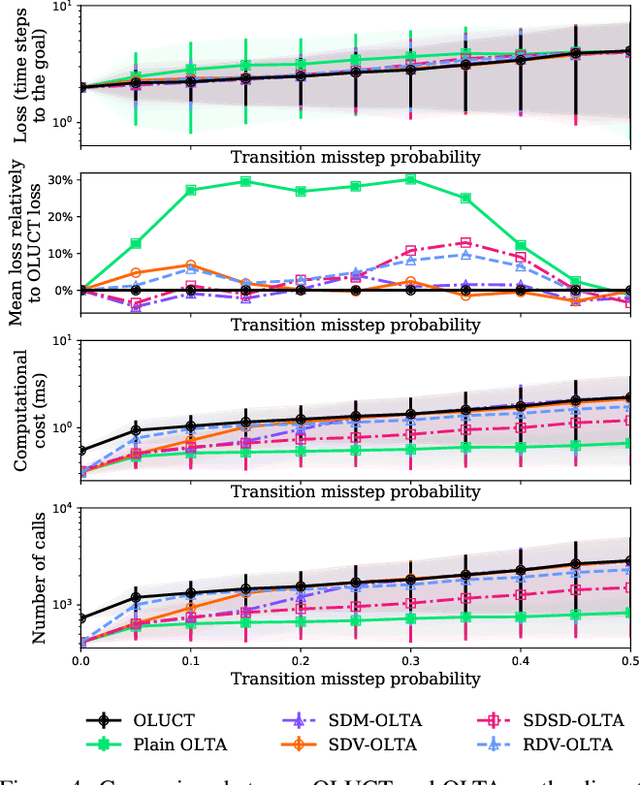
In the context of tree-search stochastic planning algorithms where a generative model is available, we consider on-line planning algorithms building trees in order to recommend an action. We investigate the question of avoiding re-planning in subsequent decision steps by directly using sub-trees as action recommender. Firstly, we propose a method for open loop control via a new algorithm taking the decision of re-planning or not at each time step based on an analysis of the statistics of the sub-tree. Secondly, we show that the probability of selecting a suboptimal action at any depth of the tree can be upper bounded and converges towards zero. Moreover, this upper bound decays in a logarithmic way between subsequent depths. This leads to a distinction between node-wise optimality and state-wise optimality. Finally, we empirically demonstrate that our method achieves a compromise between loss of performance and computational gain.
Empirical evaluation of a Q-Learning Algorithm for Model-free Autonomous Soaring
Jul 18, 2017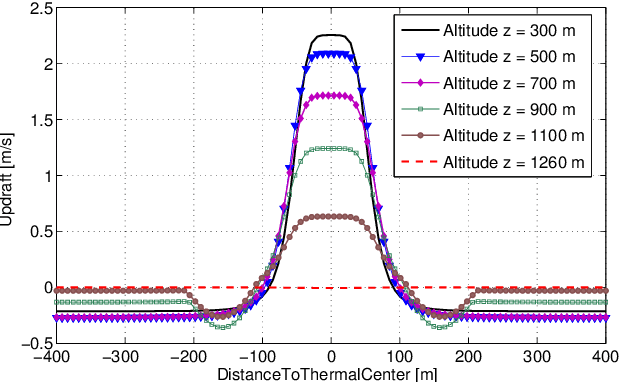
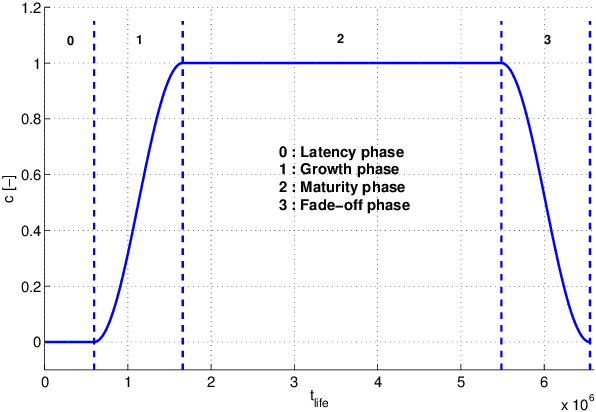

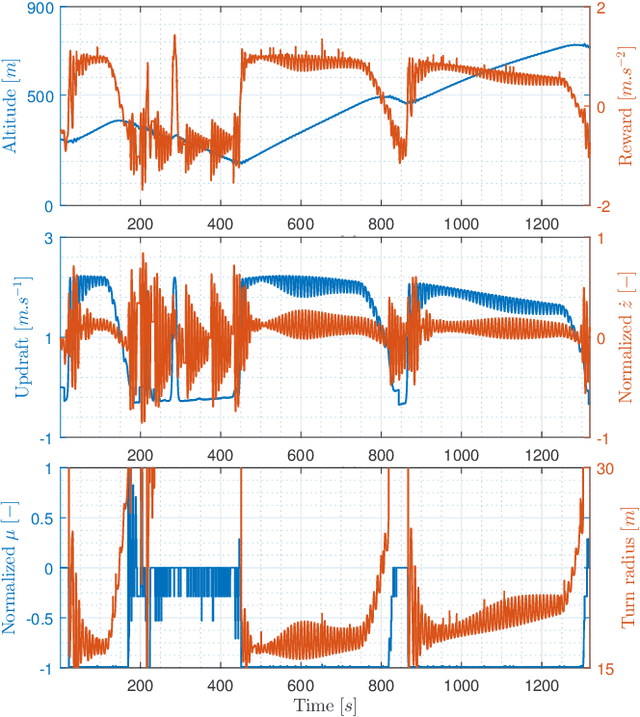
Autonomous unpowered flight is a challenge for control and guidance systems: all the energy the aircraft might use during flight has to be harvested directly from the atmosphere. We investigate the design of an algorithm that optimizes the closed-loop control of a glider's bank and sideslip angles, while flying in the lower convective layer of the atmosphere in order to increase its mission endurance. Using a Reinforcement Learning approach, we demonstrate the possibility for real-time adaptation of the glider's behaviour to the time-varying and noisy conditions associated with thermal soaring flight. Our approach is online, data-based and model-free, hence avoids the pitfalls of aerological and aircraft modelling and allow us to deal with uncertainties and non-stationarity. Additionally, we put a particular emphasis on keeping low computational requirements in order to make on-board execution feasible. This article presents the stochastic, time-dependent aerological model used for simulation, together with a standard aircraft model. Then we introduce an adaptation of a Q-learning algorithm and demonstrate its ability to control the aircraft and improve its endurance by exploiting updrafts in non-stationary scenarios.