 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Solve Resource-Constrained Project Scheduling Problems with Duration Uncertainty using Graph Neural Networks
Nov 17, 2025The Resource-Constrained Project Scheduling Problem (RCPSP) is a classical scheduling problem that has received significant attention due to of its numerous applications in industry. However, in practice, task durations are subject to uncertainty that must be considered in order to propose resilient scheduling. In this paper, we address the RCPSP variant with uncertain tasks duration (modeled using known probabilities) and aim to minimize the overall expected project duration. Our objective is to produce a baseline schedule that can be reused multiple times in an industrial setting regardless of the actual duration scenario. We leverage Graph Neural Networks in conjunction with Deep Reinforcement Learning (DRL) to develop an effective policy for task scheduling. This policy operates similarly to a priority dispatch rule and is paired with a Serial Schedule Generation Scheme to produce a schedule. Our empirical evaluation on standard benchmarks demonstrates the approach's superiority in terms of performance and its ability to generalize. The developed framework, Wheatley, is made publicly available online to facilitate further research and reproducibility.
Earth Observation Satellite Scheduling with Graph Neural Networks
Aug 27, 2024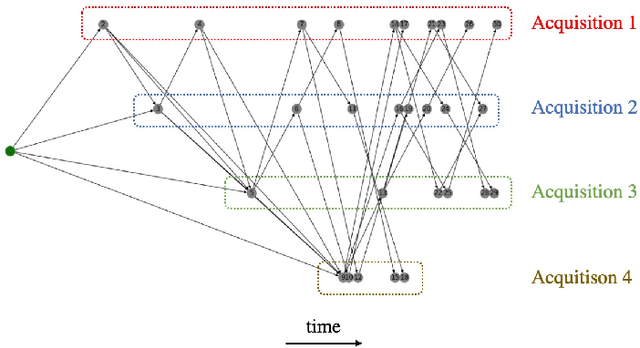
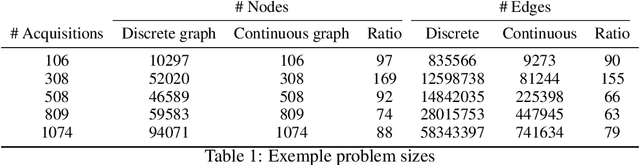
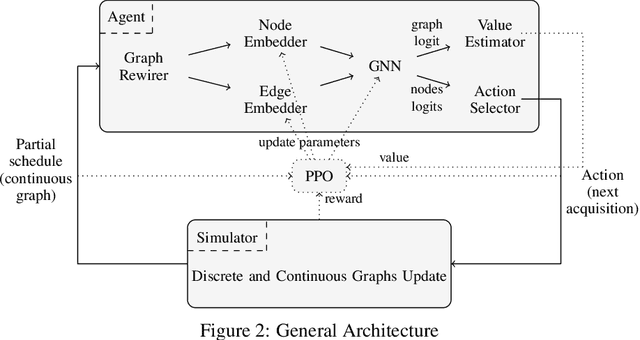
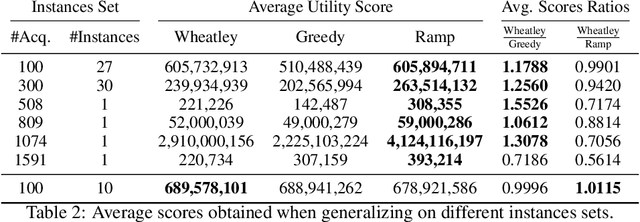
The Earth Observation Satellite Planning (EOSP) is a difficult optimization problem with considerable practical interest. A set of requested observations must be scheduled on an agile Earth observation satellite while respecting constraints on their visibility window, as well as maneuver constraints that impose varying delays between successive observations. In addition, the problem is largely oversubscribed: there are much more candidate observations than what can possibly be achieved. Therefore, one must select the set of observations that will be performed while maximizing their weighted cumulative benefit, and propose a feasible schedule for these observations. As previous work mostly focused on heuristic and iterative search algorithms, this paper presents a new technique for selecting and scheduling observations based on Graph Neural Networks (GNNs) and Deep Reinforcement Learning (DRL). GNNs are used to extract relevant information from the graphs representing instances of the EOSP, and DRL drives the search for optimal schedules. Our simulations show that it is able to learn on small problem instances and generalize to larger real-world instances, with very competitive performance compared to traditional approaches.
Open Loop Execution of Tree-Search Algorithms
May 03, 2018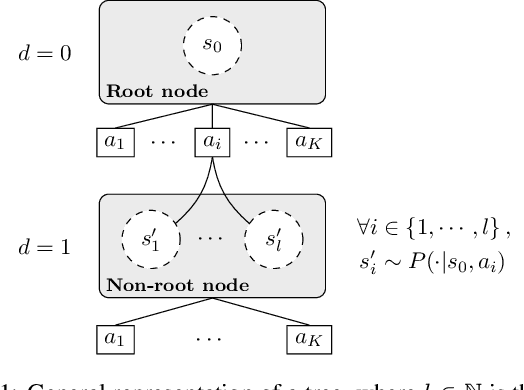
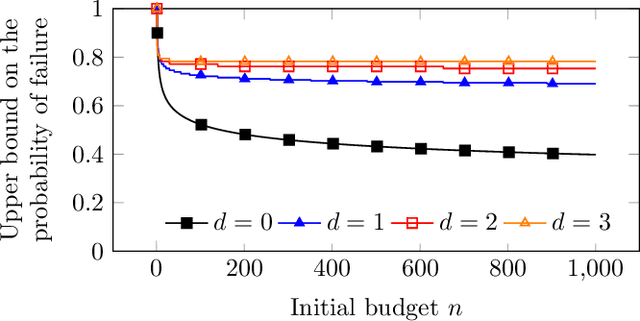
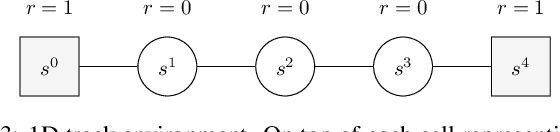
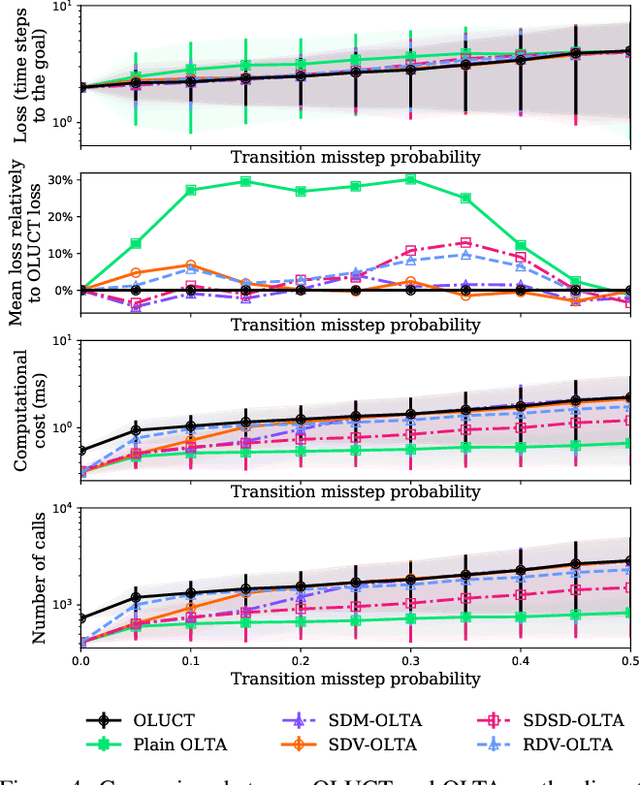
In the context of tree-search stochastic planning algorithms where a generative model is available, we consider on-line planning algorithms building trees in order to recommend an action. We investigate the question of avoiding re-planning in subsequent decision steps by directly using sub-trees as action recommender. Firstly, we propose a method for open loop control via a new algorithm taking the decision of re-planning or not at each time step based on an analysis of the statistics of the sub-tree. Secondly, we show that the probability of selecting a suboptimal action at any depth of the tree can be upper bounded and converges towards zero. Moreover, this upper bound decays in a logarithmic way between subsequent depths. This leads to a distinction between node-wise optimality and state-wise optimality. Finally, we empirically demonstrate that our method achieves a compromise between loss of performance and computational gain.