 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Layer-Wise Relevance Propagation: a more Robust Neural Networks eXplaination
Jan 24, 2025



Machine learning methods are solving very successfully a plethora of tasks, but they have the disadvantage of not providing any information about their decision. Consequently, estimating the reasoning of the system provides additional information. For this, Layer-Wise Relevance Propagation (LRP) is one of the methods in eXplainable Machine Learning (XML). Its purpose is to provide contributions of any neural network output in the domain of its input. The main drawback of current methods is mainly due to division by small values. To overcome this problem, we provide a new definition called Relative LRP where the classical conservation law is satisfied up to a multiplicative factor but without divisions by small values except for Resnet skip connection. In this article, we will focus on image classification. This allows us to visualize the contributions of a pixel to the predictions of a multi-layer neural network. Pixel contributions provide a focus to further analysis on regions of potential interest. R-LRP can be applied for any dense, CNN or residual neural networks. Moreover, R-LRP doesn't need any hyperparameters to tune contrary to other LRP methods. We then compare the R-LRP method on different datasets with simple CNN, VGG16, VGG19 and Resnet50 networks.
Combining pretrained CNN feature extractors to enhance clustering of complex natural images
Jan 07, 2021
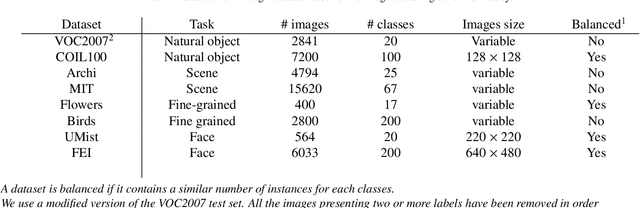
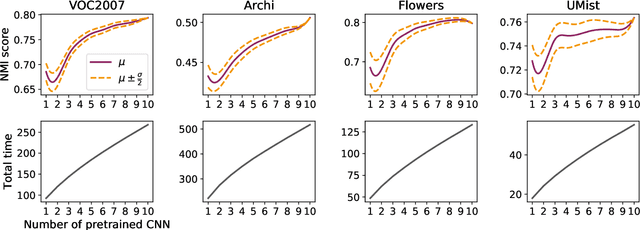
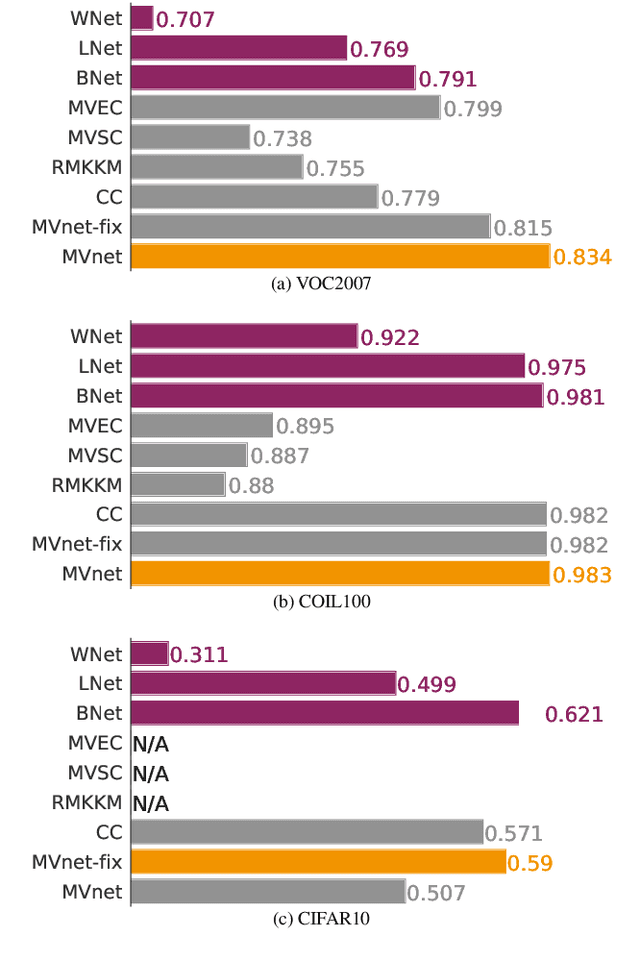
Recently, a common starting point for solving complex unsupervised image classification tasks is to use generic features, extracted with deep Convolutional Neural Networks (CNN) pretrained on a large and versatile dataset (ImageNet). However, in most research, the CNN architecture for feature extraction is chosen arbitrarily, without justification. This paper aims at providing insight on the use of pretrained CNN features for image clustering (IC). First, extensive experiments are conducted and show that, for a given dataset, the choice of the CNN architecture for feature extraction has a huge impact on the final clustering. These experiments also demonstrate that proper extractor selection for a given IC task is difficult. To solve this issue, we propose to rephrase the IC problem as a multi-view clustering (MVC) problem that considers features extracted from different architectures as different "views" of the same data. This approach is based on the assumption that information contained in the different CNN may be complementary, even when pretrained on the same data. We then propose a multi-input neural network architecture that is trained end-to-end to solve the MVC problem effectively. This approach is tested on nine natural image datasets, and produces state-of-the-art results for IC.
* 21 pages, 16 figures, 10 tables, preprint of our paper published in Neurocomputing
CNN features are also great at unsupervised classification
Sep 11, 2018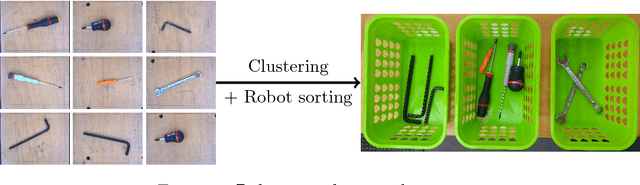
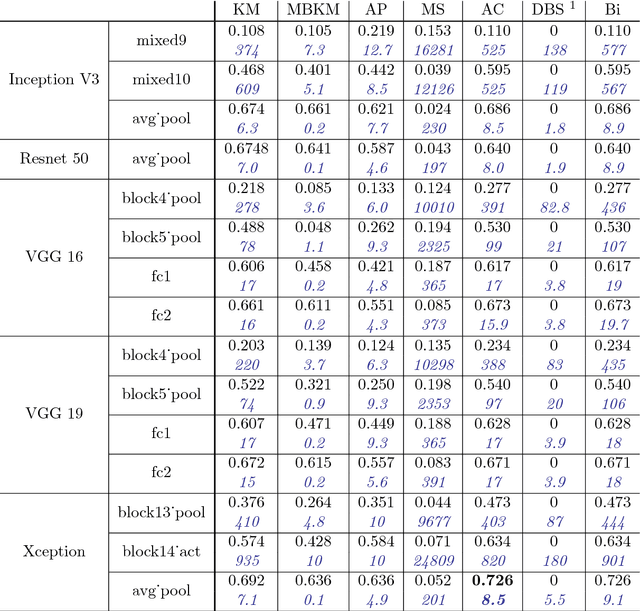


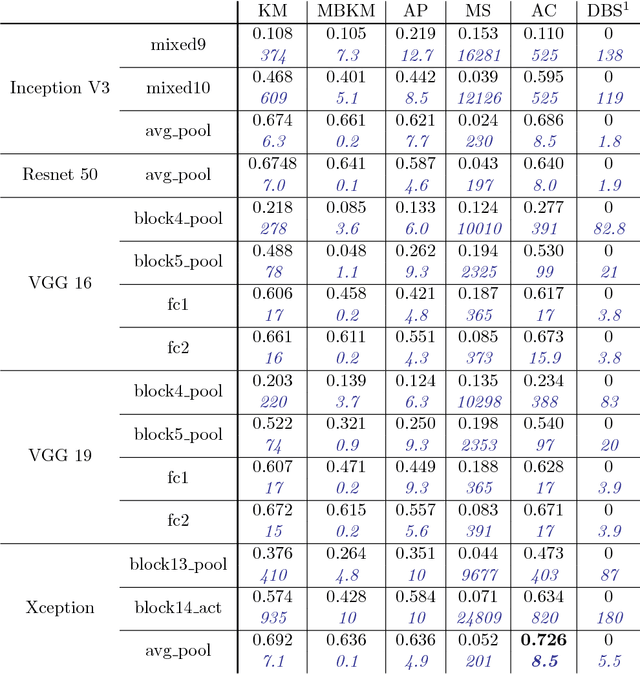
This paper aims at providing insight on the transferability of deep CNN features to unsupervised problems. We study the impact of different pretrained CNN feature extractors on the problem of image set clustering for object classification as well as fine-grained classification. We propose a rather straightforward pipeline combining deep-feature extraction using a CNN pretrained on ImageNet and a classic clustering algorithm to classify sets of images. This approach is compared to state-of-the-art algorithms in image-clustering and provides better results. These results strengthen the belief that supervised training of deep CNN on large datasets, with a large variability of classes, extracts better features than most carefully designed engineering approaches, even for unsupervised tasks. We also validate our approach on a robotic application, consisting in sorting and storing objects smartly based on clustering.
Automatic Construction of Real-World Datasets for 3D Object Localization using Two Cameras
Sep 11, 2018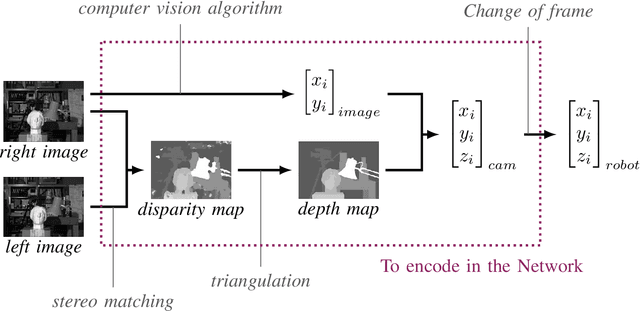


Unlike classification, position labels cannot be assigned manually by humans. For this reason, generating supervision for precise object localization is a hard task. This paper details a method to create large datasets for 3D object localization, with real world images, using an industrial robot to generate position labels. By knowledge of the geometry of the robot, we are able to automatically synchronize the images of the two cameras and the object 3D position. We applied it to generate a screw-driver localization dataset with stereo images, using a KUKA LBR iiwa robot. This dataset could then be used to train a CNN regressor to learn end-to-end stereo object localization from a set of two standard uncalibrated cameras.
Semantically Meaningful View Selection
Jul 26, 2018



An understanding of the nature of objects could help robots to solve both high-level abstract tasks and improve performance at lower-level concrete tasks. Although deep learning has facilitated progress in image understanding, a robot's performance in problems like object recognition often depends on the angle from which the object is observed. Traditionally, robot sorting tasks rely on a fixed top-down view of an object. By changing its viewing angle, a robot can select a more semantically informative view leading to better performance for object recognition. In this paper, we introduce the problem of semantic view selection, which seeks to find good camera poses to gain semantic knowledge about an observed object. We propose a conceptual formulation of the problem, together with a solvable relaxation based on clustering. We then present a new image dataset consisting of around 10k images representing various views of 144 objects under different poses. Finally we use this dataset to propose a first solution to the problem by training a neural network to predict a "semantic score" from a top view image and camera pose. The views predicted to have higher scores are then shown to provide better clustering results than fixed top-down views.
Unsupervised robotic sorting: Towards autonomous decision making robots
Apr 12, 2018

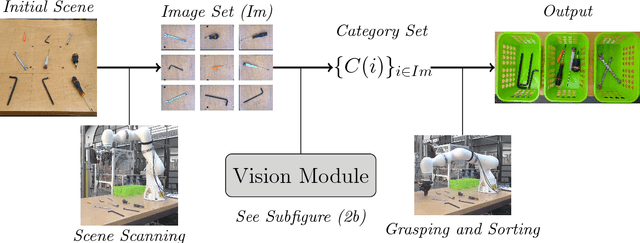
Autonomous sorting is a crucial task in industrial robotics which can be very challenging depending on the expected amount of automation. Usually, to decide where to sort an object, the system needs to solve either an instance retrieval (known object) or a supervised classification (predefined set of classes) problem. In this paper, we introduce a new decision making module, where the robotic system chooses how to sort the objects in an unsupervised way. We call this problem Unsupervised Robotic Sorting (URS) and propose an implementation on an industrial robotic system, using deep CNN feature extraction and standard clustering algorithms. We carry out extensive experiments on various standard datasets to demonstrate the efficiency of the proposed image clustering pipeline. To evaluate the robustness of our URS implementation, we also introduce a complex real world dataset containing images of objects under various background and lighting conditions. This dataset is used to fine tune the design choices (CNN and clustering algorithm) for URS. Finally, we propose a method combining our pipeline with ensemble clustering to use multiple images of each object. This redundancy of information about the objects is shown to increase the clustering results.
* Paper published in International Journal of Artificial Intelligence and Applications (IJAIA), March 2018, Volume 9, Number 2 17 pages, 5 figures, 7 tables. arXiv admin note: text overlap with arXiv:1707.01700
Clustering for Different Scales of Measurement - the Gap-Ratio Weighted K-means Algorithm
Mar 22, 2017
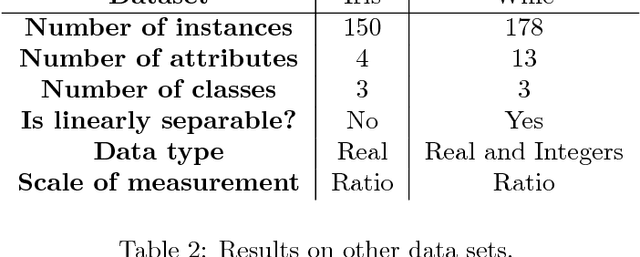
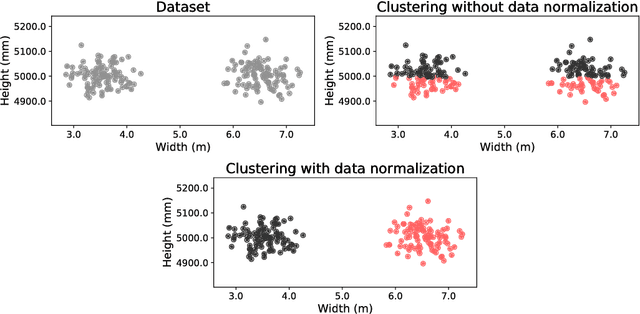

This paper describes a method for clustering data that are spread out over large regions and which dimensions are on different scales of measurement. Such an algorithm was developed to implement a robotics application consisting in sorting and storing objects in an unsupervised way. The toy dataset used to validate such application consists of Lego bricks of different shapes and colors. The uncontrolled lighting conditions together with the use of RGB color features, respectively involve data with a large spread and different levels of measurement between data dimensions. To overcome the combination of these two characteristics in the data, we have developed a new weighted K-means algorithm, called gap-ratio K-means, which consists in weighting each dimension of the feature space before running the K-means algorithm. The weight associated with a feature is proportional to the ratio of the biggest gap between two consecutive data points, and the average of all the other gaps. This method is compared with two other variants of K-means on the Lego bricks clustering problem as well as two other common classification datasets.
Learning local trajectories for high precision robotic tasks : application to KUKA LBR iiwa Cartesian positioning
Jan 05, 2017
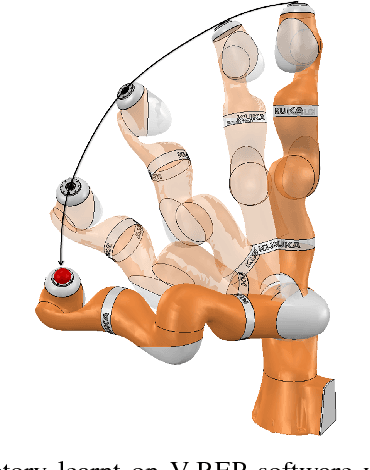

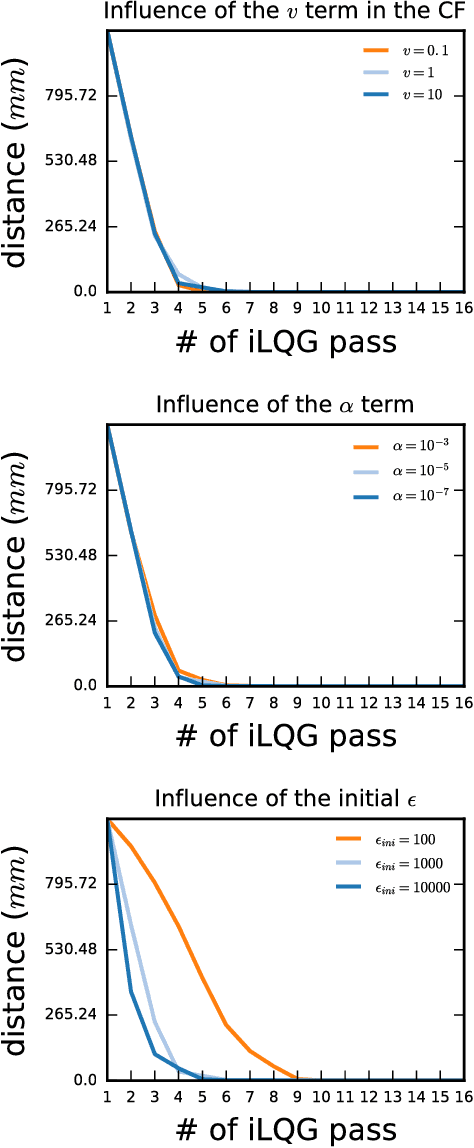
To ease the development of robot learning in industry, two conditions need to be fulfilled. Manipulators must be able to learn high accuracy and precision tasks while being safe for workers in the factory. In this paper, we extend previously submitted work which consists in rapid learning of local high accuracy behaviors. By exploration and regression, linear and quadratic models are learnt for respectively the dynamics and cost function. Iterative Linear Quadratic Gaussian Regulator combined with cost quadratic regression can converge rapidly in the final stages towards high accuracy behavior as the cost function is modelled quite precisely. In this paper, both a different cost function and a second order improvement method are implemented within this framework. We also propose an analysis of the algorithm parameters through simulation for a positioning task. Finally, an experimental validation on a KUKA LBR iiwa robot is carried out. This collaborative robot manipulator can be easily programmed into safety mode, which makes it qualified for the second industry constraint stated above.
* 6 pages, double column, 6 figures and one table. Published in: Industrial Electronics Society , IECON 2016 - 42nd Annual Conference of the IEEE