 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Classification for Automated Image Annotation of Coral Reef Benthic Structures
Dec 11, 2024Automated benthic image annotation is crucial to efficiently monitor and protect coral reefs against climate change. Current machine learning approaches fail to capture the hierarchical nature of benthic organisms covering reef substrata, i.e., coral taxonomic levels and health condition. To address this limitation, we propose to annotate benthic images using hierarchical classification. Experiments on a custom dataset from a Northeast Brazilian coral reef show that our approach outperforms flat classifiers, improving both F1 and hierarchical F1 scores by approximately 2\% across varying amounts of training data. In addition, this hierarchical method aligns more closely with ecological objectives.
Safety Monitoring of Machine Learning Perception Functions: a Survey
Dec 09, 2024Machine Learning (ML) models, such as deep neural networks, are widely applied in autonomous systems to perform complex perception tasks. New dependability challenges arise when ML predictions are used in safety-critical applications, like autonomous cars and surgical robots. Thus, the use of fault tolerance mechanisms, such as safety monitors, is essential to ensure the safe behavior of the system despite the occurrence of faults. This paper presents an extensive literature review on safety monitoring of perception functions using ML in a safety-critical context. In this review, we structure the existing literature to highlight key factors to consider when designing such monitors: threat identification, requirements elicitation, detection of failure, reaction, and evaluation. We also highlight the ongoing challenges associated with safety monitoring and suggest directions for future research.
Can we Defend Against the Unknown? An Empirical Study About Threshold Selection for Neural Network Monitoring
May 14, 2024With the increasing use of neural networks in critical systems, runtime monitoring becomes essential to reject unsafe predictions during inference. Various techniques have emerged to establish rejection scores that maximize the separability between the distributions of safe and unsafe predictions. The efficacy of these approaches is mostly evaluated using threshold-agnostic metrics, such as the area under the receiver operating characteristic curve. However, in real-world applications, an effective monitor also requires identifying a good threshold to transform these scores into meaningful binary decisions. Despite the pivotal importance of threshold optimization, this problem has received little attention. A few studies touch upon this question, but they typically assume that the runtime data distribution mirrors the training distribution, which is a strong assumption as monitors are supposed to safeguard a system against potentially unforeseen threats. In this work, we present rigorous experiments on various image datasets to investigate: 1. The effectiveness of monitors in handling unforeseen threats, which are not available during threshold adjustments. 2. Whether integrating generic threats into the threshold optimization scheme can enhance the robustness of monitors.
Combining Two Adversarial Attacks Against Person Re-Identification Systems
Sep 24, 2023
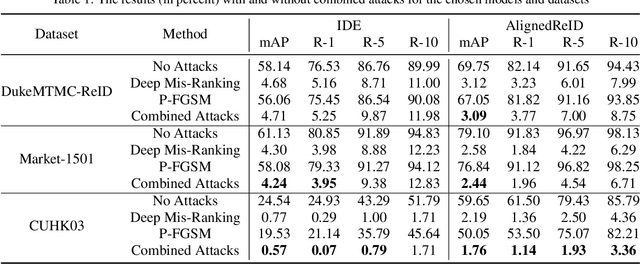


The field of Person Re-Identification (Re-ID) has received much attention recently, driven by the progress of deep neural networks, especially for image classification. The problem of Re-ID consists in identifying individuals through images captured by surveillance cameras in different scenarios. Governments and companies are investing a lot of time and money in Re-ID systems for use in public safety and identifying missing persons. However, several challenges remain for successfully implementing Re-ID, such as occlusions and light reflections in people's images. In this work, we focus on adversarial attacks on Re-ID systems, which can be a critical threat to the performance of these systems. In particular, we explore the combination of adversarial attacks against Re-ID models, trying to strengthen the decrease in the classification results. We conduct our experiments on three datasets: DukeMTMC-ReID, Market-1501, and CUHK03. We combine the use of two types of adversarial attacks, P-FGSM and Deep Mis-Ranking, applied to two popular Re-ID models: IDE (ResNet-50) and AlignedReID. The best result demonstrates a decrease of 3.36% in the Rank-10 metric for AlignedReID applied to CUHK03. We also try to use Dropout during the inference as a defense method.
Out-Of-Distribution Detection Is Not All You Need
Nov 29, 2022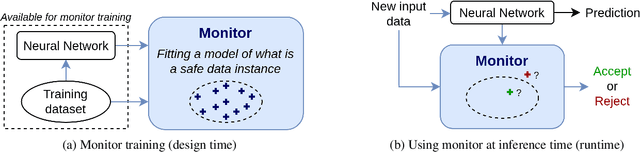
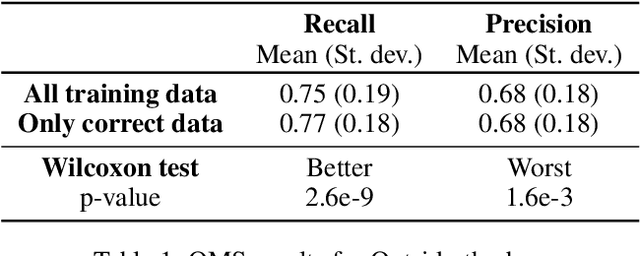

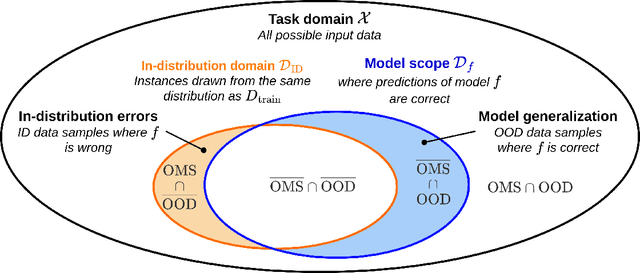
The usage of deep neural networks in safety-critical systems is limited by our ability to guarantee their correct behavior. Runtime monitors are components aiming to identify unsafe predictions and discard them before they can lead to catastrophic consequences. Several recent works on runtime monitoring have focused on out-of-distribution (OOD) detection, i.e., identifying inputs that are different from the training data. In this work, we argue that OOD detection is not a well-suited framework to design efficient runtime monitors and that it is more relevant to evaluate monitors based on their ability to discard incorrect predictions. We call this setting out-ofmodel-scope detection and discuss the conceptual differences with OOD. We also conduct extensive experiments on popular datasets from the literature to show that studying monitors in the OOD setting can be misleading: 1. very good OOD results can give a false impression of safety, 2. comparison under the OOD setting does not allow identifying the best monitor to detect errors. Finally, we also show that removing erroneous training data samples helps to train better monitors.
A novel method for object detection using deep learning and CAD models
Feb 12, 2021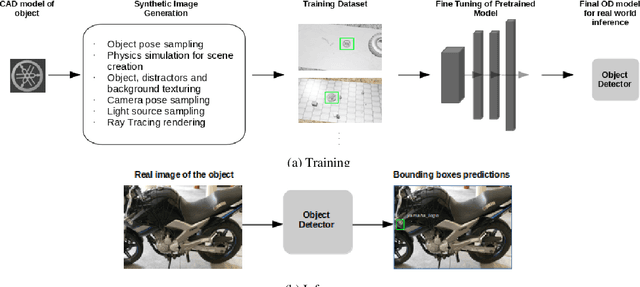
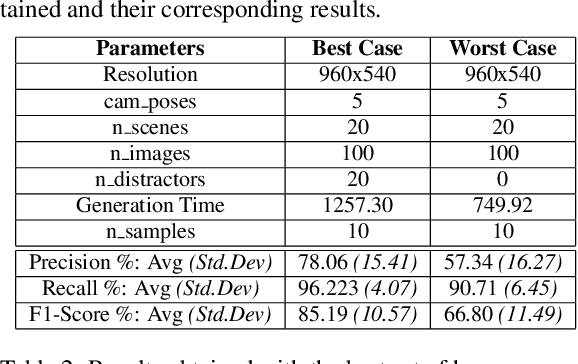


Object Detection (OD) is an important computer vision problem for industry, which can be used for quality control in the production lines, among other applications. Recently, Deep Learning (DL) methods have enabled practitioners to train OD models performing well on complex real world images. However, the adoption of these models in industry is still limited by the difficulty and the significant cost of collecting high quality training datasets. On the other hand, when applying OD to the context of production lines, CAD models of the objects to be detected are often available. In this paper, we introduce a fully automated method that uses a CAD model of an object and returns a fully trained OD model for detecting this object. To do this, we created a Blender script that generates realistic labeled datasets of images containing the object, which are then used for training the OD model. The method is validated experimentally on two practical examples, showing that this approach can generate OD models performing well on real images, while being trained only on synthetic images. The proposed method has potential to facilitate the adoption of object detection models in industry as it is easy to adapt for new objects and highly flexible. Hence, it can result in significant costs reduction, gains in productivity and improved products quality.
Towards Practical Implementations of Person Re-Identification from Full Video Frames
Sep 02, 2020
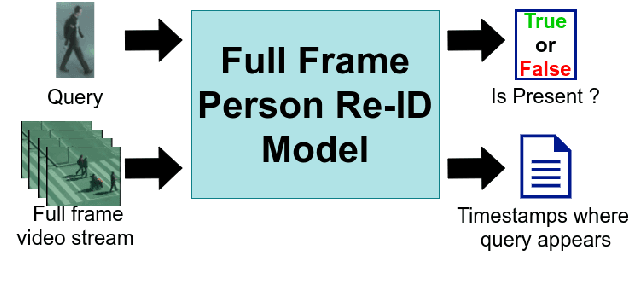


With the major adoption of automation for cities security, person re-identification (Re-ID) has been extensively studied recently. In this paper, we argue that the current way of studying person re-identification, i.e. by trying to re-identify a person within already detected and pre-cropped images of people, is not sufficient to implement practical security applications, where the inputs to the system are the full frames of the video streams. To support this claim, we introduce the Full Frame Person Re-ID setting (FF-PRID) and define specific metrics to evaluate FF-PRID implementations. To improve robustness, we also formalize the hybrid human-machine collaboration framework, which is inherent to any Re-ID security applications. To demonstrate the importance of considering the FF-PRID setting, we build an experiment showing that combining a good people detection network with a good Re-ID model does not necessarily produce good results for the final application. This underlines a failure of the current formulation in assessing the quality of a Re-ID model and justifies the use of different metrics. We hope that this work will motivate the research community to consider the full problem in order to develop algorithms that are better suited to real-world scenarios.
CNN features are also great at unsupervised classification
Sep 11, 2018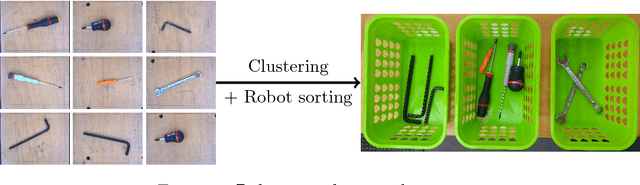
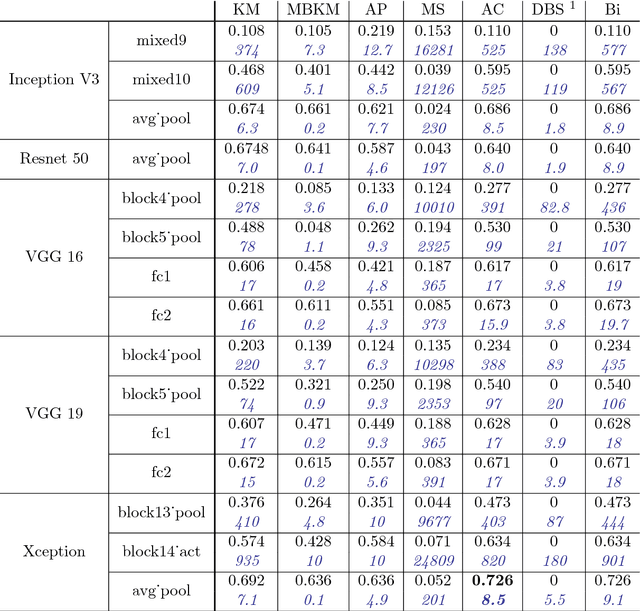


This paper aims at providing insight on the transferability of deep CNN features to unsupervised problems. We study the impact of different pretrained CNN feature extractors on the problem of image set clustering for object classification as well as fine-grained classification. We propose a rather straightforward pipeline combining deep-feature extraction using a CNN pretrained on ImageNet and a classic clustering algorithm to classify sets of images. This approach is compared to state-of-the-art algorithms in image-clustering and provides better results. These results strengthen the belief that supervised training of deep CNN on large datasets, with a large variability of classes, extracts better features than most carefully designed engineering approaches, even for unsupervised tasks. We also validate our approach on a robotic application, consisting in sorting and storing objects smartly based on clustering.
Automatic Construction of Real-World Datasets for 3D Object Localization using Two Cameras
Sep 11, 2018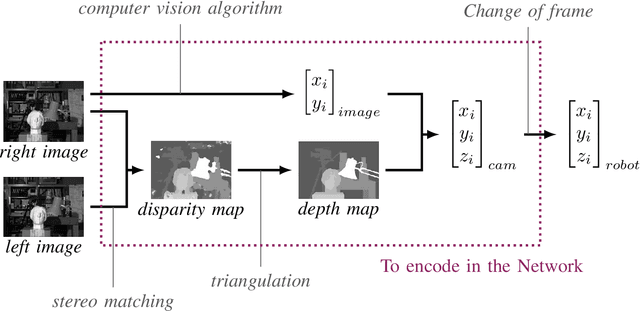


Unlike classification, position labels cannot be assigned manually by humans. For this reason, generating supervision for precise object localization is a hard task. This paper details a method to create large datasets for 3D object localization, with real world images, using an industrial robot to generate position labels. By knowledge of the geometry of the robot, we are able to automatically synchronize the images of the two cameras and the object 3D position. We applied it to generate a screw-driver localization dataset with stereo images, using a KUKA LBR iiwa robot. This dataset could then be used to train a CNN regressor to learn end-to-end stereo object localization from a set of two standard uncalibrated cameras.
Semantically Meaningful View Selection
Jul 26, 2018



An understanding of the nature of objects could help robots to solve both high-level abstract tasks and improve performance at lower-level concrete tasks. Although deep learning has facilitated progress in image understanding, a robot's performance in problems like object recognition often depends on the angle from which the object is observed. Traditionally, robot sorting tasks rely on a fixed top-down view of an object. By changing its viewing angle, a robot can select a more semantically informative view leading to better performance for object recognition. In this paper, we introduce the problem of semantic view selection, which seeks to find good camera poses to gain semantic knowledge about an observed object. We propose a conceptual formulation of the problem, together with a solvable relaxation based on clustering. We then present a new image dataset consisting of around 10k images representing various views of 144 objects under different poses. Finally we use this dataset to propose a first solution to the problem by training a neural network to predict a "semantic score" from a top view image and camera pose. The views predicted to have higher scores are then shown to provide better clustering results than fixed top-down views.