 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Monitoring of Machine Learning Perception Functions: a Survey
Dec 09, 2024Machine Learning (ML) models, such as deep neural networks, are widely applied in autonomous systems to perform complex perception tasks. New dependability challenges arise when ML predictions are used in safety-critical applications, like autonomous cars and surgical robots. Thus, the use of fault tolerance mechanisms, such as safety monitors, is essential to ensure the safe behavior of the system despite the occurrence of faults. This paper presents an extensive literature review on safety monitoring of perception functions using ML in a safety-critical context. In this review, we structure the existing literature to highlight key factors to consider when designing such monitors: threat identification, requirements elicitation, detection of failure, reaction, and evaluation. We also highlight the ongoing challenges associated with safety monitoring and suggest directions for future research.
Can we Defend Against the Unknown? An Empirical Study About Threshold Selection for Neural Network Monitoring
May 14, 2024With the increasing use of neural networks in critical systems, runtime monitoring becomes essential to reject unsafe predictions during inference. Various techniques have emerged to establish rejection scores that maximize the separability between the distributions of safe and unsafe predictions. The efficacy of these approaches is mostly evaluated using threshold-agnostic metrics, such as the area under the receiver operating characteristic curve. However, in real-world applications, an effective monitor also requires identifying a good threshold to transform these scores into meaningful binary decisions. Despite the pivotal importance of threshold optimization, this problem has received little attention. A few studies touch upon this question, but they typically assume that the runtime data distribution mirrors the training distribution, which is a strong assumption as monitors are supposed to safeguard a system against potentially unforeseen threats. In this work, we present rigorous experiments on various image datasets to investigate: 1. The effectiveness of monitors in handling unforeseen threats, which are not available during threshold adjustments. 2. Whether integrating generic threats into the threshold optimization scheme can enhance the robustness of monitors.
Out-Of-Distribution Detection Is Not All You Need
Nov 29, 2022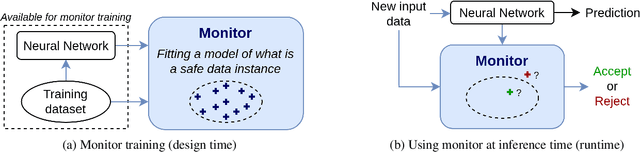
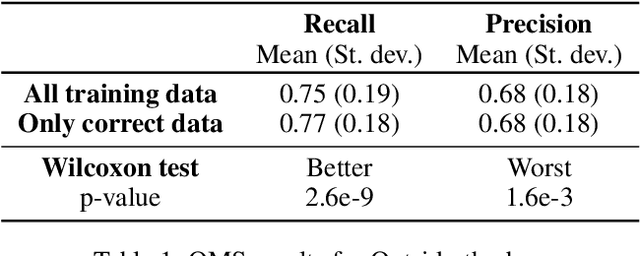

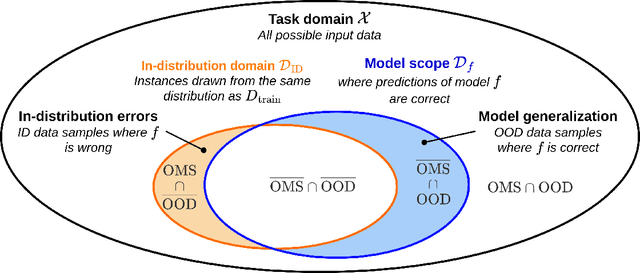
The usage of deep neural networks in safety-critical systems is limited by our ability to guarantee their correct behavior. Runtime monitors are components aiming to identify unsafe predictions and discard them before they can lead to catastrophic consequences. Several recent works on runtime monitoring have focused on out-of-distribution (OOD) detection, i.e., identifying inputs that are different from the training data. In this work, we argue that OOD detection is not a well-suited framework to design efficient runtime monitors and that it is more relevant to evaluate monitors based on their ability to discard incorrect predictions. We call this setting out-ofmodel-scope detection and discuss the conceptual differences with OOD. We also conduct extensive experiments on popular datasets from the literature to show that studying monitors in the OOD setting can be misleading: 1. very good OOD results can give a false impression of safety, 2. comparison under the OOD setting does not allow identifying the best monitor to detect errors. Finally, we also show that removing erroneous training data samples helps to train better monitors.
Unifying Evaluation of Machine Learning Safety Monitors
Aug 31, 2022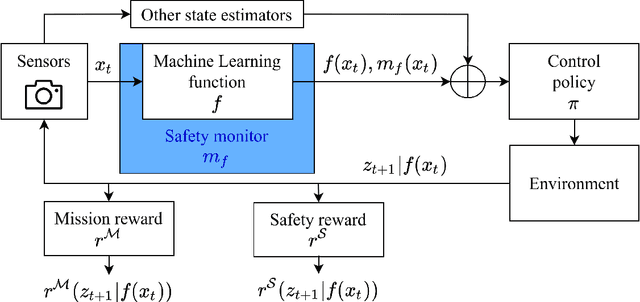
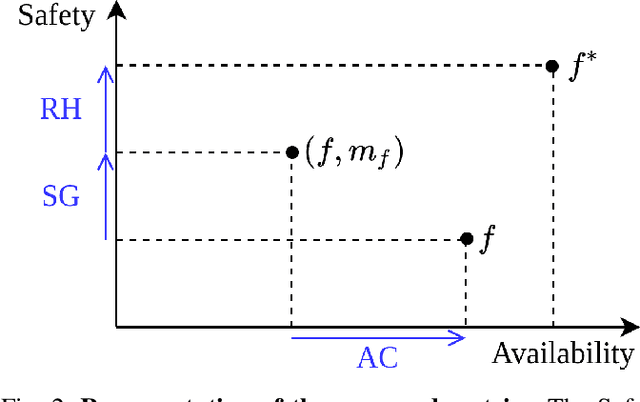


With the increasing use of Machine Learning (ML) in critical autonomous systems, runtime monitors have been developed to detect prediction errors and keep the system in a safe state during operations. Monitors have been proposed for different applications involving diverse perception tasks and ML models, and specific evaluation procedures and metrics are used for different contexts. This paper introduces three unified safety-oriented metrics, representing the safety benefits of the monitor (Safety Gain), the remaining safety gaps after using it (Residual Hazard), and its negative impact on the system's performance (Availability Cost). To compute these metrics, one requires to define two return functions, representing how a given ML prediction will impact expected future rewards and hazards. Three use-cases (classification, drone landing, and autonomous driving) are used to demonstrate how metrics from the literature can be expressed in terms of the proposed metrics. Experimental results on these examples show how different evaluation choices impact the perceived performance of a monitor. As our formalism requires us to formulate explicit safety assumptions, it allows us to ensure that the evaluation conducted matches the high-level system requirements.
Evaluation of Runtime Monitoring for UAV Emergency Landing
Feb 07, 2022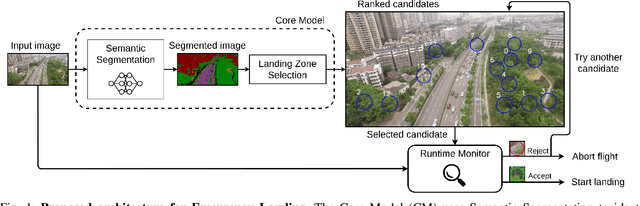
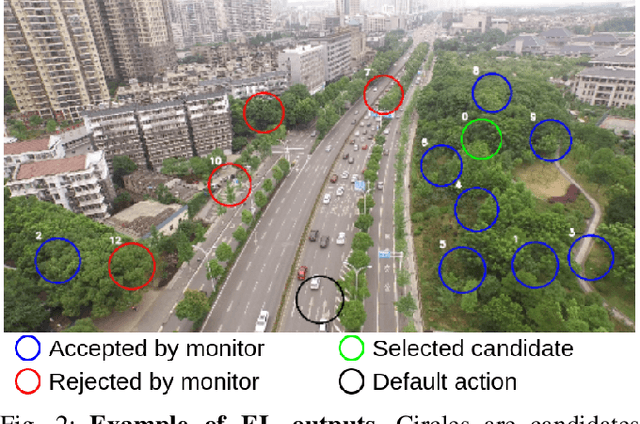
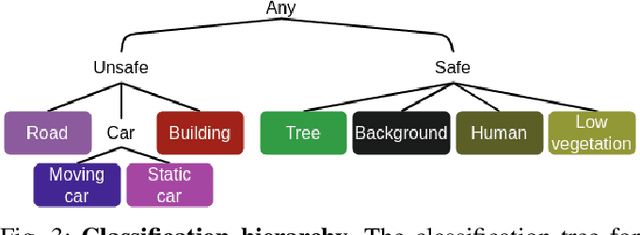

To certify UAV operations in populated areas, risk mitigation strategies -- such as Emergency Landing (EL) -- must be in place to account for potential failures. EL aims at reducing ground risk by finding safe landing areas using on-board sensors. The first contribution of this paper is to present a new EL approach, in line with safety requirements introduced in recent research. In particular, the proposed EL pipeline includes mechanisms to monitor learning based components during execution. This way, another contribution is to study the behavior of Machine Learning Runtime Monitoring (MLRM) approaches within the context of a real-world critical system. A new evaluation methodology is introduced, and applied to assess the practical safety benefits of three MLRM mechanisms. The proposed approach is compared to a default mitigation strategy (open a parachute when a failure is detected), and appears to be much safer.
Certifying Emergency Landing for Safe Urban UAV
Apr 30, 2021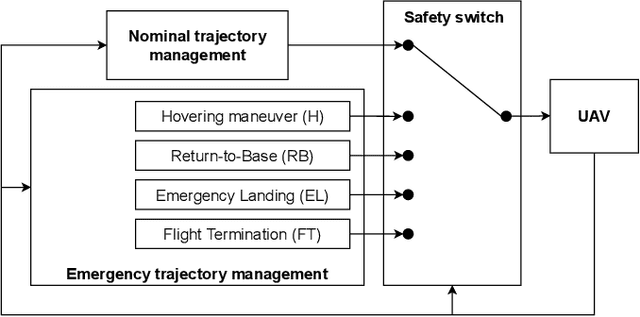
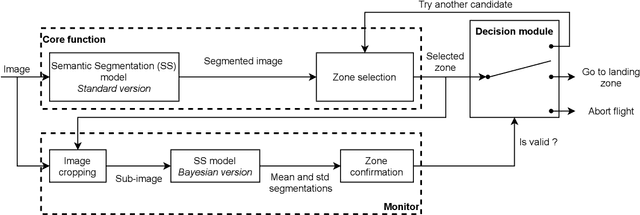

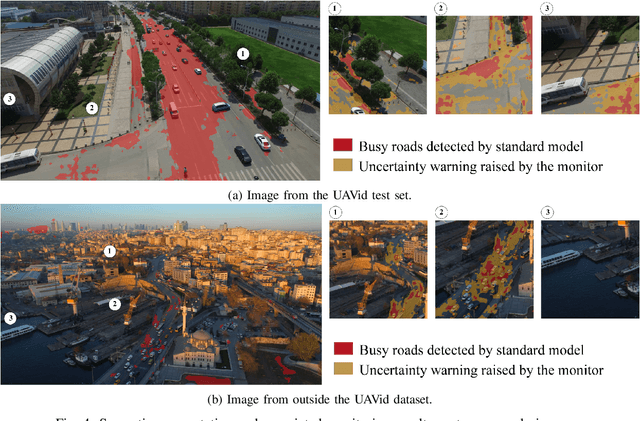
Unmanned Aerial Vehicles (UAVs) have the potential to be used for many applications in urban environments. However, allowing UAVs to fly above densely populated areas raises concerns regarding safety. One of the main safety issues is the possibility for a failure to cause the loss of navigation capabilities, which can result in the UAV falling/landing in hazardous areas such as busy roads, where it can cause fatal accidents. Current standards, such as the SORA published in 2019, do not consider applicable mitigation techniques to handle this kind of hazardous situations. Consequently, certifying UAV urban operations implies to demonstrate very high levels of integrity, which results in prohibitive development costs. To address this issue, this paper explores the concept of Emergency Landing (EL). A safety analysis is conducted on an urban UAV case study, and requirements are proposed to enable the integration of EL as an acceptable mitigation mean in the SORA. Based on these requirements, an EL implementation was developed, together with a runtime monitoring architecture to enhance confidence in the system. Preliminary qualitative results are presented and the monitor seem to be able to detect errors of the EL system effectively.
Hazard analysis of human--robot interactions with HAZOP--UML
Feb 09, 2016
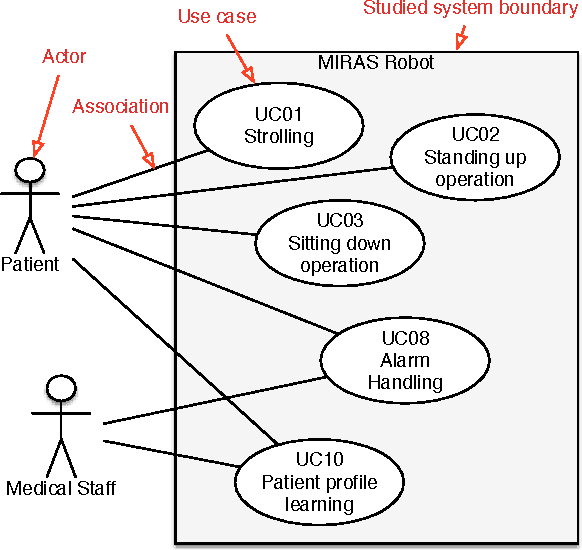
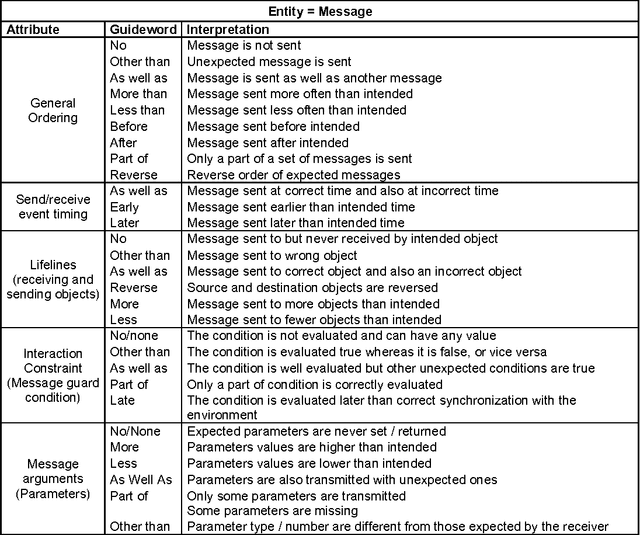

New safety critical systems are about to appear in our everyday life: advanced robots able to interact with humans and perform tasks at home, in hospitals , or at work. A hazardous behavior of those systems, induced by failures or extreme environment conditions, may lead to catastrophic consequences. Well-known risk analysis methods used in other critical domains (e.g., avion-ics, nuclear, medical, transportation), have to be extended or adapted due to the non-deterministic behavior of those systems, evolving in unstructured environments. One major challenge is thus to develop methods that can be applied at the very beginning of the development process, to identify hazards induced by robot tasks and their interactions with humans. In this paper we present a method which is based on an adaptation of a hazard identification technique, HAZOP (Hazard Operability), coupled with a system description notation, UML (Unified Modeling Language). This systematic approach has been applied successfully in research projects, and is now applied by robot manufacturers. Some results of those studies are presented and discussed to explain the benefits and limits of our method.
A Model for Safety Case Confidence Assessment
Nov 20, 2015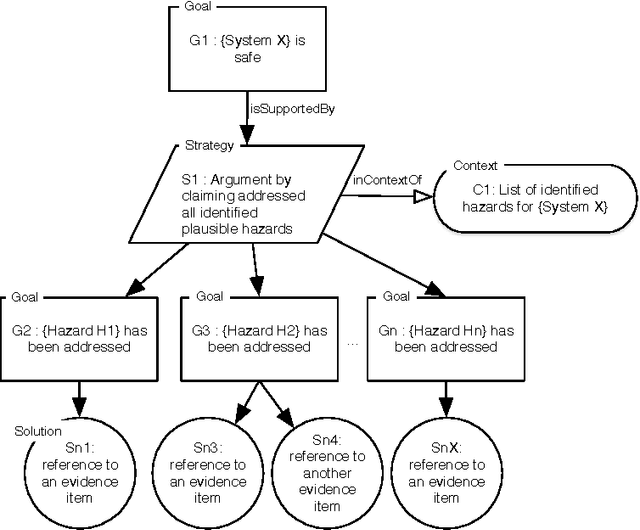
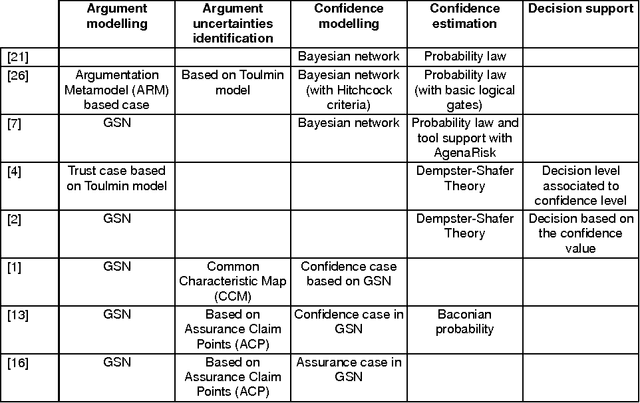
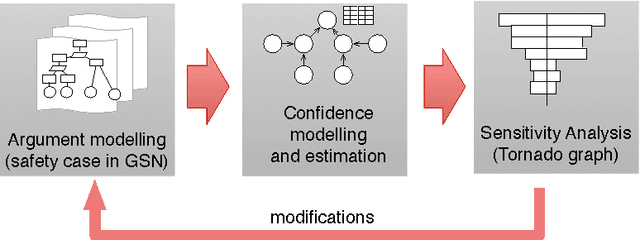
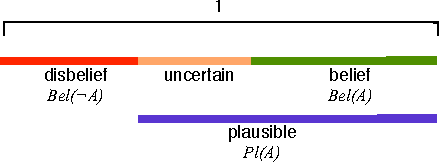
Building a safety case is a common approach to make expert judgement explicit about safety of a system. The issue of confidence in such argumentation is still an open research field. Providing quantitative estimation of confidence is an interesting approach to manage complexity of arguments. This paper explores the main current approaches, and proposes a new model for quantitative confidence estimation based on Belief Theory for its definition, and on Bayesian Belief Networks for its propagation in safety case networks.