 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Monitoring of Machine Learning Perception Functions: a Survey
Dec 09, 2024Machine Learning (ML) models, such as deep neural networks, are widely applied in autonomous systems to perform complex perception tasks. New dependability challenges arise when ML predictions are used in safety-critical applications, like autonomous cars and surgical robots. Thus, the use of fault tolerance mechanisms, such as safety monitors, is essential to ensure the safe behavior of the system despite the occurrence of faults. This paper presents an extensive literature review on safety monitoring of perception functions using ML in a safety-critical context. In this review, we structure the existing literature to highlight key factors to consider when designing such monitors: threat identification, requirements elicitation, detection of failure, reaction, and evaluation. We also highlight the ongoing challenges associated with safety monitoring and suggest directions for future research.
Out-Of-Distribution Detection Is Not All You Need
Nov 29, 2022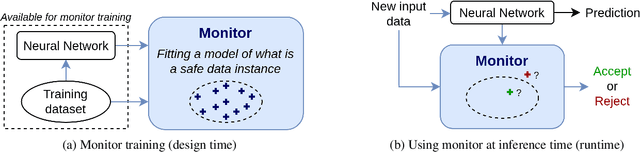
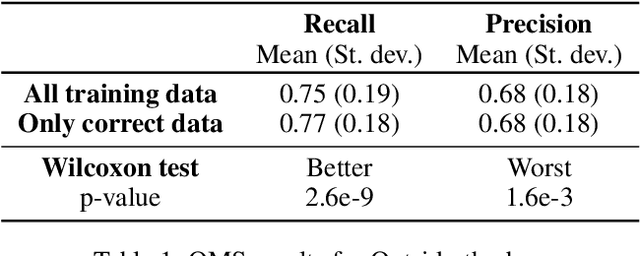

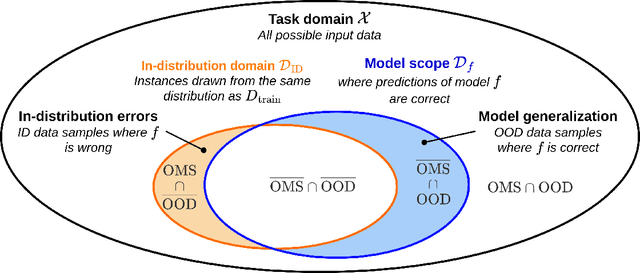
The usage of deep neural networks in safety-critical systems is limited by our ability to guarantee their correct behavior. Runtime monitors are components aiming to identify unsafe predictions and discard them before they can lead to catastrophic consequences. Several recent works on runtime monitoring have focused on out-of-distribution (OOD) detection, i.e., identifying inputs that are different from the training data. In this work, we argue that OOD detection is not a well-suited framework to design efficient runtime monitors and that it is more relevant to evaluate monitors based on their ability to discard incorrect predictions. We call this setting out-ofmodel-scope detection and discuss the conceptual differences with OOD. We also conduct extensive experiments on popular datasets from the literature to show that studying monitors in the OOD setting can be misleading: 1. very good OOD results can give a false impression of safety, 2. comparison under the OOD setting does not allow identifying the best monitor to detect errors. Finally, we also show that removing erroneous training data samples helps to train better monitors.
Unifying Evaluation of Machine Learning Safety Monitors
Aug 31, 2022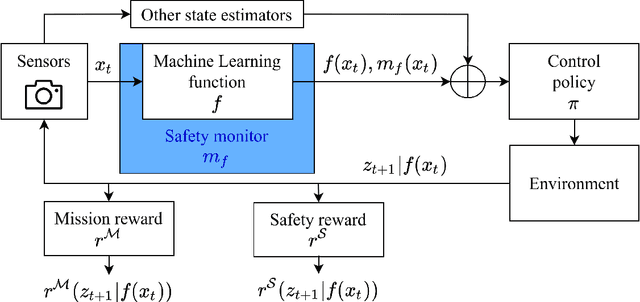
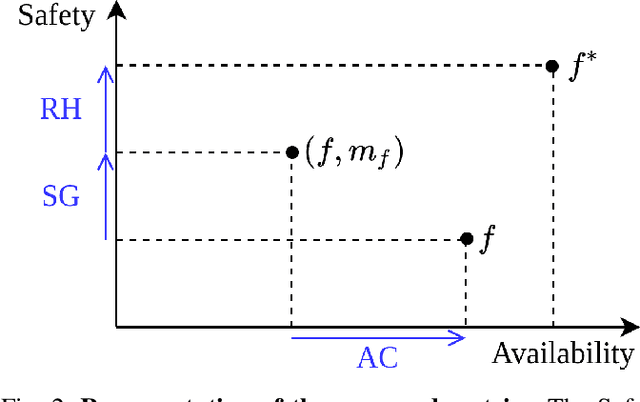


With the increasing use of Machine Learning (ML) in critical autonomous systems, runtime monitors have been developed to detect prediction errors and keep the system in a safe state during operations. Monitors have been proposed for different applications involving diverse perception tasks and ML models, and specific evaluation procedures and metrics are used for different contexts. This paper introduces three unified safety-oriented metrics, representing the safety benefits of the monitor (Safety Gain), the remaining safety gaps after using it (Residual Hazard), and its negative impact on the system's performance (Availability Cost). To compute these metrics, one requires to define two return functions, representing how a given ML prediction will impact expected future rewards and hazards. Three use-cases (classification, drone landing, and autonomous driving) are used to demonstrate how metrics from the literature can be expressed in terms of the proposed metrics. Experimental results on these examples show how different evaluation choices impact the perceived performance of a monitor. As our formalism requires us to formulate explicit safety assumptions, it allows us to ensure that the evaluation conducted matches the high-level system requirements.
Benchmarking Safety Monitors for Image Classifiers with Machine Learning
Oct 04, 2021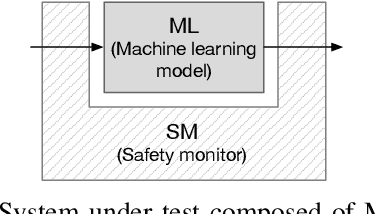
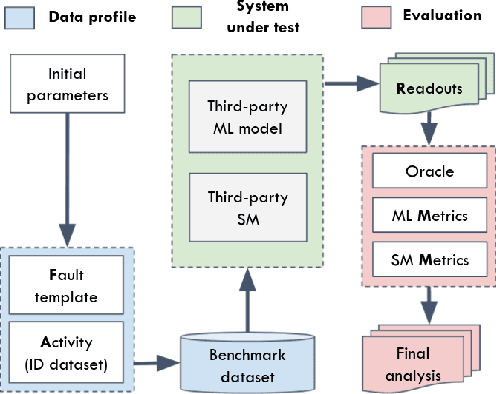
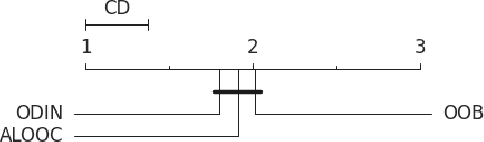
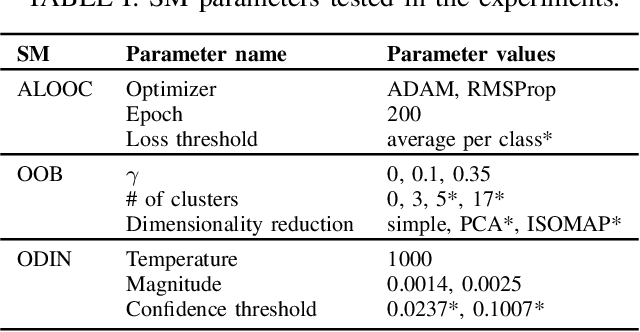
High-accurate machine learning (ML) image classifiers cannot guarantee that they will not fail at operation. Thus, their deployment in safety-critical applications such as autonomous vehicles is still an open issue. The use of fault tolerance mechanisms such as safety monitors is a promising direction to keep the system in a safe state despite errors of the ML classifier. As the prediction from the ML is the core information directly impacting safety, many works are focusing on monitoring the ML model itself. Checking the efficiency of such monitors in the context of safety-critical applications is thus a significant challenge. Therefore, this paper aims at establishing a baseline framework for benchmarking monitors for ML image classifiers. Furthermore, we propose a framework covering the entire pipeline, from data generation to evaluation. Our approach measures monitor performance with a broader set of metrics than usually proposed in the literature. Moreover, we benchmark three different monitor approaches in 79 benchmark datasets containing five categories of out-of-distribution data for image classifiers: class novelty, noise, anomalies, distributional shifts, and adversarial attacks. Our results indicate that these monitors are no more accurate than a random monitor. We also release the code of all experiments for reproducibility.