 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-Of-Distribution Detection Is Not All You Need
Paper and Code
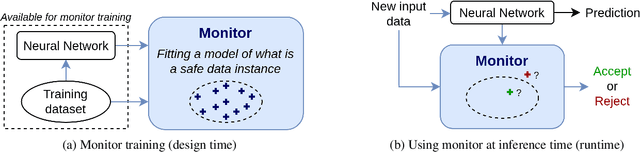
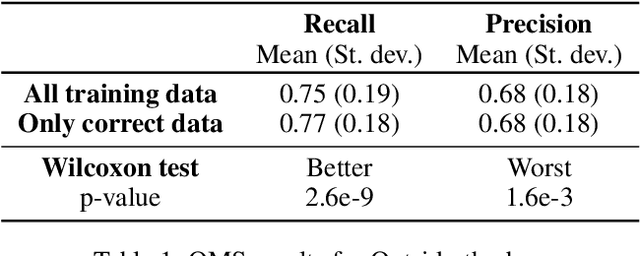

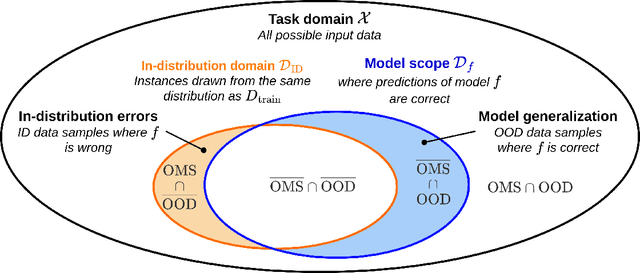
The usage of deep neural networks in safety-critical systems is limited by our ability to guarantee their correct behavior. Runtime monitors are components aiming to identify unsafe predictions and discard them before they can lead to catastrophic consequences. Several recent works on runtime monitoring have focused on out-of-distribution (OOD) detection, i.e., identifying inputs that are different from the training data. In this work, we argue that OOD detection is not a well-suited framework to design efficient runtime monitors and that it is more relevant to evaluate monitors based on their ability to discard incorrect predictions. We call this setting out-ofmodel-scope detection and discuss the conceptual differences with OOD. We also conduct extensive experiments on popular datasets from the literature to show that studying monitors in the OOD setting can be misleading: 1. very good OOD results can give a false impression of safety, 2. comparison under the OOD setting does not allow identifying the best monitor to detect errors. Finally, we also show that removing erroneous training data samples helps to train better monitors.