 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking person re-identification datasets and approaches for practical real-world implementations
Dec 20, 2022



Recently, Person Re-Identification (Re-ID) has received a lot of attention. Large datasets containing labeled images of various individuals have been released, allowing researchers to develop and test many successful approaches. However, when such Re-ID models are deployed in new cities or environments, the task of searching for people within a network of security cameras is likely to face an important domain shift, thus resulting in decreased performance. Indeed, while most public datasets were collected in a limited geographic area, images from a new city present different features (e.g., people's ethnicity and clothing style, weather, architecture, etc.). In addition, the whole frames of the video streams must be converted into cropped images of people using pedestrian detection models, which behave differently from the human annotators who created the dataset used for training. To better understand the extent of this issue, this paper introduces a complete methodology to evaluate Re-ID approaches and training datasets with respect to their suitability for unsupervised deployment for live operations. This method is used to benchmark four Re-ID approaches on three datasets, providing insight and guidelines that can help to design better Re-ID pipelines in the future.
TrADe Re-ID -- Live Person Re-Identification using Tracking and Anomaly Detection
Sep 14, 2022
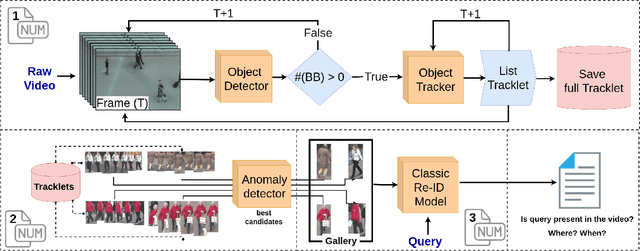
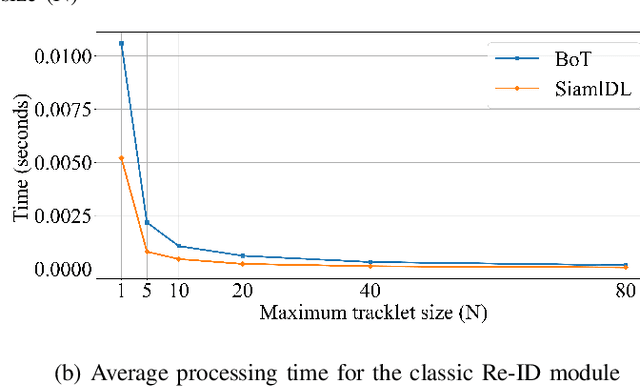
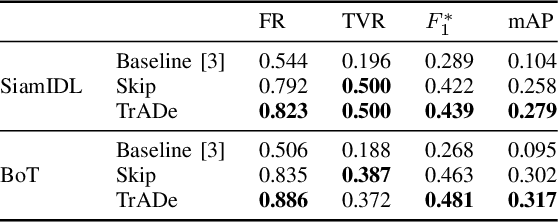
Person Re-Identification (Re-ID) aims to search for a person of interest (query) in a network of cameras. In the classic Re-ID setting the query is sought in a gallery containing properly cropped images of entire bodies. Recently, the live Re-ID setting was introduced to represent the practical application context of Re-ID better. It consists in searching for the query in short videos, containing whole scene frames. The initial live Re-ID baseline used a pedestrian detector to build a large search gallery and a classic Re-ID model to find the query in the gallery. However, the galleries generated were too large and contained low-quality images, which decreased the live Re-ID performance. Here, we present a new live Re-ID approach called TrADe, to generate lower high-quality galleries. TrADe first uses a Tracking algorithm to identify sequences of images of the same individual in the gallery. Following, an Anomaly Detection model is used to select a single good representative of each tracklet. TrADe is validated on the live Re-ID version of the PRID-2011 dataset and shows significant improvements over the baseline.
A novel method for object detection using deep learning and CAD models
Feb 12, 2021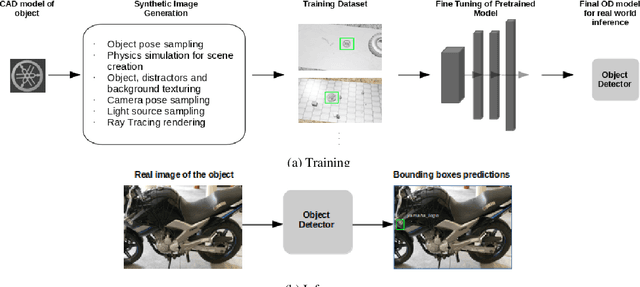
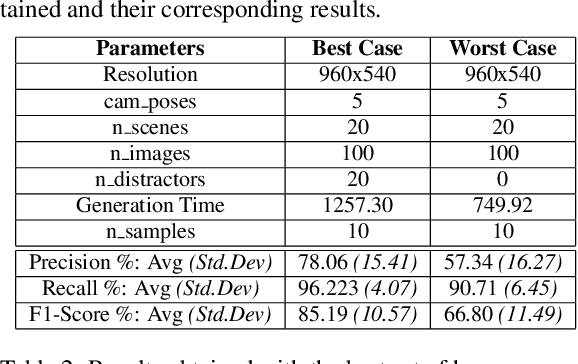


Object Detection (OD) is an important computer vision problem for industry, which can be used for quality control in the production lines, among other applications. Recently, Deep Learning (DL) methods have enabled practitioners to train OD models performing well on complex real world images. However, the adoption of these models in industry is still limited by the difficulty and the significant cost of collecting high quality training datasets. On the other hand, when applying OD to the context of production lines, CAD models of the objects to be detected are often available. In this paper, we introduce a fully automated method that uses a CAD model of an object and returns a fully trained OD model for detecting this object. To do this, we created a Blender script that generates realistic labeled datasets of images containing the object, which are then used for training the OD model. The method is validated experimentally on two practical examples, showing that this approach can generate OD models performing well on real images, while being trained only on synthetic images. The proposed method has potential to facilitate the adoption of object detection models in industry as it is easy to adapt for new objects and highly flexible. Hence, it can result in significant costs reduction, gains in productivity and improved products quality.
Towards Practical Implementations of Person Re-Identification from Full Video Frames
Sep 02, 2020
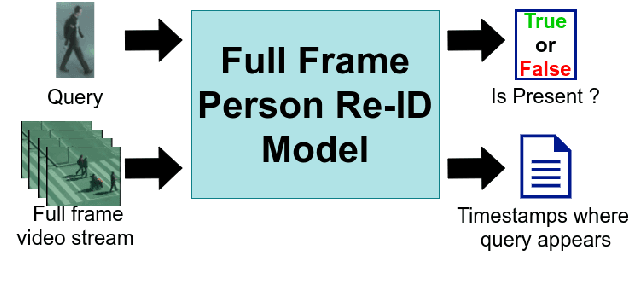


With the major adoption of automation for cities security, person re-identification (Re-ID) has been extensively studied recently. In this paper, we argue that the current way of studying person re-identification, i.e. by trying to re-identify a person within already detected and pre-cropped images of people, is not sufficient to implement practical security applications, where the inputs to the system are the full frames of the video streams. To support this claim, we introduce the Full Frame Person Re-ID setting (FF-PRID) and define specific metrics to evaluate FF-PRID implementations. To improve robustness, we also formalize the hybrid human-machine collaboration framework, which is inherent to any Re-ID security applications. To demonstrate the importance of considering the FF-PRID setting, we build an experiment showing that combining a good people detection network with a good Re-ID model does not necessarily produce good results for the final application. This underlines a failure of the current formulation in assessing the quality of a Re-ID model and justifies the use of different metrics. We hope that this work will motivate the research community to consider the full problem in order to develop algorithms that are better suited to real-world scenarios.