 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering for Different Scales of Measurement - the Gap-Ratio Weighted K-means Algorithm
Paper and Code
Mar 22, 2017
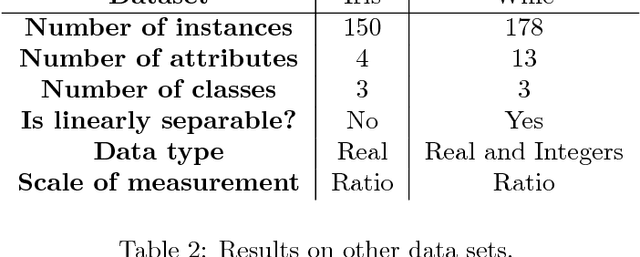
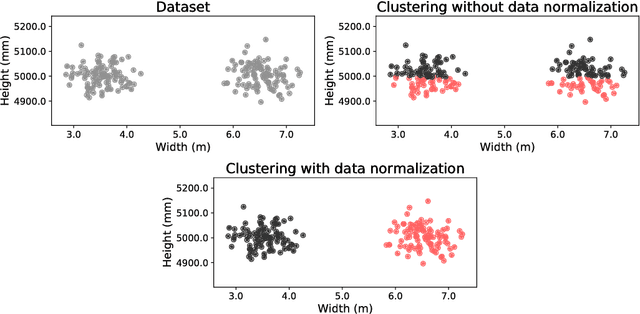

This paper describes a method for clustering data that are spread out over large regions and which dimensions are on different scales of measurement. Such an algorithm was developed to implement a robotics application consisting in sorting and storing objects in an unsupervised way. The toy dataset used to validate such application consists of Lego bricks of different shapes and colors. The uncontrolled lighting conditions together with the use of RGB color features, respectively involve data with a large spread and different levels of measurement between data dimensions. To overcome the combination of these two characteristics in the data, we have developed a new weighted K-means algorithm, called gap-ratio K-means, which consists in weighting each dimension of the feature space before running the K-means algorithm. The weight associated with a feature is proportional to the ratio of the biggest gap between two consecutive data points, and the average of all the other gaps. This method is compared with two other variants of K-means on the Lego bricks clustering problem as well as two other common classification datasets.