 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Constrained-Based Causal Discovery
Jun 11, 2024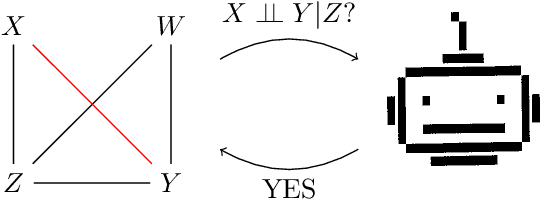
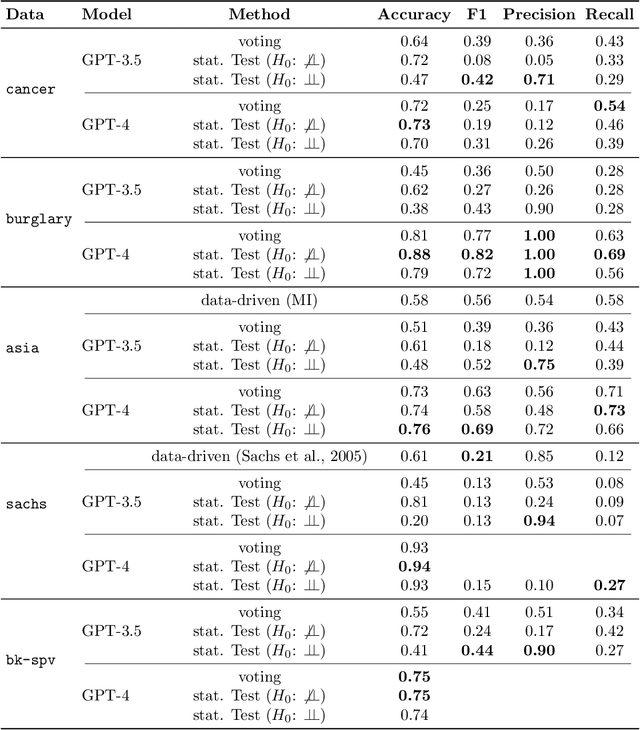
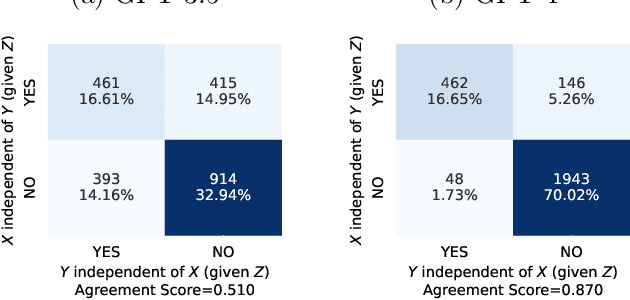
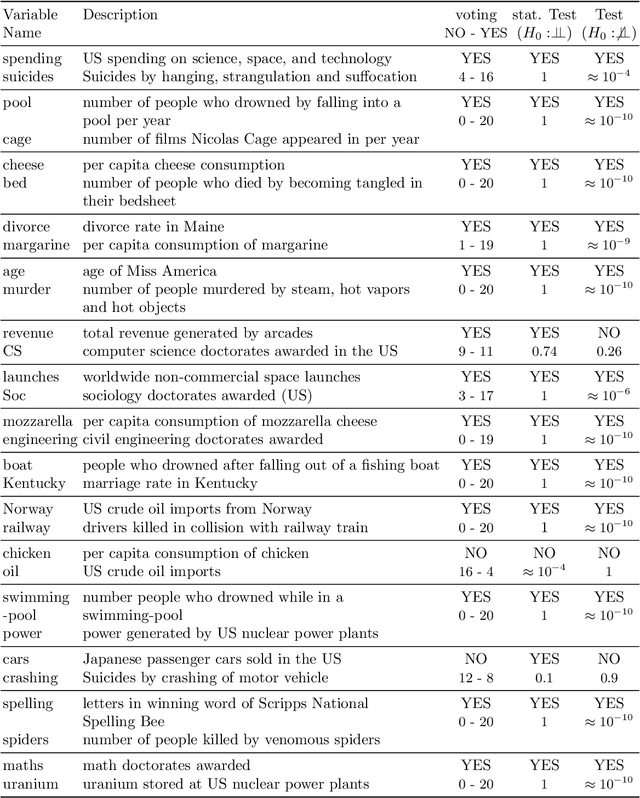
Causality is essential for understanding complex systems, such as the economy, the brain, and the climate. Constructing causal graphs often relies on either data-driven or expert-driven approaches, both fraught with challenges. The former methods, like the celebrated PC algorithm, face issues with data requirements and assumptions of causal sufficiency, while the latter demand substantial time and domain knowledge. This work explores the capabilities of Large Language Models (LLMs) as an alternative to domain experts for causal graph generation. We frame conditional independence queries as prompts to LLMs and employ the PC algorithm with the answers. The performance of the LLM-based conditional independence oracle on systems with known causal graphs shows a high degree of variability. We improve the performance through a proposed statistical-inspired voting schema that allows some control over false-positive and false-negative rates. Inspecting the chain-of-thought argumentation, we find causal reasoning to justify its answer to a probabilistic query. We show evidence that knowledge-based CIT could eventually become a complementary tool for data-driven causal discovery.
Recovering Latent Confounders from High-dimensional Proxy Variables
Mar 21, 2024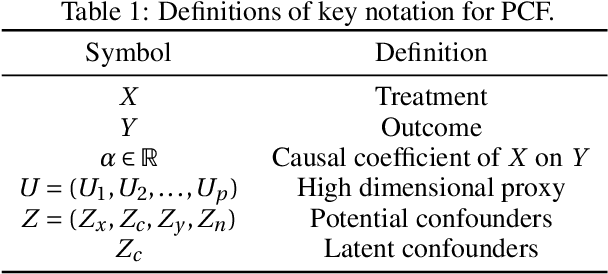
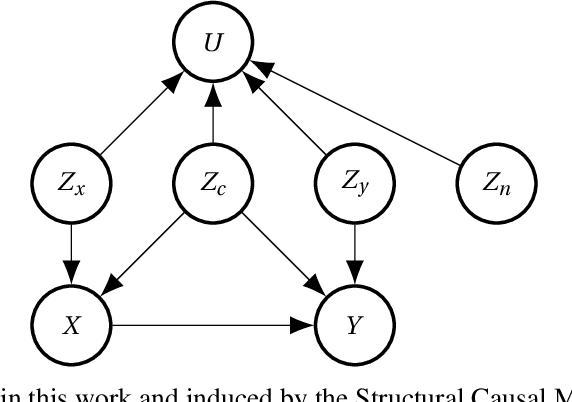
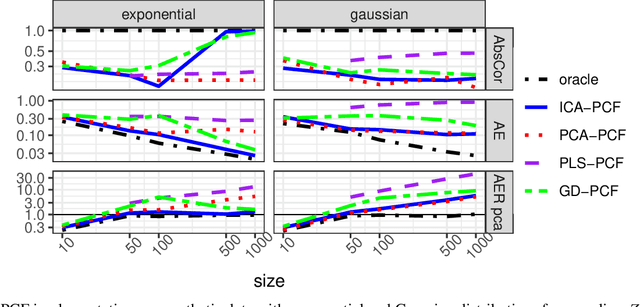

Detecting latent confounders from proxy variables is an essential problem in causal effect estimation. Previous approaches are limited to low-dimensional proxies, sorted proxies, and binary treatments. We remove these assumptions and present a novel Proxy Confounder Factorization (PCF) framework for continuous treatment effect estimation when latent confounders manifest through high-dimensional, mixed proxy variables. For specific sample sizes, our two-step PCF implementation, using Independent Component Analysis (ICA-PCF), and the end-to-end implementation, using Gradient Descent (GD-PCF), achieve high correlation with the latent confounder and low absolute error in causal effect estimation with synthetic datasets in the high sample size regime. Even when faced with climate data, ICA-PCF recovers four components that explain $75.9\%$ of the variance in the North Atlantic Oscillation, a known confounder of precipitation patterns in Europe. Code for our PCF implementations and experiments can be found here: https://github.com/IPL-UV/confound_it. The proposed methodology constitutes a stepping stone towards discovering latent confounders and can be applied to many problems in disciplines dealing with high-dimensional observed proxies, e.g., spatiotemporal fields.
Discovering Causal Relations and Equations from Data
May 21, 2023



Physics is a field of science that has traditionally used the scientific method to answer questions about why natural phenomena occur and to make testable models that explain the phenomena. Discovering equations, laws and principles that are invariant, robust and causal explanations of the world has been fundamental in physical sciences throughout the centuries. Discoveries emerge from observing the world and, when possible, performing interventional studies in the system under study. With the advent of big data and the use of data-driven methods, causal and equation discovery fields have grown and made progress in computer science, physics, statistics, philosophy, and many applied fields. All these domains are intertwined and can be used to discover causal relations, physical laws, and equations from observational data. This paper reviews the concepts, methods, and relevant works on causal and equation discovery in the broad field of Physics and outlines the most important challenges and promising future lines of research. We also provide a taxonomy for observational causal and equation discovery, point out connections, and showcase a complete set of case studies in Earth and climate sciences, fluid dynamics and mechanics, and the neurosciences. This review demonstrates that discovering fundamental laws and causal relations by observing natural phenomena is being revolutionised with the efficient exploitation of observational data, modern machine learning algorithms and the interaction with domain knowledge. Exciting times are ahead with many challenges and opportunities to improve our understanding of complex systems.
Online deforestation detection
Apr 03, 2017
Deforestation detection using satellite images can make an important contribution to forest management. Current approaches can be broadly divided into those that compare two images taken at similar periods of the year and those that monitor changes by using multiple images taken during the growing season. The CMFDA algorithm described in Zhu et al. (2012) is an algorithm that builds on the latter category by implementing a year-long, continuous, time-series based approach to monitoring images. This algorithm was developed for 30m resolution, 16-day frequency reflectance data from the Landsat satellite. In this work we adapt the algorithm to 1km, 16-day frequency reflectance data from the modis sensor aboard the Terra satellite. The CMFDA algorithm is composed of two submodels which are fitted on a pixel-by-pixel basis. The first estimates the amount of surface reflectance as a function of the day of the year. The second estimates the occurrence of a deforestation event by comparing the last few predicted and real reflectance values. For this comparison, the reflectance observations for six different bands are first combined into a forest index. Real and predicted values of the forest index are then compared and high absolute differences for consecutive observation dates are flagged as deforestation events. Our adapted algorithm also uses the two model framework. However, since the modis 13A2 dataset used, includes reflectance data for different spectral bands than those included in the Landsat dataset, we cannot construct the forest index. Instead we propose two contrasting approaches: a multivariate and an index approach similar to that of CMFDA.