 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTMCS-Bench: Evaluating Contextual Safety of Multimodal Large Language Models in Multi-Turn Dialogues
Jan 11, 2026Multimodal large language models (MLLMs) are increasingly deployed as assistants that interact through text and images, making it crucial to evaluate contextual safety when risk depends on both the visual scene and the evolving dialogue. Existing contextual safety benchmarks are mostly single-turn and often miss how malicious intent can emerge gradually or how the same scene can support both benign and exploitative goals. We introduce the Multi-Turn Multimodal Contextual Safety Benchmark (MTMCS-Bench), a benchmark of realistic images and multi-turn conversations that evaluates contextual safety in MLLMs under two complementary settings, escalation-based risk and context-switch risk. MTMCS-Bench offers paired safe and unsafe dialogues with structured evaluation. It contains over 30 thousand multimodal (image+text) and unimodal (text-only) samples, with metrics that separately measure contextual intent recognition, safety-awareness on unsafe cases, and helpfulness on benign ones. Across eight open-source and seven proprietary MLLMs, we observe persistent trade-offs between contextual safety and utility, with models tending to either miss gradual risks or over-refuse benign dialogues. Finally, we evaluate five current guardrails and find that they mitigate some failures but do not fully resolve multi-turn contextual risks.
From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
Dec 12, 2025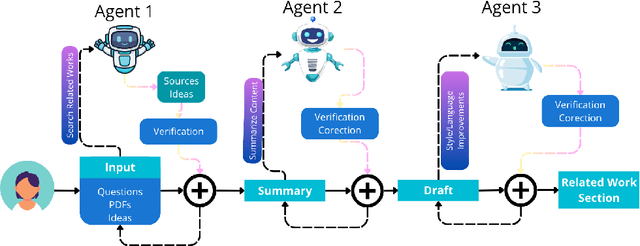
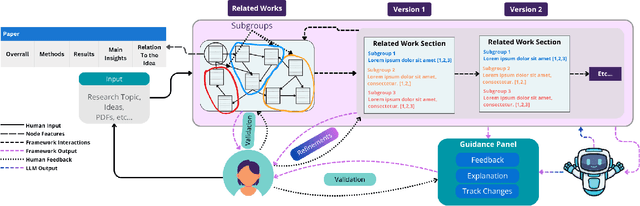
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
Relevance-aware Algorithmic Recourse
May 29, 2024As machine learning continues to gain prominence, transparency and explainability are increasingly critical. Without an understanding of these models, they can replicate and worsen human bias, adversely affecting marginalized communities. Algorithmic recourse emerges as a tool for clarifying decisions made by predictive models, providing actionable insights to alter outcomes. They answer, 'What do I have to change?' to achieve the desired result. Despite their importance, current algorithmic recourse methods treat all domain values equally, which is unrealistic in real-world settings. In this paper, we propose a novel framework, Relevance-Aware Algorithmic Recourse (RAAR), that leverages the concept of relevance in applying algorithmic recourse to regression tasks. We conducted multiple experiments on 15 datasets to outline how relevance influences recourses. Results show that relevance contributes algorithmic recourses comparable to well-known baselines, with greater efficiency and lower relative costs.