 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Preoperative CT to Postmastoidectomy Mesh Construction:1Mastoidectomy Shape Prediction for Cochlear Implant Surgery
Jan 07, 2026Cochlear Implant (CI) surgery treats severe hearing loss by inserting an electrode array into the cochlea to stimulate the auditory nerve. An important step in this procedure is mastoidectomy, which removes part of the mastoid region of the temporal bone to provide surgical access. Accurate mastoidectomy shape prediction from preoperative imaging improves pre-surgical planning, reduces risks, and enhances surgical outcomes. Despite its importance, there are limited deep-learning-based studies regarding this topic due to the challenges of acquiring ground-truth labels. We address this gap by investigating self-supervised and weakly-supervised learning models to predict the mastoidectomy region without human annotations. We propose a hybrid self-supervised and weakly-supervised learning framework to predict the mastoidectomy region directly from preoperative CT scans, where the mastoid remains intact. Our hybrid method achieves a mean Dice score of 0.72 when predicting the complex and boundary-less mastoidectomy shape, surpassing state-of-the-art approaches and demonstrating strong performance. The method provides groundwork for constructing 3D postmastoidectomy surfaces directly from the corresponding preoperative CT scans. To our knowledge, this is the first work that integrating self-supervised and weakly-supervised learning for mastoidectomy shape prediction, offering a robust and efficient solution for CI surgical planning while leveraging 3D T-distribution loss in weakly-supervised medical imaging.
Lifespan Pancreas Morphology for Control vs Type 2 Diabetes using AI on Largescale Clinical Imaging
Aug 20, 2025Purpose: Understanding how the pancreas changes is critical for detecting deviations in type 2 diabetes and other pancreatic disease. We measure pancreas size and shape using morphological measurements from ages 0 to 90. Our goals are to 1) identify reliable clinical imaging modalities for AI-based pancreas measurement, 2) establish normative morphological aging trends, and 3) detect potential deviations in type 2 diabetes. Approach: We analyzed a clinically acquired dataset of 2533 patients imaged with abdominal CT or MRI. We resampled the scans to 3mm isotropic resolution, segmented the pancreas using automated methods, and extracted 13 morphological pancreas features across the lifespan. First, we assessed CT and MRI measurements to determine which modalities provide consistent lifespan trends. Second, we characterized distributions of normative morphological patterns stratified by age group and sex. Third, we used GAMLSS regression to model pancreas morphology trends in 1350 patients matched for age, sex, and type 2 diabetes status to identify any deviations from normative aging associated with type 2 diabetes. Results: When adjusting for confounders, the aging trends for 10 of 13 morphological features were significantly different between patients with type 2 diabetes and non-diabetic controls (p < 0.05 after multiple comparisons corrections). Additionally, MRI appeared to yield different pancreas measurements than CT using our AI-based method. Conclusions: We provide lifespan trends demonstrating that the size and shape of the pancreas is altered in type 2 diabetes using 675 control patients and 675 diabetes patients. Moreover, our findings reinforce that the pancreas is smaller in type 2 diabetes. Additionally, we contribute a reference of lifespan pancreas morphology from a large cohort of non-diabetic control patients in a clinical setting.
Unsupervised Mastoidectomy for Cochlear CT Mesh Reconstruction Using Highly Noisy Data
Jul 22, 2024Cochlear Implant (CI) procedures involve inserting an array of electrodes into the cochlea located inside the inner ear. Mastoidectomy is a surgical procedure that uses a high-speed drill to remove part of the mastoid region of the temporal bone, providing safe access to the cochlea through the middle and inner ear. We aim to develop an intraoperative navigation system that registers plans created using 3D preoperative Computerized Tomography (CT) volumes with the 2D surgical microscope view. Herein, we propose a method to synthesize the mastoidectomy volume using only the preoperative CT scan, where the mastoid is intact. We introduce an unsupervised learning framework designed to synthesize mastoidectomy. For model training purposes, this method uses postoperative CT scans to avoid manual data cleaning or labeling, even when the region removed during mastoidectomy is visible but affected by metal artifacts, low signal-to-noise ratio, or electrode wiring. Our approach estimates mastoidectomy regions with a mean dice score of 70.0%. This approach represents a major step forward for CI intraoperative navigation by predicting realistic mastoidectomy-removed regions in preoperative planning that can be used to register the pre-surgery plan to intraoperative microscopy.
Monocular Microscope to CT Registration using Pose Estimation of the Incus for Augmented Reality Cochlear Implant Surgery
Mar 12, 2024For those experiencing severe-to-profound sensorineural hearing loss, the cochlear implant (CI) is the preferred treatment. Augmented reality (AR) aided surgery can potentially improve CI procedures and hearing outcomes. Typically, AR solutions for image-guided surgery rely on optical tracking systems to register pre-operative planning information to the display so that hidden anatomy or other important information can be overlayed and co-registered with the view of the surgical scene. In this paper, our goal is to develop a method that permits direct 2D-to-3D registration of the microscope video to the pre-operative Computed Tomography (CT) scan without the need for external tracking equipment. Our proposed solution involves using surface mapping of a portion of the incus in surgical recordings and determining the pose of this structure relative to the surgical microscope by performing pose estimation via the perspective-n-point (PnP) algorithm. This registration can then be applied to pre-operative segmentations of other anatomy-of-interest, as well as the planned electrode insertion trajectory to co-register this information for the AR display. Our results demonstrate the accuracy with an average rotation error of less than 25 degrees and a translation error of less than 2 mm, 3 mm, and 0.55% for the x, y, and z axes, respectively. Our proposed method has the potential to be applicable and generalized to other surgical procedures while only needing a monocular microscope during intra-operation.
Unsupervised Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation via Semi-supervised Learning and Label Fusion
Jan 25, 2022

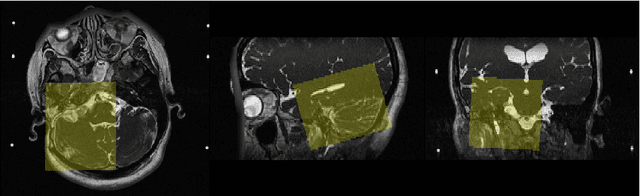

Automatic methods to segment the vestibular schwannoma (VS) tumors and the cochlea from magnetic resonance imaging (MRI) are critical to VS treatment planning. Although supervised methods have achieved satisfactory performance in VS segmentation, they require full annotations by experts, which is laborious and time-consuming. In this work, we aim to tackle the VS and cochlea segmentation problem in an unsupervised domain adaptation setting. Our proposed method leverages both the image-level domain alignment to minimize the domain divergence and semi-supervised training to further boost the performance. Furthermore, we propose to fuse the labels predicted from multiple models via noisy label correction. In the MICCAI 2021 crossMoDA challenge, our results on the final evaluation leaderboard showed that our proposed method has achieved promising segmentation performance with mean dice score of 79.9% and 82.5% and ASSD of 1.29 mm and 0.18 mm for VS tumor and cochlea, respectively. The cochlea ASSD achieved by our method has outperformed all other competing methods as well as the supervised nnU-Net.
Cross-Modality Domain Adaptation for Vestibular Schwannoma and Cochlea Segmentation
Sep 21, 2021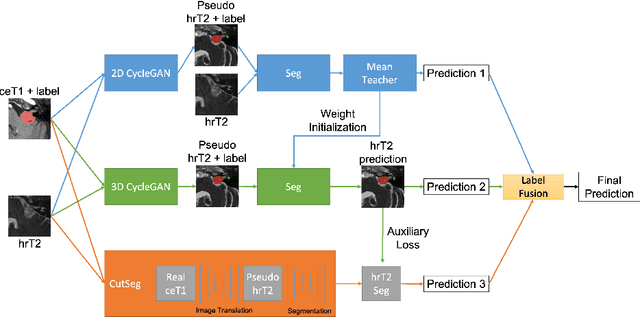


Automatic methods to segment the vestibular schwannoma (VS) tumors and the cochlea from magnetic resonance imaging (MRI) are critical to VS treatment planning. Although supervised methods have achieved satisfactory performance in VS segmentation, they require full annotations by experts, which is laborious and time-consuming. In this work, we aim to tackle the VS and cochlea segmentation problem in an unsupervised domain adaptation setting. Our proposed method leverages both the image-level domain alignment to minimize the domain divergence and semi-supervised training to further boost the performance. Furthermore, we propose to fuse the labels predicted from multiple models via noisy label correction. Our results on the challenge validation leaderboard showed that our unsupervised method has achieved promising VS and cochlea segmentation performance with mean dice score of 0.8261 $\pm$ 0.0416; The mean dice value for the tumor is 0.8302 $\pm$ 0.0772. This is comparable to the weakly-supervised based method.
Atlas-Based Segmentation of Intracochlear Anatomy in Metal Artifact Affected CT Images of the Ear with Co-trained Deep Neural Networks
Jul 09, 2021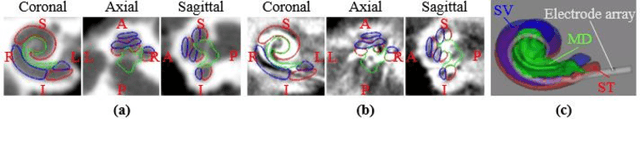
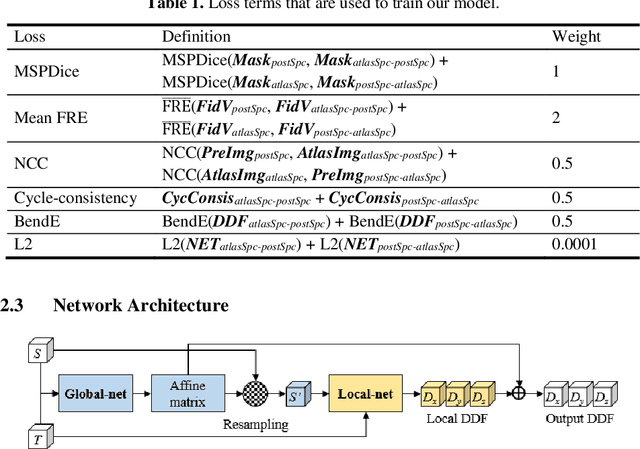
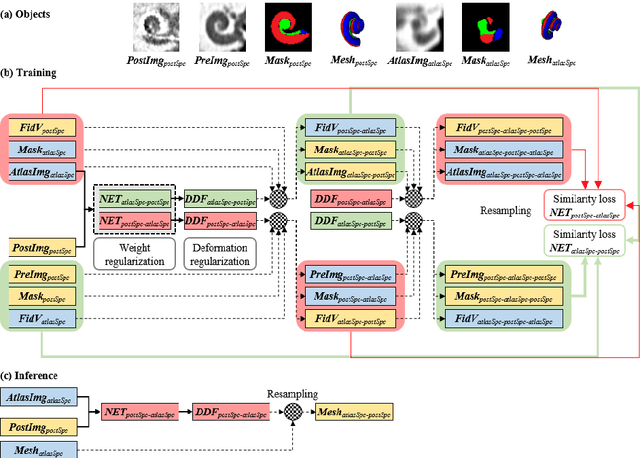
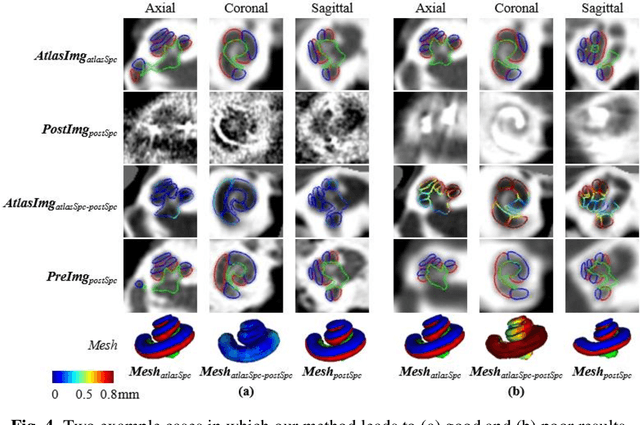
We propose an atlas-based method to segment the intracochlear anatomy (ICA) in the post-implantation CT (Post-CT) images of cochlear implant (CI) recipients that preserves the point-to-point correspondence between the meshes in the atlas and the segmented volumes. To solve this problem, which is challenging because of the strong artifacts produced by the implant, we use a pair of co-trained deep networks that generate dense deformation fields (DDFs) in opposite directions. One network is tasked with registering an atlas image to the Post-CT images and the other network is tasked with registering the Post-CT images to the atlas image. The networks are trained using loss functions based on voxel-wise labels, image content, fiducial registration error, and cycle-consistency constraint. The segmentation of the ICA in the Post-CT images is subsequently obtained by transferring the predefined segmentation meshes of the ICA in the atlas image to the Post-CT images using the corresponding DDFs generated by the trained registration networks. Our model can learn the underlying geometric features of the ICA even though they are obscured by the metal artifacts. We show that our end-to-end network produces results that are comparable to the current state of the art (SOTA) that relies on a two-steps approach that first uses conditional generative adversarial networks to synthesize artifact-free images from the Post-CT images and then uses an active shape model-based method to segment the ICA in the synthetic images. Our method requires a fraction of the time needed by the SOTA, which is important for end-user acceptance.