 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Parameter-Free Learning of Multiple Low Variance Tasks
Jul 11, 2020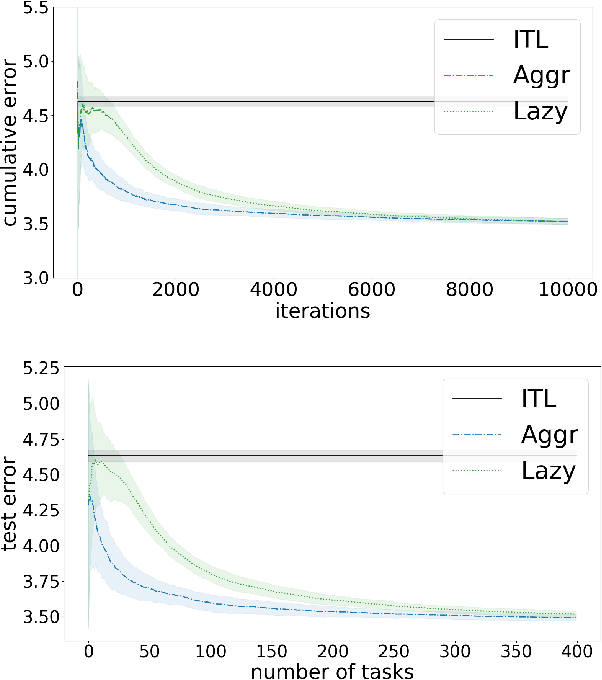
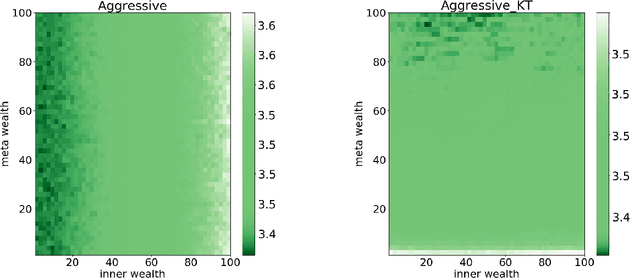
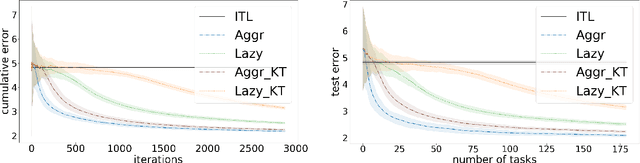
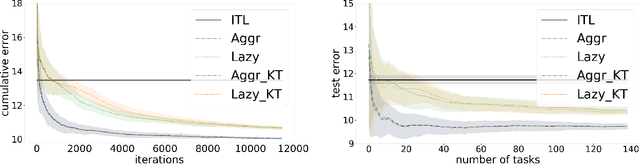
We propose a method to learn a common bias vector for a growing sequence of low-variance tasks. Unlike state-of-the-art approaches, our method does not require tuning any hyper-parameter. Our approach is presented in the non-statistical setting and can be of two variants. The "aggressive" one updates the bias after each datapoint, the "lazy" one updates the bias only at the end of each task. We derive an across-tasks regret bound for the method. When compared to state-of-the-art approaches, the aggressive variant returns faster rates, the lazy one recovers standard rates, but with no need of tuning hyper-parameters. We then adapt the methods to the statistical setting: the aggressive variant becomes a multi-task learning method, the lazy one a meta-learning method. Experiments confirm the effectiveness of our methods in practice.
Leveraging Low-Rank Relations Between Surrogate Tasks in Structured Prediction
Mar 02, 2019
We study the interplay between surrogate methods for structured prediction and techniques from multitask learning designed to leverage relationships between surrogate outputs. We propose an efficient algorithm based on trace norm regularization which, differently from previous methods, does not require explicit knowledge of the coding/decoding functions of the surrogate framework. As a result, our algorithm can be applied to the broad class of problems in which the surrogate space is large or even infinite dimensional. We study excess risk bounds for trace norm regularized structured prediction, implying the consistency and learning rates for our estimator. We also identify relevant regimes in which our approach can enjoy better generalization performance than previous methods. Numerical experiments on ranking problems indicate that enforcing low-rank relations among surrogate outputs may indeed provide a significant advantage in practice.
Incremental Learning-to-Learn with Statistical Guarantees
Mar 21, 2018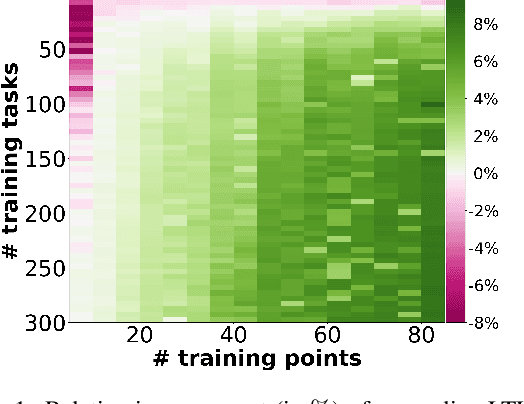

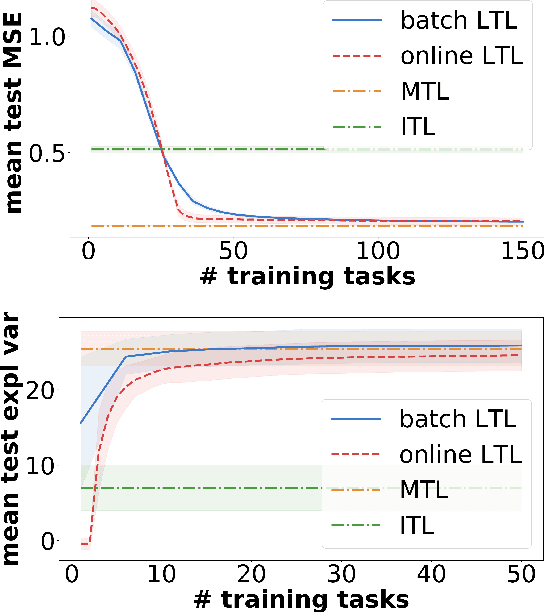
In learning-to-learn the goal is to infer a learning algorithm that works well on a class of tasks sampled from an unknown meta distribution. In contrast to previous work on batch learning-to-learn, we consider a scenario where tasks are presented sequentially and the algorithm needs to adapt incrementally to improve its performance on future tasks. Key to this setting is for the algorithm to rapidly incorporate new observations into the model as they arrive, without keeping them in memory. We focus on the case where the underlying algorithm is ridge regression parameterized by a positive semidefinite matrix. We propose to learn this matrix by applying a stochastic strategy to minimize the empirical error incurred by ridge regression on future tasks sampled from the meta distribution. We study the statistical properties of the proposed algorithm and prove non-asymptotic bounds on its excess transfer risk, that is, the generalization performance on new tasks from the same meta distribution. We compare our online learning-to-learn approach with a state of the art batch method, both theoretically and empirically.
Reexamining Low Rank Matrix Factorization for Trace Norm Regularization
Jul 31, 2017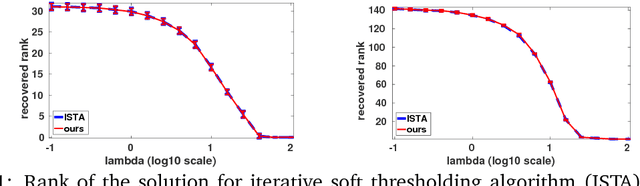

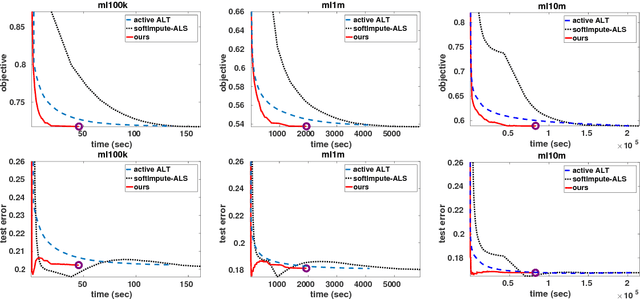
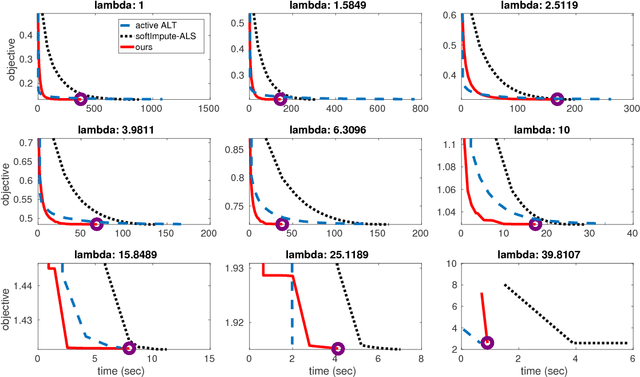
Trace norm regularization is a widely used approach for learning low rank matrices. A standard optimization strategy is based on formulating the problem as one of low rank matrix factorization which, however, leads to a non-convex problem. In practice this approach works well, and it is often computationally faster than standard convex solvers such as proximal gradient methods. Nevertheless, it is not guaranteed to converge to a global optimum, and the optimization can be trapped at poor stationary points. In this paper we show that it is possible to characterize all critical points of the non-convex problem. This allows us to provide an efficient criterion to determine whether a critical point is also a global minimizer. Our analysis suggests an iterative meta-algorithm that dynamically expands the parameter space and allows the optimization to escape any non-global critical point, thereby converging to a global minimizer. The algorithm can be applied to problems such as matrix completion or multitask learning, and our analysis holds for any random initialization of the factor matrices. Finally, we confirm the good performance of the algorithm on synthetic and real datasets.
Fitting Spectral Decay with the $k$-Support Norm
Jan 04, 2016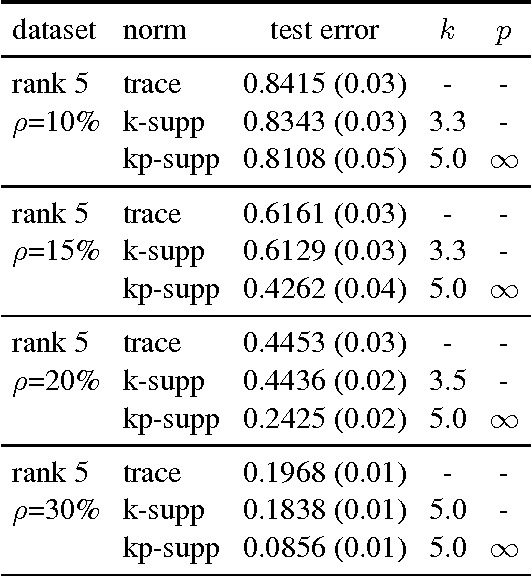
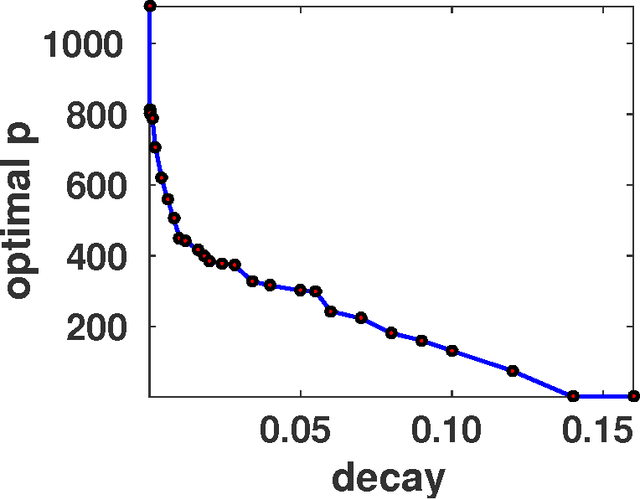
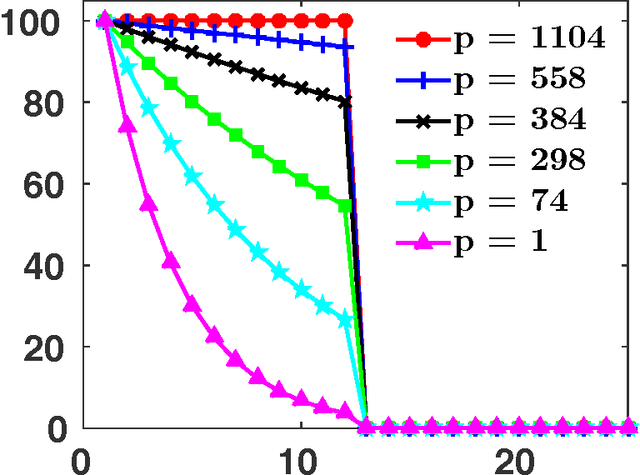

The spectral $k$-support norm enjoys good estimation properties in low rank matrix learning problems, empirically outperforming the trace norm. Its unit ball is the convex hull of rank $k$ matrices with unit Frobenius norm. In this paper we generalize the norm to the spectral $(k,p)$-support norm, whose additional parameter $p$ can be used to tailor the norm to the decay of the spectrum of the underlying model. We characterize the unit ball and we explicitly compute the norm. We further provide a conditional gradient method to solve regularization problems with the norm, and we derive an efficient algorithm to compute the Euclidean projection on the unit ball in the case $p=\infty$. In numerical experiments, we show that allowing $p$ to vary significantly improves performance over the spectral $k$-support norm on various matrix completion benchmarks, and better captures the spectral decay of the underlying model.
New Perspectives on $k$-Support and Cluster Norms
Dec 27, 2015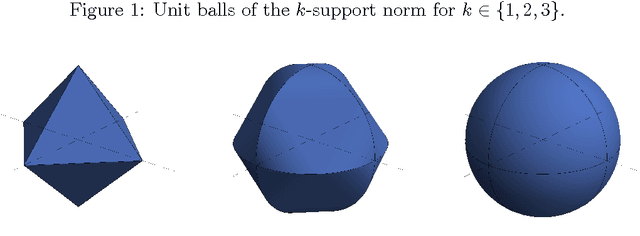

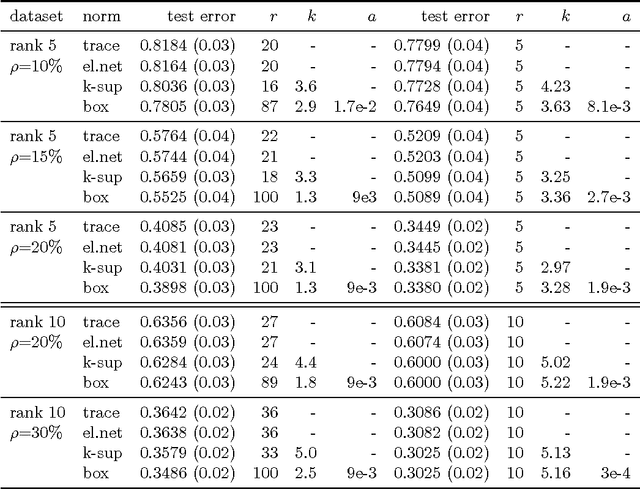

We study a regularizer which is defined as a parameterized infimum of quadratics, and which we call the box-norm. We show that the k-support norm, a regularizer proposed by [Argyriou et al, 2012] for sparse vector prediction problems, belongs to this family, and the box-norm can be generated as a perturbation of the former. We derive an improved algorithm to compute the proximity operator of the squared box-norm, and we provide a method to compute the norm. We extend the norms to matrices, introducing the spectral k-support norm and spectral box-norm. We note that the spectral box-norm is essentially equivalent to the cluster norm, a multitask learning regularizer introduced by [Jacob et al. 2009a], and which in turn can be interpreted as a perturbation of the spectral k-support norm. Centering the norm is important for multitask learning and we also provide a method to use centered versions of the norms as regularizers. Numerical experiments indicate that the spectral k-support and box-norms and their centered variants provide state of the art performance in matrix completion and multitask learning problems respectively.
New Perspectives on k-Support and Cluster Norms
Mar 06, 2014The $k$-support norm is a regularizer which has been successfully applied to sparse vector prediction problems. We show that it belongs to a general class of norms which can be formulated as a parameterized infimum over quadratics. We further extend the $k$-support norm to matrices, and we observe that it is a special case of the matrix cluster norm. Using this formulation we derive an efficient algorithm to compute the proximity operator of both norms. This improves upon the standard algorithm for the $k$-support norm and allows us to apply proximal gradient methods to the cluster norm. We also describe how to solve regularization problems which employ centered versions of these norms. Finally, we apply the matrix regularizers to different matrix completion and multitask learning datasets. Our results indicate that the spectral $k$-support norm and the cluster norm give state of the art performance on these problems, significantly outperforming trace norm and elastic net penalties.