 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Parameter-Free Learning of Multiple Low Variance Tasks
Paper and Code
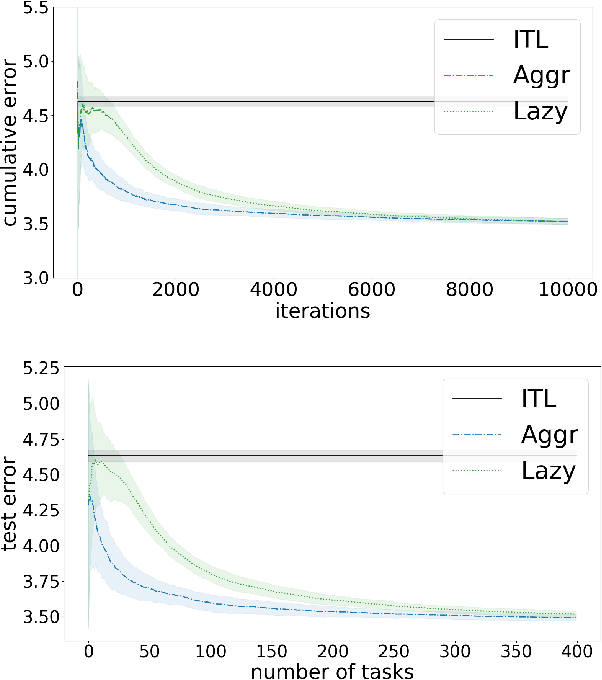
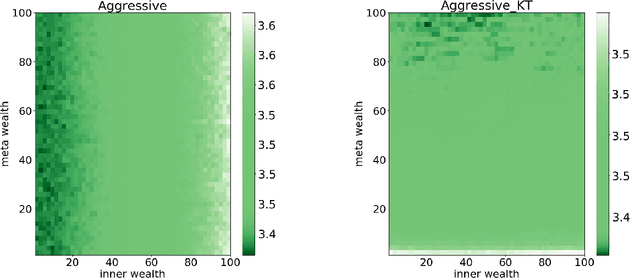
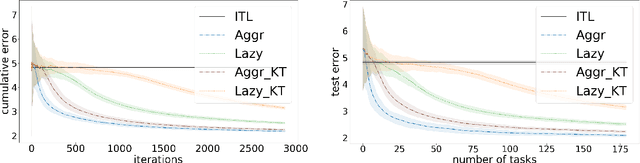
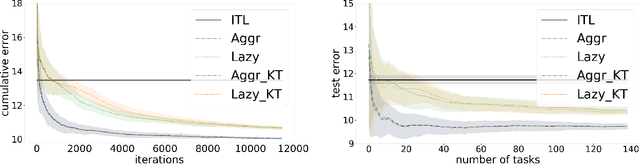
We propose a method to learn a common bias vector for a growing sequence of low-variance tasks. Unlike state-of-the-art approaches, our method does not require tuning any hyper-parameter. Our approach is presented in the non-statistical setting and can be of two variants. The "aggressive" one updates the bias after each datapoint, the "lazy" one updates the bias only at the end of each task. We derive an across-tasks regret bound for the method. When compared to state-of-the-art approaches, the aggressive variant returns faster rates, the lazy one recovers standard rates, but with no need of tuning hyper-parameters. We then adapt the methods to the statistical setting: the aggressive variant becomes a multi-task learning method, the lazy one a meta-learning method. Experiments confirm the effectiveness of our methods in practice.