 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotated Biomedical Video Generation using Denoising Diffusion Probabilistic Models and Flow Fields
Mar 26, 2024



The segmentation and tracking of living cells play a vital role within the biomedical domain, particularly in cancer research, drug development, and developmental biology. These are usually tedious and time-consuming tasks that are traditionally done by biomedical experts. Recently, to automatize these processes, deep learning based segmentation and tracking methods have been proposed. These methods require large-scale datasets and their full potential is constrained by the scarcity of annotated data in the biomedical imaging domain. To address this limitation, we propose Biomedical Video Diffusion Model (BVDM), capable of generating realistic-looking synthetic microscopy videos. Trained only on a single real video, BVDM can generate videos of arbitrary length with pixel-level annotations that can be used for training data-hungry models. It is composed of a denoising diffusion probabilistic model (DDPM) generating high-fidelity synthetic cell microscopy images and a flow prediction model (FPM) predicting the non-rigid transformation between consecutive video frames. During inference, initially, the DDPM imposes realistic cell textures on synthetic cell masks which are generated based on real data statistics. The flow prediction model predicts the flow field between consecutive masks and applies that to the DDPM output from the previous time frame to create the next one while keeping temporal consistency. BVDM outperforms state-of-the-art synthetic live cell microscopy video generation models. Furthermore, we demonstrate that a sufficiently large synthetic dataset enhances the performance of cell segmentation and tracking models compared to using a limited amount of available real data.
Retinal OCT Synthesis with Denoising Diffusion Probabilistic Models for Layer Segmentation
Nov 09, 2023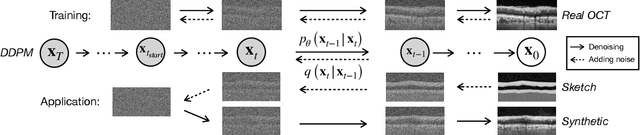
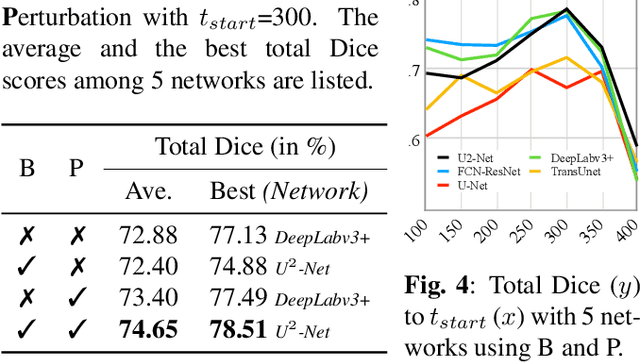

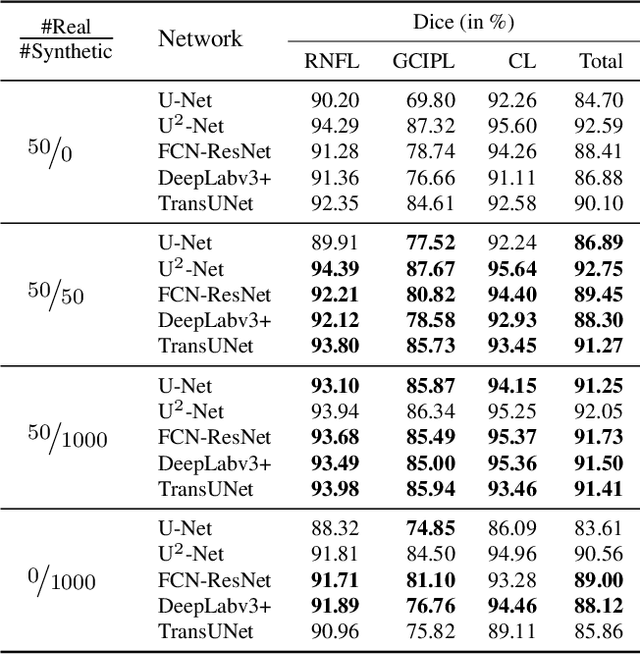
Modern biomedical image analysis using deep learning often encounters the challenge of limited annotated data. To overcome this issue, deep generative models can be employed to synthesize realistic biomedical images. In this regard, we propose an image synthesis method that utilizes denoising diffusion probabilistic models (DDPMs) to automatically generate retinal optical coherence tomography (OCT) images. By providing rough layer sketches, the trained DDPMs can generate realistic circumpapillary OCT images. We further find that more accurate pseudo labels can be obtained through knowledge adaptation, which greatly benefits the segmentation task. Through this, we observe a consistent improvement in layer segmentation accuracy, which is validated using various neural networks. Furthermore, we have discovered that a layer segmentation model trained solely with synthesized images can achieve comparable results to a model trained exclusively with real images. These findings demonstrate the promising potential of DDPMs in reducing the need for manual annotations of retinal OCT images.
Semi- and Self-Supervised Multi-View Fusion of 3D Microscopy Images using Generative Adversarial Networks
Aug 05, 2021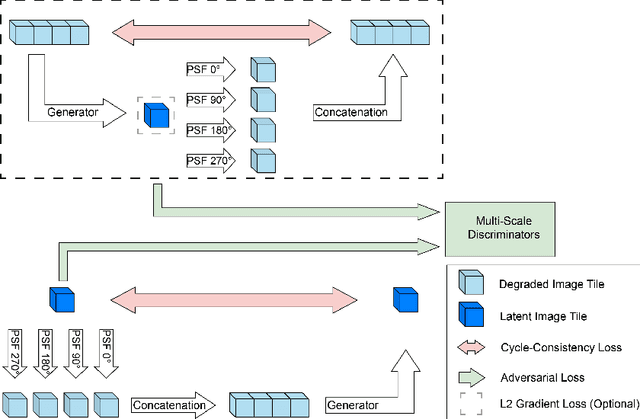
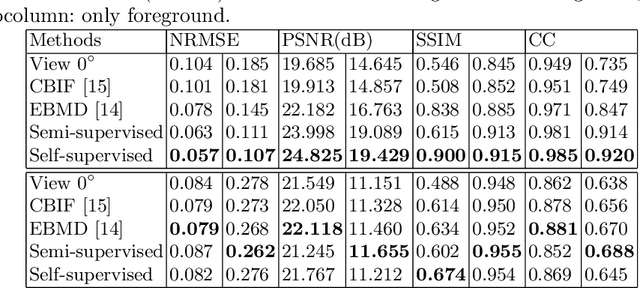
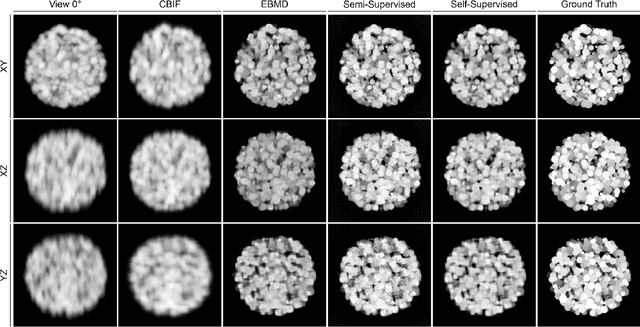
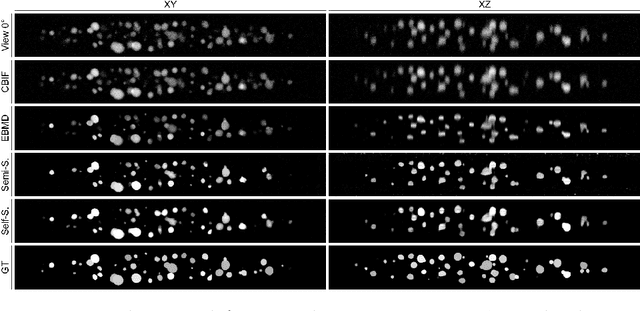
Recent developments in fluorescence microscopy allow capturing high-resolution 3D images over time for living model organisms. To be able to image even large specimens, techniques like multi-view light-sheet imaging record different orientations at each time point that can then be fused into a single high-quality volume. Based on measured point spread functions (PSF), deconvolution and content fusion are able to largely revert the inevitable degradation occurring during the imaging process. Classical multi-view deconvolution and fusion methods mainly use iterative procedures and content-based averaging. Lately, Convolutional Neural Networks (CNNs) have been deployed to approach 3D single-view deconvolution microscopy, but the multi-view case waits to be studied. We investigated the efficacy of CNN-based multi-view deconvolution and fusion with two synthetic data sets that mimic developing embryos and involve either two or four complementary 3D views. Compared with classical state-of-the-art methods, the proposed semi- and self-supervised models achieve competitive and superior deconvolution and fusion quality in the two-view and quad-view cases, respectively.
3D fluorescence microscopy data synthesis for segmentation and benchmarking
Jul 21, 2021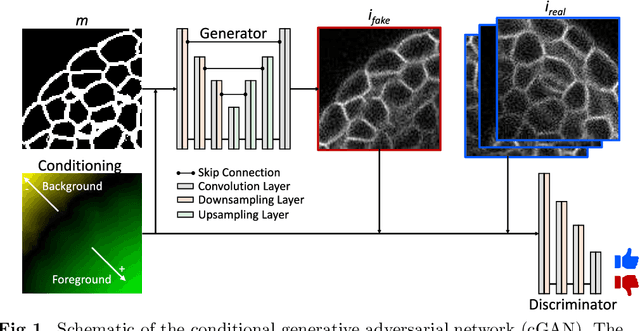
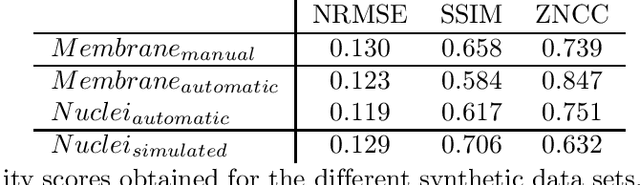
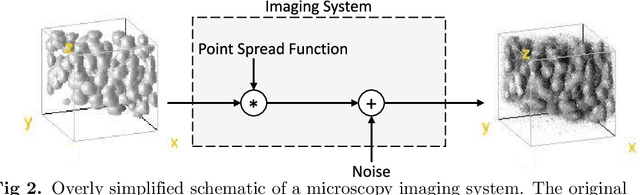
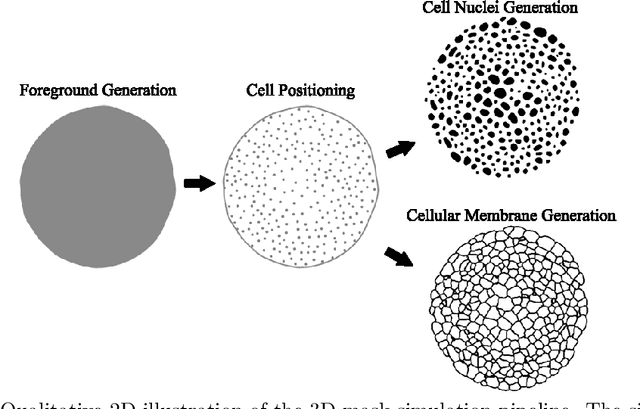
Automated image processing approaches are indispensable for many biomedical experiments and help to cope with the increasing amount of microscopy image data in a fast and reproducible way. Especially state-of-the-art deep learning-based approaches most often require large amounts of annotated training data to produce accurate and generalist outputs, but they are often compromised by the general lack of those annotated data sets. In this work, we propose how conditional generative adversarial networks can be utilized to generate realistic image data for 3D fluorescence microscopy from annotation masks of 3D cellular structures. In combination with mask simulation approaches, we demonstrate the generation of fully-annotated 3D microscopy data sets that we make publicly available for training or benchmarking. An additional positional conditioning of the cellular structures enables the reconstruction of position-dependent intensity characteristics and allows to generate image data of different quality levels. A patch-wise working principle and a subsequent full-size reassemble strategy is used to generate image data of arbitrary size and different organisms. We present this as a proof-of-concept for the automated generation of fully-annotated training data sets requiring only a minimum of manual interaction to alleviate the need of manual annotations.
Robust 3D Cell Segmentation: Extending the View of Cellpose
May 03, 2021



Increasing data set sizes of digital microscopy imaging experiments demand for an automation of segmentation processes to be able to extract meaningful biomedical information. Due to the shortage of annotated 3D image data that can be used for machine learning-based approaches, 3D segmentation approaches are required to be robust and to generalize well to unseen data. Reformulating the problem of instance segmentation as a collection of diffusion gradient maps, proved to be such a generalist approach for cell segmentation tasks. In this paper, we extend the Cellpose approach to improve segmentation accuracy on 3D image data and we further show how the formulation of the gradient maps can be simplified while still being robust and reaching similar segmentation accuracy. We quantitatively compared different experimental setups and validated on two different data sets of 3D confocal microscopy images of A. thaliana.
Spherical Harmonics for Shape-Constrained 3D Cell Segmentation
Oct 23, 2020
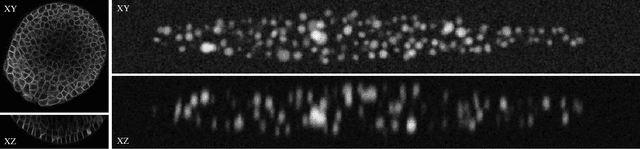
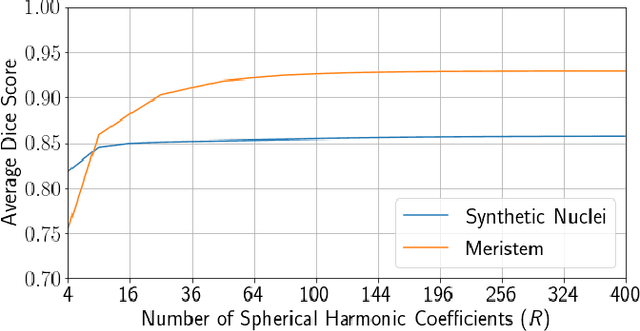
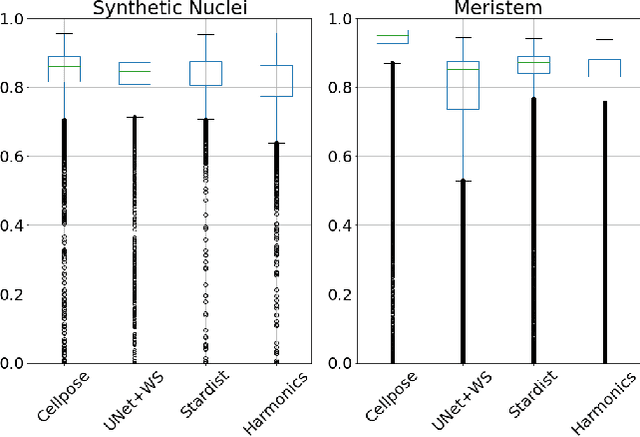
Recent microscopy imaging techniques allow to precisely analyze cell morphology in 3D image data. To process the vast amount of image data generated by current digitized imaging techniques, automated approaches are demanded more than ever. Segmentation approaches used for morphological analyses, however, are often prone to produce unnaturally shaped predictions, which in conclusion could lead to inaccurate experimental outcomes. In order to minimize further manual interaction, shape priors help to constrain the predictions to the set of natural variations. In this paper, we show how spherical harmonics can be used as an alternative way to inherently constrain the predictions of neural networks for the segmentation of cells in 3D microscopy image data. Benefits and limitations of the spherical harmonic representation are analyzed and final results are compared to other state-of-the-art approaches on two different data sets.
CellCycleGAN: Spatiotemporal Microscopy Image Synthesis of Cell Populations using Statistical Shape Models and Conditional GANs
Oct 22, 2020
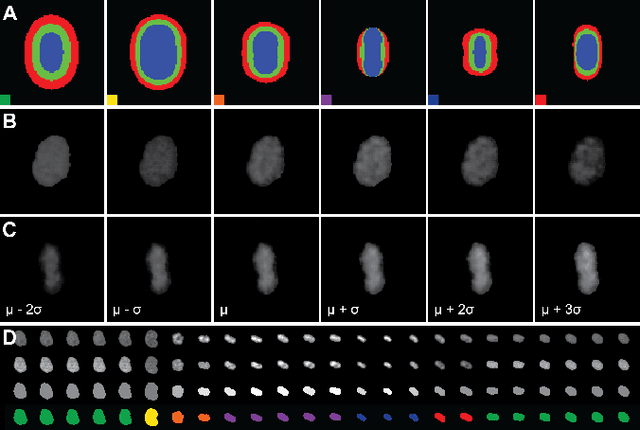
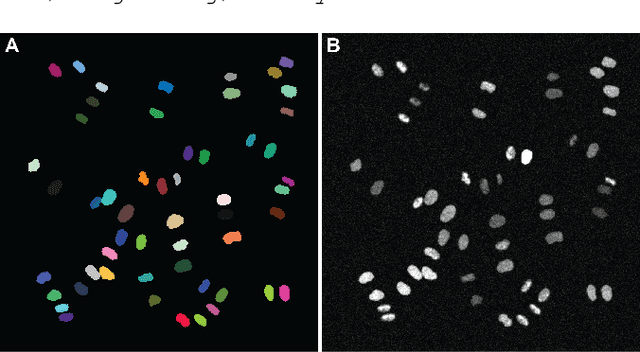
Automatic analysis of spatio-temporal microscopy images is inevitable for state-of-the-art research in the life sciences. Recent developments in deep learning provide powerful tools for automatic analyses of such image data, but heavily depend on the amount and quality of provided training data to perform well. To this end, we developed a new method for realistic generation of synthetic 2D+t microscopy image data of fluorescently labeled cellular nuclei. The method combines spatiotemporal statistical shape models of different cell cycle stages with a conditional GAN to generate time series of cell populations and provides instance-level control of cell cycle stage and the fluorescence intensity of generated cells. We show the effect of the GAN conditioning and create a set of synthetic images that can be readily used for training and benchmarking of cell segmentation and tracking approaches.
Algorithms used for the Cell Segmentation Benchmark Competition at ISBI 2019 by RWTH-GE
Apr 15, 2019The presented algorithms for segmentation and tracking follow a 3-step approach where we detect, track and finally segment nuclei. In the preprocessing phase, we detect centroids of the cell nuclei using a convolutional neural network (CNN) for the 2D images and a Laplacian-of-Gaussian Scale Space Maximum Projection approach for the 3D data sets. Tracking was performed in a backwards fashion on the predicted seed points, i.e., starting at the last frame and sequentially connecting corresponding objects until the first frame was reached. Correspondences were identified by propagating detections of a frame t to its preceding frame t-1 and by combining redundant detections using a hierarchical clustering approach. The tracked centroids were then used as input to variants of the seeded watershed algorithm to obtain the final segmentation.
CNN-based Preprocessing to Optimize Watershed-based Cell Segmentation in 3D Confocal Microscopy Images
Oct 16, 2018
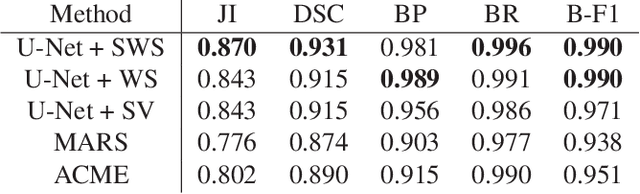
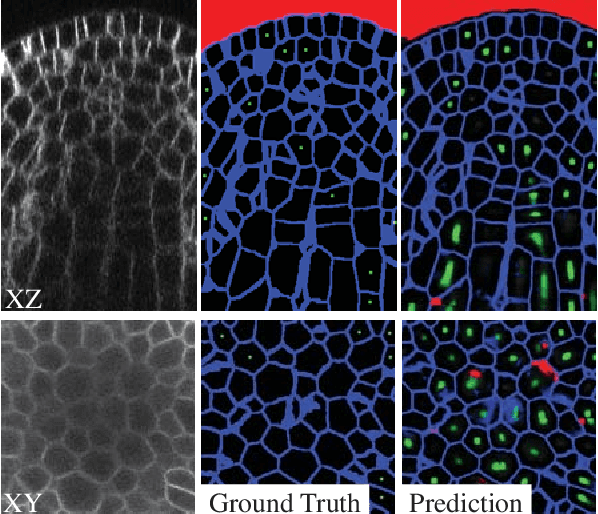

The quantitative analysis of cellular membranes helps understanding developmental processes at the cellular level. Particularly 3D microscopic image data offers valuable insights into cell dynamics, but error-free automatic segmentation remains challenging due to the huge amount of data generated and strong variations in image intensities. In this paper, we propose a new 3D segmentation approach which combines the discriminative power of convolutional neural networks (CNNs) for preprocessing and investigates the performance of three watershed-based postprocessing strategies (WS), which are well suited to segment object shapes, even when supplied with vague seed and boundary constraints. To leverage the full potential of the watershed algorithm, the multi-instance segmentation problem is initially interpreted as three-class semantic segmentation problem, which in turn is well-suited for the application of CNNs. Using manually annotated 3D confocal microscopy images of Arabidopsis thaliana, we show the superior performance of the proposed method compared to the state of the art.