 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Stimulus Encoding for Retinal Implants via Sparse Projected Gradient Descent
Feb 11, 2026Retinal implants aim to restore functional vision despite photoreceptor degeneration, yet are fundamentally constrained by low resolution electrode arrays and patient-specific perceptual distortions. Most deployed encoders rely on task-agnostic downsampling and linear brightness-to-amplitude mappings, which are suboptimal under realistic perceptual models. While global inverse problems have been formulated as neural networks, such approaches can be fast at inference, and can achieve high reconstruction fidelity, but require training and have limited generalizability to arbitrary inputs. We cast stimulus encoding as a constrained sparse least-squares problem under a linearized perceptual forward model. Our key observation is that the resulting perception matrix can be highly sparse, depending on patient and implant configuration. Building on this, we apply an efficient projected residual norm steepest descent solver that exploits sparsity and supports stimulus bounds via projection. In silico experiments across four simulated patients and implant resolutions from $15\times15$ to $100\times100$ electrodes demonstrate improved reconstruction fidelity, with up to $+0.265$ SSIM increase, $+12.4\,\mathrm{dB}$ PSNR, and $81.4\%$ MAE reduction on Fashion-MNIST compared to Lanczos downsampling.
A Pragmatic Note on Evaluating Generative Models with Fréchet Inception Distance for Retinal Image Synthesis
Feb 26, 2025Fr\'echet Inception Distance (FID), computed with an ImageNet pretrained Inception-v3 network, is widely used as a state-of-the-art evaluation metric for generative models. It assumes that feature vectors from Inception-v3 follow a multivariate Gaussian distribution and calculates the 2-Wasserstein distance based on their means and covariances. While FID effectively measures how closely synthetic data match real data in many image synthesis tasks, the primary goal in biomedical generative models is often to enrich training datasets ideally with corresponding annotations. For this purpose, the gold standard for evaluating generative models is to incorporate synthetic data into downstream task training, such as classification and segmentation, to pragmatically assess its performance. In this paper, we examine cases from retinal imaging modalities, including color fundus photography and optical coherence tomography, where FID and its related metrics misalign with task-specific evaluation goals in classification and segmentation. We highlight the limitations of using various metrics, represented by FID and its variants, as evaluation criteria for these applications and address their potential caveats in broader biomedical imaging modalities and downstream tasks.
Visual Fixation-Based Retinal Prosthetic Simulation
Oct 15, 2024
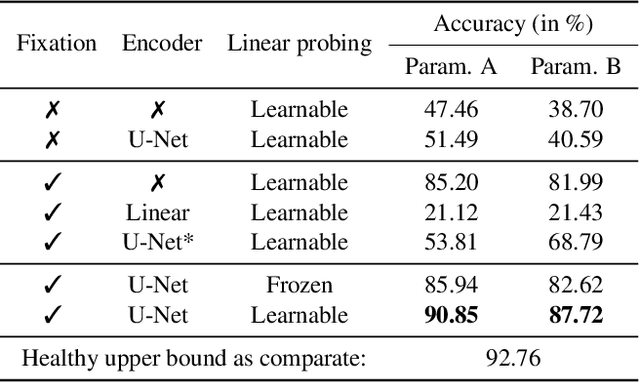
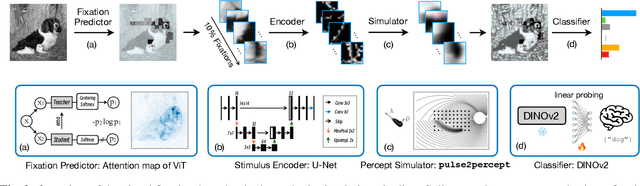
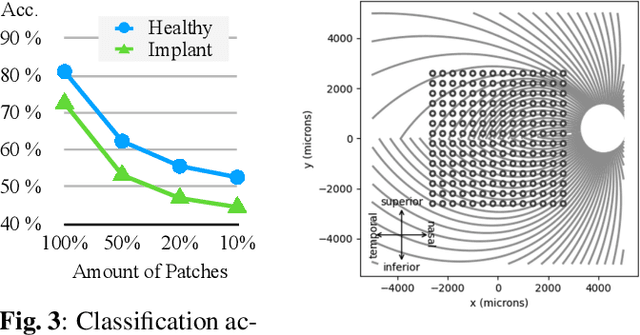
This study proposes a retinal prosthetic simulation framework driven by visual fixations, inspired by the saccade mechanism, and assesses performance improvements through end-to-end optimization in a classification task. Salient patches are predicted from input images using the self-attention map of a vision transformer to mimic visual fixations. These patches are then encoded by a trainable U-Net and simulated using the pulse2percept framework to predict visual percepts. By incorporating a learnable encoder, we aim to optimize the visual information transmitted to the retinal implant, addressing both the limited resolution of the electrode array and the distortion between the input stimuli and resulting phosphenes. The predicted percepts are evaluated using the self-supervised DINOv2 foundation model, with an optional learnable linear layer for classification accuracy. On a subset of the ImageNet validation set, the fixation-based framework achieves a classification accuracy of 87.72%, using computational parameters based on a real subject's physiological data, significantly outperforming the downsampling-based accuracy of 40.59% and approaching the healthy upper bound of 92.76%. Our approach shows promising potential for producing more semantically understandable percepts with the limited resolution available in retinal prosthetics.
Optimizing Retinal Prosthetic Stimuli with Conditional Invertible Neural Networks
Mar 07, 2024Implantable retinal prostheses offer a promising solution to restore partial vision by circumventing damaged photoreceptor cells in the retina and directly stimulating the remaining functional retinal cells. However, the information transmission between the camera and retinal cells is often limited by the low resolution of the electrode array and the lack of specificity for different ganglion cell types, resulting in suboptimal stimulations. In this work, we propose to utilize normalizing flow-based conditional invertible neural networks to optimize retinal implant stimulation in an unsupervised manner. The invertibility of these networks allows us to use them as a surrogate for the computational model of the visual system, while also encoding input camera signals into optimized electrical stimuli on the electrode array. Compared to other methods, such as trivial downsampling, linear models, and feed-forward convolutional neural networks, the flow-based invertible neural network and its conditional extension yield better visual reconstruction qualities w.r.t. various metrics using a physiologically validated simulation tool.
Retinal OCT Synthesis with Denoising Diffusion Probabilistic Models for Layer Segmentation
Nov 09, 2023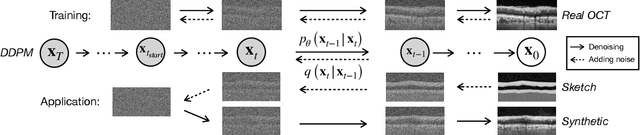
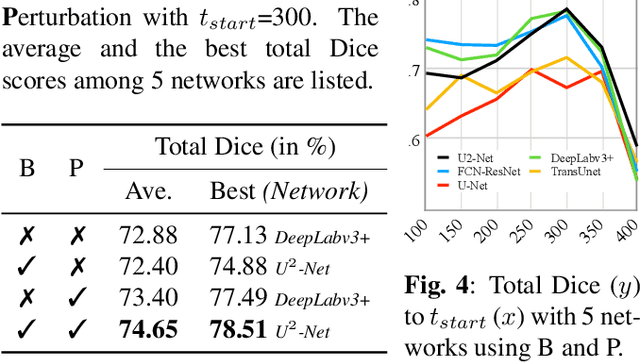

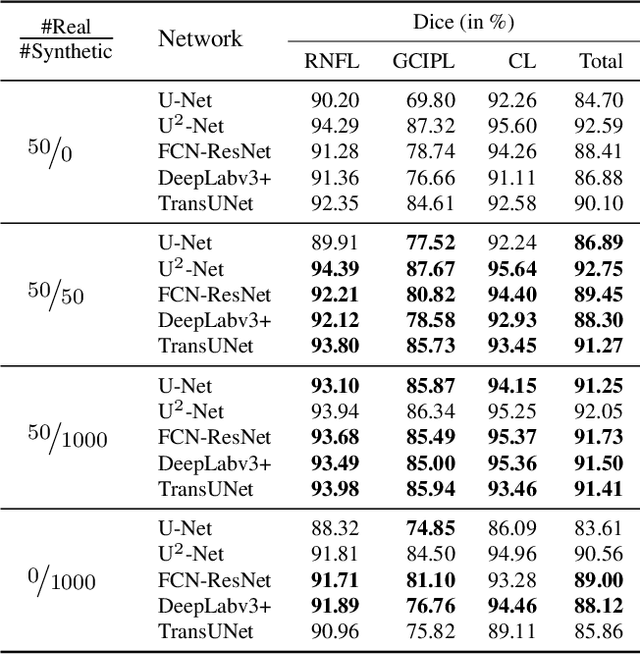
Modern biomedical image analysis using deep learning often encounters the challenge of limited annotated data. To overcome this issue, deep generative models can be employed to synthesize realistic biomedical images. In this regard, we propose an image synthesis method that utilizes denoising diffusion probabilistic models (DDPMs) to automatically generate retinal optical coherence tomography (OCT) images. By providing rough layer sketches, the trained DDPMs can generate realistic circumpapillary OCT images. We further find that more accurate pseudo labels can be obtained through knowledge adaptation, which greatly benefits the segmentation task. Through this, we observe a consistent improvement in layer segmentation accuracy, which is validated using various neural networks. Furthermore, we have discovered that a layer segmentation model trained solely with synthesized images can achieve comparable results to a model trained exclusively with real images. These findings demonstrate the promising potential of DDPMs in reducing the need for manual annotations of retinal OCT images.
A Deep Learning-based in silico Framework for Optimization on Retinal Prosthetic Stimulation
Feb 07, 2023We propose a neural network-based framework to optimize the perceptions simulated by the in silico retinal implant model pulse2percept. The overall pipeline consists of a trainable encoder, a pre-trained retinal implant model and a pre-trained evaluator. The encoder is a U-Net, which takes the original image and outputs the stimulus. The pre-trained retinal implant model is also a U-Net, which is trained to mimic the biomimetic perceptual model implemented in pulse2percept. The evaluator is a shallow VGG classifier, which is trained with original images. Based on 10,000 test images from the MNIST dataset, we show that the convolutional neural network-based encoder performs significantly better than the trivial downsampling approach, yielding a boost in the weighted F1-Score by 36.17% in the pre-trained classifier with 6x10 electrodes. With this fully neural network-based encoder, the quality of the downstream perceptions can be fine-tuned using gradient descent in an end-to-end fashion.
Multiscale Softmax Cross Entropy for Fovea Localization on Color Fundus Photography
Dec 08, 2021
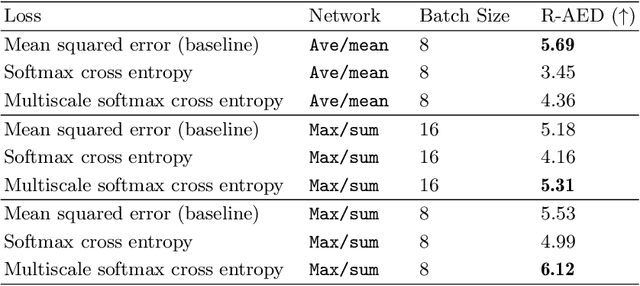
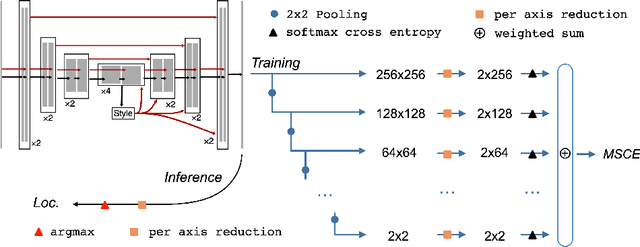
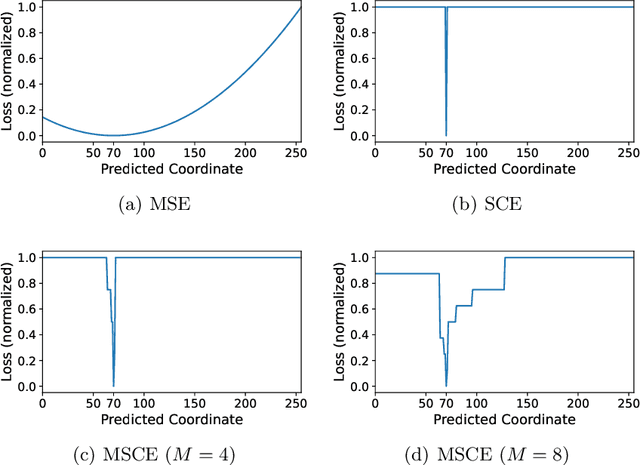
Fovea localization is one of the most popular tasks in ophthalmic medical image analysis, where the coordinates of the center point of the macula lutea, i.e. fovea centralis, should be calculated based on color fundus images. In this work, we treat the localization problem as a classification task, where the coordinates of the x- and y-axis are considered as the target classes. Moreover, the combination of the softmax activation function and the cross entropy loss function is modified to its multiscale variation to encourage the predicted coordinates to be located closely to the ground-truths. Based on color fundus photography images, we empirically show that the proposed multiscale softmax cross entropy yields better performance than the vanilla version and than the mean squared error loss with sigmoid activation, which provides a novel approach for coordinate regression.