 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye on the Target: Eye Tracking Meets Rodent Tracking
Mar 13, 2025Analyzing animal behavior from video recordings is crucial for scientific research, yet manual annotation remains labor-intensive and prone to subjectivity. Efficient segmentation methods are needed to automate this process while maintaining high accuracy. In this work, we propose a novel pipeline that utilizes eye-tracking data from Aria glasses to generate prompt points, which are then used to produce segmentation masks via a fast zero-shot segmentation model. Additionally, we apply post-processing to refine the prompts, leading to improved segmentation quality. Through our approach, we demonstrate that combining eye-tracking-based annotation with smart prompt refinement can enhance segmentation accuracy, achieving an improvement of 70.6% from 38.8 to 66.2 in the Jaccard Index for segmentation results in the rats dataset.
A Pragmatic Note on Evaluating Generative Models with Fréchet Inception Distance for Retinal Image Synthesis
Feb 26, 2025Fr\'echet Inception Distance (FID), computed with an ImageNet pretrained Inception-v3 network, is widely used as a state-of-the-art evaluation metric for generative models. It assumes that feature vectors from Inception-v3 follow a multivariate Gaussian distribution and calculates the 2-Wasserstein distance based on their means and covariances. While FID effectively measures how closely synthetic data match real data in many image synthesis tasks, the primary goal in biomedical generative models is often to enrich training datasets ideally with corresponding annotations. For this purpose, the gold standard for evaluating generative models is to incorporate synthetic data into downstream task training, such as classification and segmentation, to pragmatically assess its performance. In this paper, we examine cases from retinal imaging modalities, including color fundus photography and optical coherence tomography, where FID and its related metrics misalign with task-specific evaluation goals in classification and segmentation. We highlight the limitations of using various metrics, represented by FID and its variants, as evaluation criteria for these applications and address their potential caveats in broader biomedical imaging modalities and downstream tasks.
Visual Fixation-Based Retinal Prosthetic Simulation
Oct 15, 2024
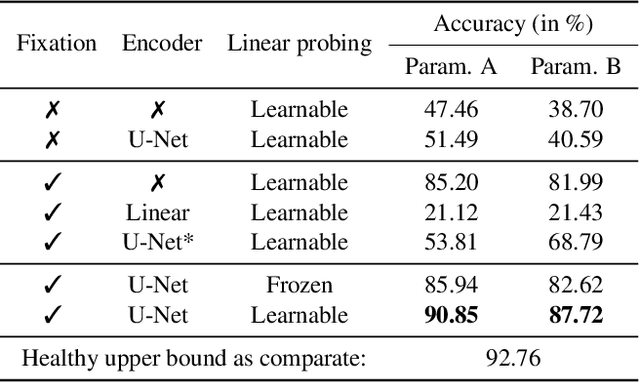
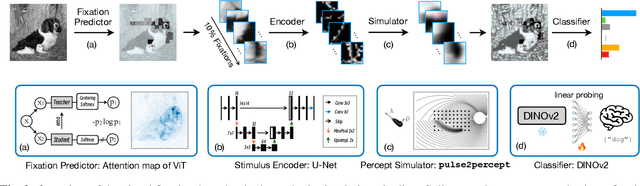
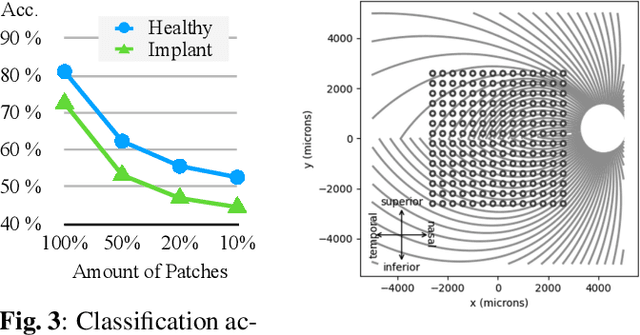
This study proposes a retinal prosthetic simulation framework driven by visual fixations, inspired by the saccade mechanism, and assesses performance improvements through end-to-end optimization in a classification task. Salient patches are predicted from input images using the self-attention map of a vision transformer to mimic visual fixations. These patches are then encoded by a trainable U-Net and simulated using the pulse2percept framework to predict visual percepts. By incorporating a learnable encoder, we aim to optimize the visual information transmitted to the retinal implant, addressing both the limited resolution of the electrode array and the distortion between the input stimuli and resulting phosphenes. The predicted percepts are evaluated using the self-supervised DINOv2 foundation model, with an optional learnable linear layer for classification accuracy. On a subset of the ImageNet validation set, the fixation-based framework achieves a classification accuracy of 87.72%, using computational parameters based on a real subject's physiological data, significantly outperforming the downsampling-based accuracy of 40.59% and approaching the healthy upper bound of 92.76%. Our approach shows promising potential for producing more semantically understandable percepts with the limited resolution available in retinal prosthetics.