 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting breast tumor proliferation from whole-slide images: the TUPAC16 challenge
Jul 22, 2018
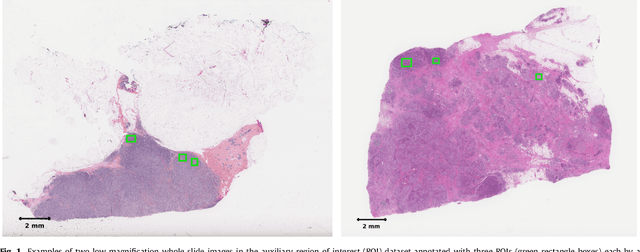
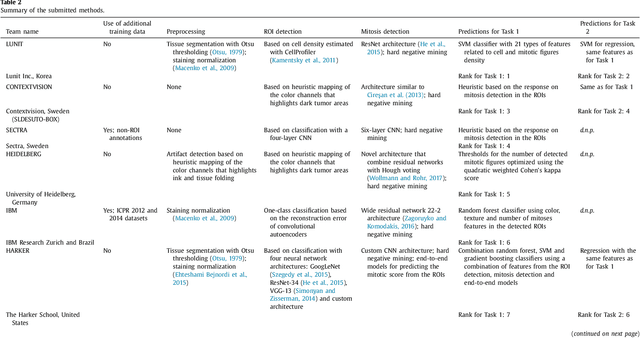
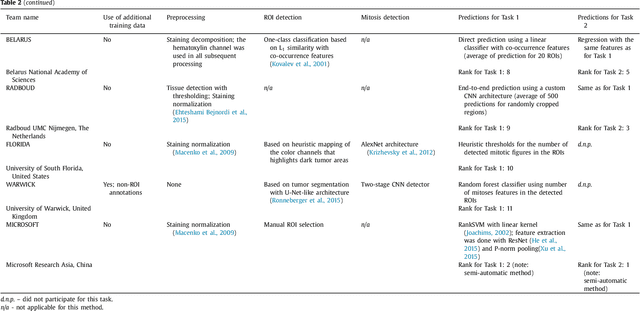
Tumor proliferation is an important biomarker indicative of the prognosis of breast cancer patients. Assessment of tumor proliferation in a clinical setting is highly subjective and labor-intensive task. Previous efforts to automate tumor proliferation assessment by image analysis only focused on mitosis detection in predefined tumor regions. However, in a real-world scenario, automatic mitosis detection should be performed in whole-slide images (WSIs) and an automatic method should be able to produce a tumor proliferation score given a WSI as input. To address this, we organized the TUmor Proliferation Assessment Challenge 2016 (TUPAC16) on prediction of tumor proliferation scores from WSIs. The challenge dataset consisted of 500 training and 321 testing breast cancer histopathology WSIs. In order to ensure fair and independent evaluation, only the ground truth for the training dataset was provided to the challenge participants. The first task of the challenge was to predict mitotic scores, i.e., to reproduce the manual method of assessing tumor proliferation by a pathologist. The second task was to predict the gene expression based PAM50 proliferation scores from the WSI. The best performing automatic method for the first task achieved a quadratic-weighted Cohen's kappa score of $\kappa$ = 0.567, 95% CI [0.464, 0.671] between the predicted scores and the ground truth. For the second task, the predictions of the top method had a Spearman's correlation coefficient of r = 0.617, 95% CI [0.581 0.651] with the ground truth. This was the first study that investigated tumor proliferation assessment from WSIs. The achieved results are promising given the difficulty of the tasks and weakly-labelled nature of the ground truth. However, further research is needed to improve the practical utility of image analysis methods for this task.
"Found in Translation": Predicting Outcomes of Complex Organic Chemistry Reactions using Neural Sequence-to-Sequence Models
Nov 15, 2017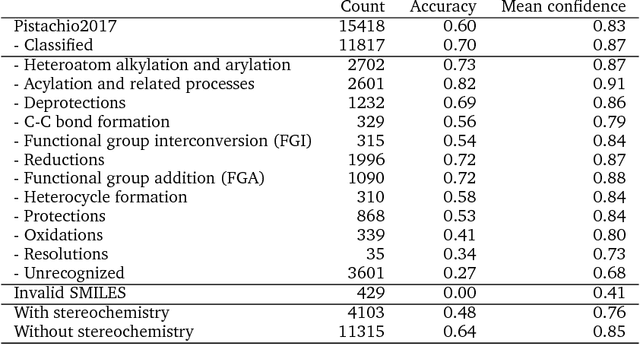
There is an intuitive analogy of an organic chemist's understanding of a compound and a language speaker's understanding of a word. Consequently, it is possible to introduce the basic concepts and analyze potential impacts of linguistic analysis to the world of organic chemistry. In this work, we cast the reaction prediction task as a translation problem by introducing a template-free sequence-to-sequence model, trained end-to-end and fully data-driven. We propose a novel way of tokenization, which is arbitrarily extensible with reaction information. With this approach, we demonstrate results superior to the state-of-the-art solution by a significant margin on the top-1 accuracy. Specifically, our approach achieves an accuracy of 80.1% without relying on auxiliary knowledge such as reaction templates. Also, 66.4% accuracy is reached on a larger and noisier dataset.