 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Found in Translation": Predicting Outcomes of Complex Organic Chemistry Reactions using Neural Sequence-to-Sequence Models
Nov 15, 2017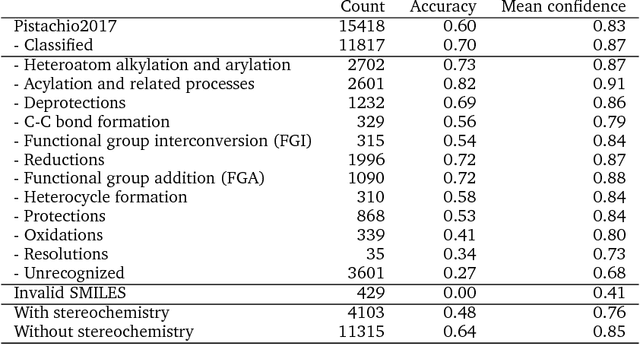
There is an intuitive analogy of an organic chemist's understanding of a compound and a language speaker's understanding of a word. Consequently, it is possible to introduce the basic concepts and analyze potential impacts of linguistic analysis to the world of organic chemistry. In this work, we cast the reaction prediction task as a translation problem by introducing a template-free sequence-to-sequence model, trained end-to-end and fully data-driven. We propose a novel way of tokenization, which is arbitrarily extensible with reaction information. With this approach, we demonstrate results superior to the state-of-the-art solution by a significant margin on the top-1 accuracy. Specifically, our approach achieves an accuracy of 80.1% without relying on auxiliary knowledge such as reaction templates. Also, 66.4% accuracy is reached on a larger and noisier dataset.