 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreastGPT: A Multimodal Large Language Model for the Full Spectrum of Breast Cancer Clinical Routine
Jun 03, 2026Breast cancer remains a leading cause of cancer-related mortality among women. Its clinical management requires multimodal reasoning across a clinical workflow that spans \textit{screening}, \textit{diagnosis} and \textit{treatment planning}, where each stage involves distinct imaging modalities, task objectives, and reasoning patterns. However, constrained by data scarcity and model versatility, existing medical MLLMs are typically evaluated on isolated modalities or narrow task families, limiting their ability to support workflow-level clinical reasoning. In this work, we first introduce \textbf{BreastStage}, a workflow-aligned breast imaging instruction corpus comprising 1.86M instruction-following pairs curated from 17 sub-datasets across 5 imaging modalities and 136 task templates. Its held-out split, \textbf{BreastStage-Bench}, provides a comprehensive benchmark for evaluating multimodal reasoning across the breast cancer care continuum. Building on this corpus, we propose \textbf{BreastGPT}, a unified MLLM equipped with a dual-branch visual encoder and concept-preserving token compression to bridge the scale gap between standard radiology and gigapixel pathology. On BreastStage-Bench, BreastGPT achieves 75.66\% closed-ended accuracy and 89.92\% open-ended score, outperforming both general-purpose and medical-specific MLLMs across clinical stages and task formats. These results suggest that workflow-aligned data and cross-scale visual modeling are critical for clinically grounded medical MLLMs. All data, code, and model checkpoints are released at https://yangyy-liu.github.io/BreastGPT.io.
Non-Contrast CT Esophageal Varices Grading through Clinical Prior-Enhanced Multi-Organ Analysis
Dec 22, 2025Esophageal varices (EV) represent a critical complication of portal hypertension, affecting approximately 60% of cirrhosis patients with a significant bleeding risk of ~30%. While traditionally diagnosed through invasive endoscopy, non-contrast computed tomography (NCCT) presents a potential non-invasive alternative that has yet to be fully utilized in clinical practice. We present Multi-Organ-COhesion Network++ (MOON++), a novel multimodal framework that enhances EV assessment through comprehensive analysis of NCCT scans. Inspired by clinical evidence correlating organ volumetric relationships with liver disease severity, MOON++ synthesizes imaging characteristics of the esophagus, liver, and spleen through multimodal learning. We evaluated our approach using 1,631 patients, those with endoscopically confirmed EV were classified into four severity grades. Validation in 239 patient cases and independent testing in 289 cases demonstrate superior performance compared to conventional single organ methods, achieving an AUC of 0.894 versus 0.803 for the severe grade EV classification (G3 versus <G3) and 0.921 versus 0.793 for the differentiation of moderate to severe grades (>=G2 versus <G2). We conducted a reader study involving experienced radiologists to further validate the performance of MOON++. To our knowledge, MOON++ represents the first comprehensive multi-organ NCCT analysis framework incorporating clinical knowledge priors for EV assessment, potentially offering a promising non-invasive diagnostic alternative.
Anatomy-Aware Low-Dose CT Denoising via Pretrained Vision Models and Semantic-Guided Contrastive Learning
Aug 11, 2025To reduce radiation exposure and improve the diagnostic efficacy of low-dose computed tomography (LDCT), numerous deep learning-based denoising methods have been developed to mitigate noise and artifacts. However, most of these approaches ignore the anatomical semantics of human tissues, which may potentially result in suboptimal denoising outcomes. To address this problem, we propose ALDEN, an anatomy-aware LDCT denoising method that integrates semantic features of pretrained vision models (PVMs) with adversarial and contrastive learning. Specifically, we introduce an anatomy-aware discriminator that dynamically fuses hierarchical semantic features from reference normal-dose CT (NDCT) via cross-attention mechanisms, enabling tissue-specific realism evaluation in the discriminator. In addition, we propose a semantic-guided contrastive learning module that enforces anatomical consistency by contrasting PVM-derived features from LDCT, denoised CT and NDCT, preserving tissue-specific patterns through positive pairs and suppressing artifacts via dual negative pairs. Extensive experiments conducted on two LDCT denoising datasets reveal that ALDEN achieves the state-of-the-art performance, offering superior anatomy preservation and substantially reducing over-smoothing issue of previous work. Further validation on a downstream multi-organ segmentation task (encompassing 117 anatomical structures) affirms the model's ability to maintain anatomical awareness.
Joint Gaze-Location and Gaze-Object Detection
Aug 26, 2023



This paper proposes an efficient and effective method for joint gaze location detection (GL-D) and gaze object detection (GO-D), \emph{i.e.}, gaze following detection. Current approaches frame GL-D and GO-D as two separate tasks, employing a multi-stage framework where human head crops must first be detected and then be fed into a subsequent GL-D sub-network, which is further followed by an additional object detector for GO-D. In contrast, we reframe the gaze following detection task as detecting human head locations and their gaze followings simultaneously, aiming at jointly detect human gaze location and gaze object in a unified and single-stage pipeline. To this end, we propose GTR, short for \underline{G}aze following detection \underline{TR}ansformer, streamlining the gaze following detection pipeline by eliminating all additional components, leading to the first unified paradigm that unites GL-D and GO-D in a fully end-to-end manner. GTR enables an iterative interaction between holistic semantics and human head features through a hierarchical structure, inferring the relations of salient objects and human gaze from the global image context and resulting in an impressive accuracy. Concretely, GTR achieves a 12.1 mAP gain ($\mathbf{25.1}\%$) on GazeFollowing and a 18.2 mAP gain ($\mathbf{43.3\%}$) on VideoAttentionTarget for GL-D, as well as a 19 mAP improvement ($\mathbf{45.2\%}$) on GOO-Real for GO-D. Meanwhile, unlike existing systems detecting gaze following sequentially due to the need for a human head as input, GTR has the flexibility to comprehend any number of people's gaze followings simultaneously, resulting in high efficiency. Specifically, GTR introduces over a $\times 9$ improvement in FPS and the relative gap becomes more pronounced as the human number grows.
Agglomerative Transformer for Human-Object Interaction Detection
Aug 16, 2023



We propose an agglomerative Transformer (AGER) that enables Transformer-based human-object interaction (HOI) detectors to flexibly exploit extra instance-level cues in a single-stage and end-to-end manner for the first time. AGER acquires instance tokens by dynamically clustering patch tokens and aligning cluster centers to instances with textual guidance, thus enjoying two benefits: 1) Integrality: each instance token is encouraged to contain all discriminative feature regions of an instance, which demonstrates a significant improvement in the extraction of different instance-level cues and subsequently leads to a new state-of-the-art performance of HOI detection with 36.75 mAP on HICO-Det. 2) Efficiency: the dynamical clustering mechanism allows AGER to generate instance tokens jointly with the feature learning of the Transformer encoder, eliminating the need of an additional object detector or instance decoder in prior methods, thus allowing the extraction of desirable extra cues for HOI detection in a single-stage and end-to-end pipeline. Concretely, AGER reduces GFLOPs by 8.5% and improves FPS by 36%, even compared to a vanilla DETR-like pipeline without extra cue extraction.
Masked Autoencoders as Image Processors
Mar 30, 2023Transformers have shown significant effectiveness for various vision tasks including both high-level vision and low-level vision. Recently, masked autoencoders (MAE) for feature pre-training have further unleashed the potential of Transformers, leading to state-of-the-art performances on various high-level vision tasks. However, the significance of MAE pre-training on low-level vision tasks has not been sufficiently explored. In this paper, we show that masked autoencoders are also scalable self-supervised learners for image processing tasks. We first present an efficient Transformer model considering both channel attention and shifted-window-based self-attention termed CSformer. Then we develop an effective MAE architecture for image processing (MAEIP) tasks. Extensive experimental results show that with the help of MAEIP pre-training, our proposed CSformer achieves state-of-the-art performance on various image processing tasks, including Gaussian denoising, real image denoising, single-image motion deblurring, defocus deblurring, and image deraining.
Video-based Human-Object Interaction Detection from Tubelet Tokens
Jun 04, 2022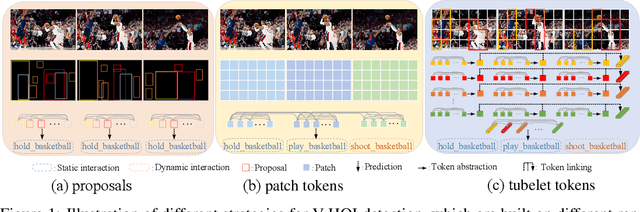

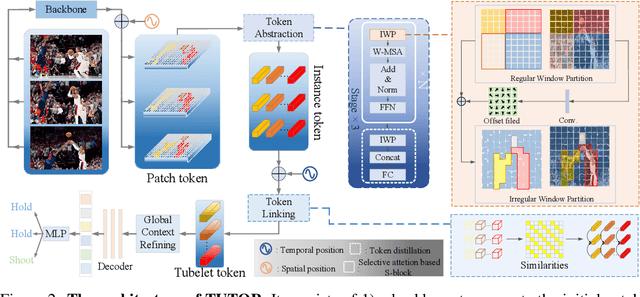
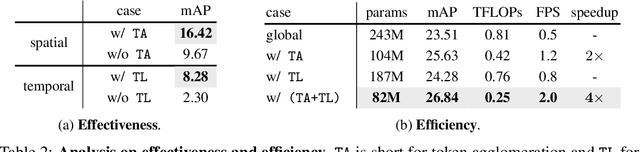
We present a novel vision Transformer, named TUTOR, which is able to learn tubelet tokens, served as highly-abstracted spatiotemporal representations, for video-based human-object interaction (V-HOI) detection. The tubelet tokens structurize videos by agglomerating and linking semantically-related patch tokens along spatial and temporal domains, which enjoy two benefits: 1) Compactness: each tubelet token is learned by a selective attention mechanism to reduce redundant spatial dependencies from others; 2) Expressiveness: each tubelet token is enabled to align with a semantic instance, i.e., an object or a human, across frames, thanks to agglomeration and linking. The effectiveness and efficiency of TUTOR are verified by extensive experiments. Results shows our method outperforms existing works by large margins, with a relative mAP gain of $16.14\%$ on VidHOI and a 2 points gain on CAD-120 as well as a $4 \times$ speedup.
Saliency in Augmented Reality
Apr 18, 2022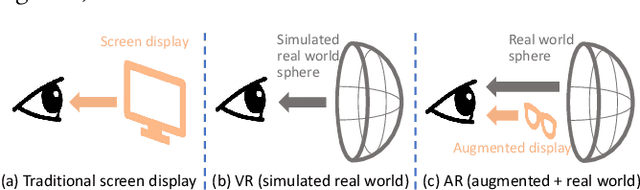
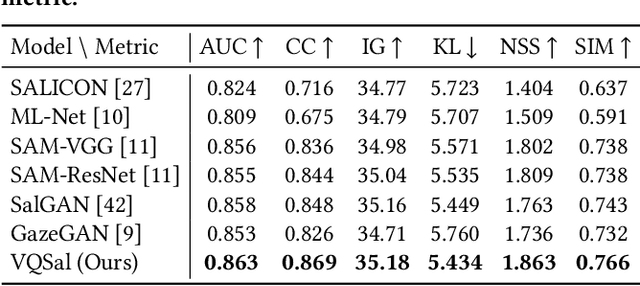

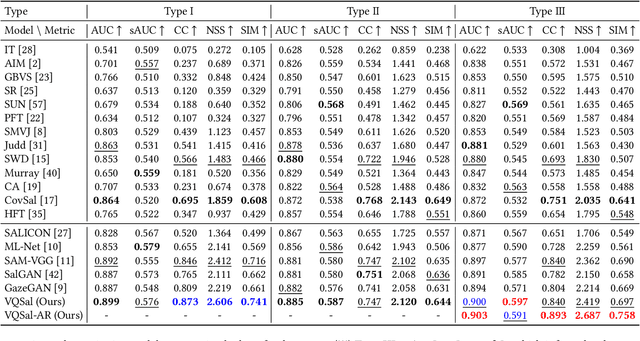
With the rapid development of multimedia technology, Augmented Reality (AR) has become a promising next-generation mobile platform. The primary theory underlying AR is human visual confusion, which allows users to perceive the real-world scenes and augmented contents (virtual-world scenes) simultaneously by superimposing them together. To achieve good Quality of Experience (QoE), it is important to understand the interaction between two scenarios, and harmoniously display AR contents. However, studies on how this superimposition will influence the human visual attention are lacking. Therefore, in this paper, we mainly analyze the interaction effect between background (BG) scenes and AR contents, and study the saliency prediction problem in AR. Specifically, we first construct a Saliency in AR Dataset (SARD), which contains 450 BG images, 450 AR images, as well as 1350 superimposed images generated by superimposing BG and AR images in pair with three mixing levels. A large-scale eye-tracking experiment among 60 subjects is conducted to collect eye movement data. To better predict the saliency in AR, we propose a vector quantized saliency prediction method and generalize it for AR saliency prediction. For comparison, three benchmark methods are proposed and evaluated together with our proposed method on our SARD. Experimental results demonstrate the superiority of our proposed method on both of the common saliency prediction problem and the AR saliency prediction problem over benchmark methods. Our data collection methodology, dataset, benchmark methods, and proposed saliency models will be publicly available to facilitate future research.
End-to-End Human-Gaze-Target Detection with Transformers
Mar 24, 2022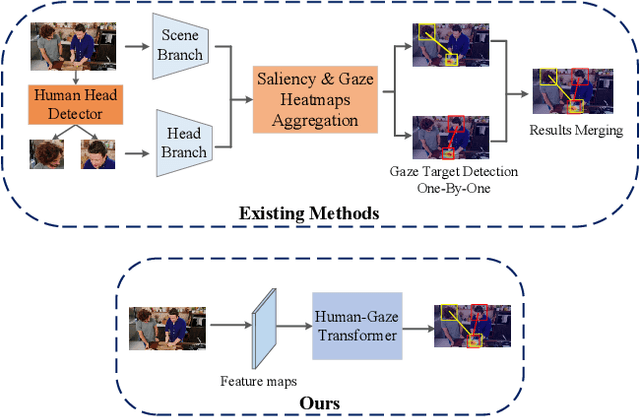
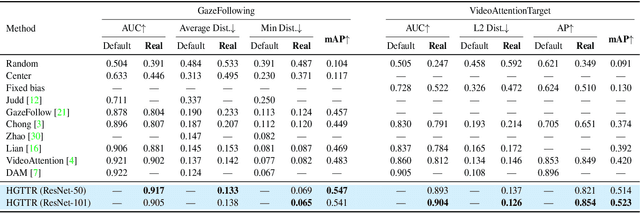
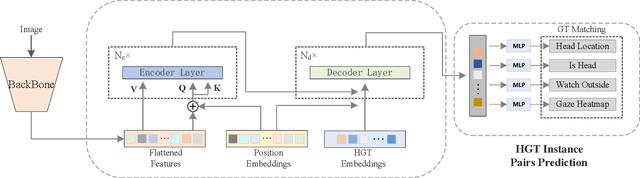
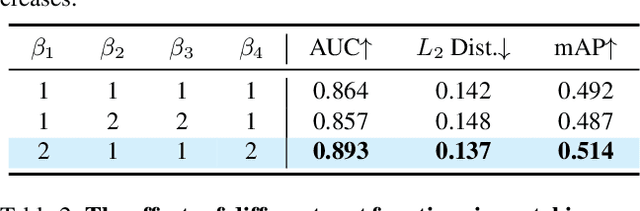
In this paper, we propose an effective and efficient method for Human-Gaze-Target (HGT) detection, i.e., gaze following. Current approaches decouple the HGT detection task into separate branches of salient object detection and human gaze prediction, employing a two-stage framework where human head locations must first be detected and then be fed into the next gaze target prediction sub-network. In contrast, we redefine the HGT detection task as detecting human head locations and their gaze targets, simultaneously. By this way, our method, named Human-Gaze-Target detection TRansformer or HGTTR, streamlines the HGT detection pipeline by eliminating all other additional components. HGTTR reasons about the relations of salient objects and human gaze from the global image context. Moreover, unlike existing two-stage methods that require human head locations as input and can predict only one human's gaze target at a time, HGTTR can directly predict the locations of all people and their gaze targets at one time in an end-to-end manner. The effectiveness and robustness of our proposed method are verified with extensive experiments on the two standard benchmark datasets, GazeFollowing and VideoAttentionTarget. Without bells and whistles, HGTTR outperforms existing state-of-the-art methods by large margins (6.4 mAP gain on GazeFollowing and 10.3 mAP gain on VideoAttentionTarget) with a much simpler architecture.
Iwin: Human-Object Interaction Detection via Transformer with Irregular Windows
Mar 20, 2022
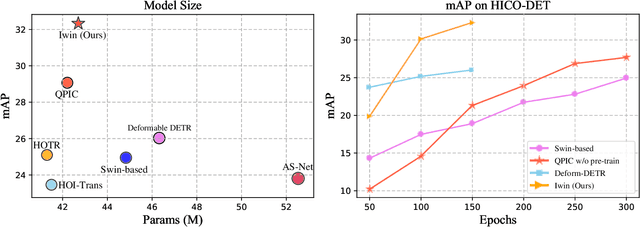
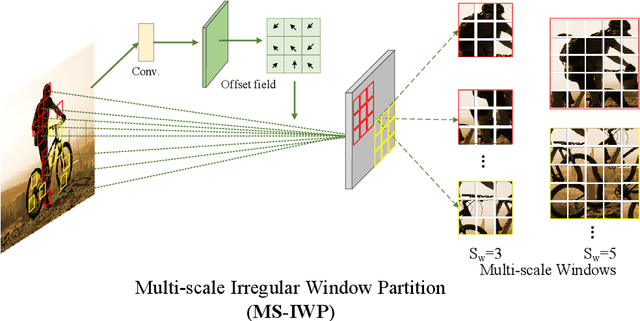
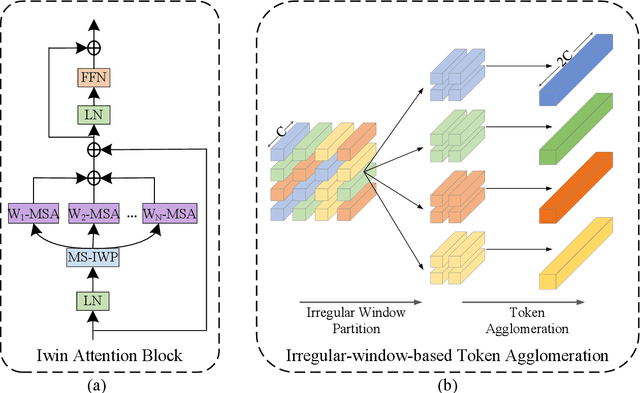
This paper presents a new vision Transformer, named Iwin Transformer, which is specifically designed for human-object interaction (HOI) detection, a detailed scene understanding task involving a sequential process of human/object detection and interaction recognition. Iwin Transformer is a hierarchical Transformer which progressively performs token representation learning and token agglomeration within irregular windows. The irregular windows, achieved by augmenting regular grid locations with learned offsets, 1) eliminate redundancy in token representation learning, which leads to efficient human/object detection, and 2) enable the agglomerated tokens to align with humans/objects with different shapes, which facilitates the acquisition of highly-abstracted visual semantics for interaction recognition. The effectiveness and efficiency of Iwin Transformer are verified on the two standard HOI detection benchmark datasets, HICO-DET and V-COCO. Results show our method outperforms existing Transformers-based methods by large margins (3.7 mAP gain on HICO-DET and 2.0 mAP gain on V-COCO) with fewer training epochs ($0.5 \times$).