 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIwin: Human-Object Interaction Detection via Transformer with Irregular Windows
Paper and Code
Mar 20, 2022
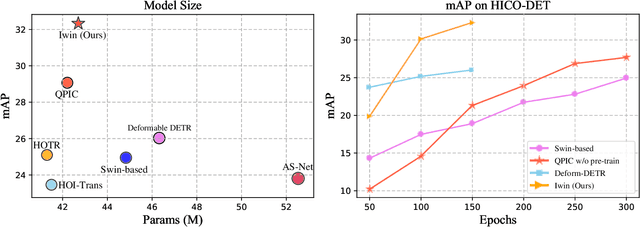
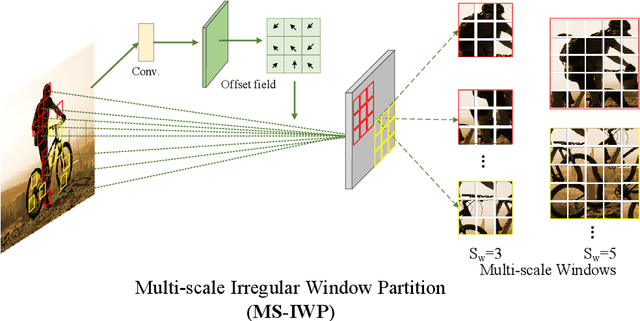
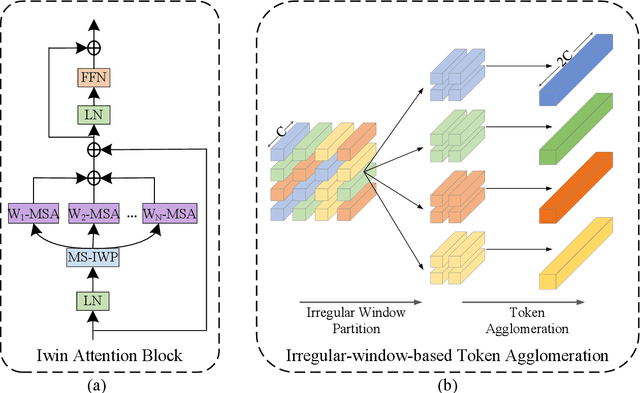
This paper presents a new vision Transformer, named Iwin Transformer, which is specifically designed for human-object interaction (HOI) detection, a detailed scene understanding task involving a sequential process of human/object detection and interaction recognition. Iwin Transformer is a hierarchical Transformer which progressively performs token representation learning and token agglomeration within irregular windows. The irregular windows, achieved by augmenting regular grid locations with learned offsets, 1) eliminate redundancy in token representation learning, which leads to efficient human/object detection, and 2) enable the agglomerated tokens to align with humans/objects with different shapes, which facilitates the acquisition of highly-abstracted visual semantics for interaction recognition. The effectiveness and efficiency of Iwin Transformer are verified on the two standard HOI detection benchmark datasets, HICO-DET and V-COCO. Results show our method outperforms existing Transformers-based methods by large margins (3.7 mAP gain on HICO-DET and 2.0 mAP gain on V-COCO) with fewer training epochs ($0.5 \times$).