 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Rewards for Reinforcement Learning from Symbolic Behaviour Descriptions of Bipedal Walking
Dec 16, 2023Generating physical movement behaviours from their symbolic description is a long-standing challenge in artificial intelligence (AI) and robotics, requiring insights into numerical optimization methods as well as into formalizations from symbolic AI and reasoning. In this paper, a novel approach to finding a reward function from a symbolic description is proposed. The intended system behaviour is modelled as a hybrid automaton, which reduces the system state space to allow more efficient reinforcement learning. The approach is applied to bipedal walking, by modelling the walking robot as a hybrid automaton over state space orthants, and used with the compass walker to derive a reward that incentivizes following the hybrid automaton cycle. As a result, training times of reinforcement learning controllers are reduced while final walking speed is increased. The approach can serve as a blueprint how to generate reward functions from symbolic AI and reasoning.
End-to-End Reinforcement Learning for Torque Based Variable Height Hopping
Jul 31, 2023Legged locomotion is arguably the most suited and versatile mode to deal with natural or unstructured terrains. Intensive research into dynamic walking and running controllers has recently yielded great advances, both in the optimal control and reinforcement learning (RL) literature. Hopping is a challenging dynamic task involving a flight phase and has the potential to increase the traversability of legged robots. Model based control for hopping typically relies on accurate detection of different jump phases, such as lift-off or touch down, and using different controllers for each phase. In this paper, we present a end-to-end RL based torque controller that learns to implicitly detect the relevant jump phases, removing the need to provide manual heuristics for state detection. We also extend a method for simulation to reality transfer of the learned controller to contact rich dynamic tasks, resulting in successful deployment on the robot after training without parameter tuning.
AcroMonk: A Minimalist Underactuated Brachiating Robot
May 15, 2023Brachiation is a dynamic, coordinated swinging maneuver of body and arms used by monkeys and apes to move between branches. As a unique underactuated mode of locomotion, it is interesting to study from a robotics perspective since it can broaden the deployment scenarios for humanoids and animaloids. While several brachiating robots of varying complexity have been proposed in the past, this paper presents the simplest possible prototype of a brachiation robot, using only a single actuator and unactuated grippers. The novel passive gripper design allows it to snap on and release from monkey bars, while guaranteeing well defined start and end poses of the swing. The brachiation behavior is realized in three different ways, using trajectory optimization via direct collocation and stabilization by a model-based time-varying linear quadratic regulator (TVLQR) or model-free proportional derivative (PD) control, as well as by a reinforcement learning (RL) based control policy. The three control schemes are compared in terms of robustness to disturbances, mass uncertainty, and energy consumption. The system design and controllers have been open-sourced. Due to its minimal and open design, the system can serve as a canonical underactuated platform for education and research.
* The open-source implementation is available at https://github.com/dfki-ric-underactuated-lab/acromonk and a video demonstration of the experiments can be accessed at https://youtu.be/FIcDNtJo9Jc}
Quantifying the Effect of Feedback Frequency in Interactive Reinforcement Learning for Robotic Tasks
Jul 20, 2022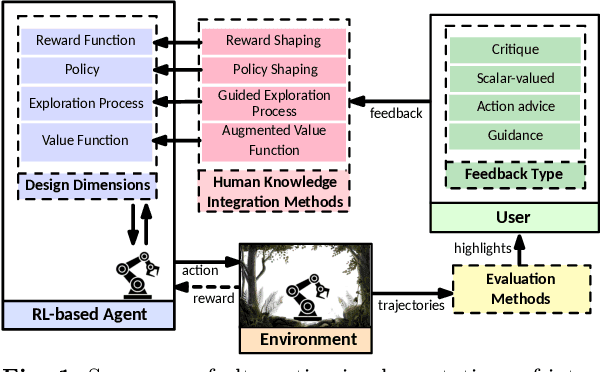

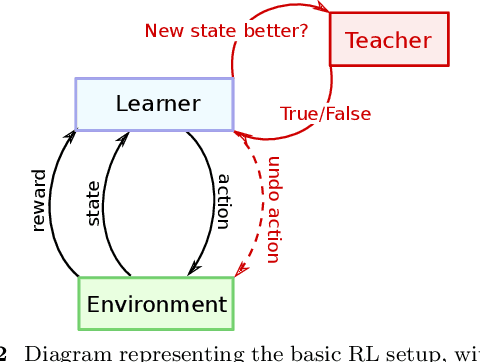
Reinforcement learning (RL) has become widely adopted in robot control. Despite many successes, one major persisting problem can be very low data efficiency. One solution is interactive feedback, which has been shown to speed up RL considerably. As a result, there is an abundance of different strategies, which are, however, primarily tested on discrete grid-world and small scale optimal control scenarios. In the literature, there is no consensus about which feedback frequency is optimal or at which time the feedback is most beneficial. To resolve these discrepancies we isolate and quantify the effect of feedback frequency in robotic tasks with continuous state and action spaces. The experiments encompass inverse kinematics learning for robotic manipulator arms of different complexity. We show that seemingly contradictory reported phenomena occur at different complexity levels. Furthermore, our results suggest that no single ideal feedback frequency exists. Rather that feedback frequency should be changed as the agent's proficiency in the task increases.
Feature Disentanglement of Robot Trajectories
Dec 06, 2021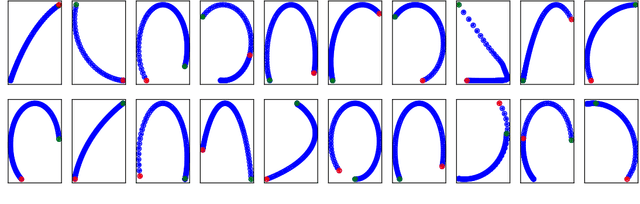

Modeling trajectories generated by robot joints is complex and required for high level activities like trajectory generation, clustering, and classification. Disentagled representation learning promises advances in unsupervised learning, but they have not been evaluated in robot-generated trajectories. In this paper we evaluate three disentangling VAEs ($\beta$-VAE, Decorr VAE, and a new $\beta$-Decorr VAE) on a dataset of 1M robot trajectories generated from a 3 DoF robot arm. We find that the decorrelation-based formulations perform the best in terms of disentangling metrics, trajectory quality, and correlation with ground truth latent features. We expect that these results increase the use of unsupervised learning in robot control.
A Development Cycle for Automated Self-Exploration of Robot Behaviors
Jul 29, 2020



In this paper we introduce Q-Rock, a development cycle for the automated self-exploration and qualification of robotic behaviors. With Q-Rock, we suggest a novel, integrative approach to automate robot development processes. Q-Rock combines several machine learning and reasoning techniques to deal with the increasing complexity in the design of robotic systems. The Q-Rock development cycle consists of three complementary processes: (1) automated exploration of capabilities that a given robotic hardware provides, (2) classification and semantic annotation of these capabilities to generate more complex behaviors, and (3) mapping between application requirements and available behaviors. These processes are based on a graph-based representation of a robot's structure, including hardware and software components. A graph-database serves as central, scalable knowledge base to enable collaboration with robot designers including mechanical and electrical engineers, software developers and machine learning experts. In this paper we formalize Q-Rock's integrative development cycle and highlight its benefits with a proof-of-concept implementation and a use case demonstration.
Combinatorics of a Discrete Trajectory Space for Robot Motion Planning
May 25, 2020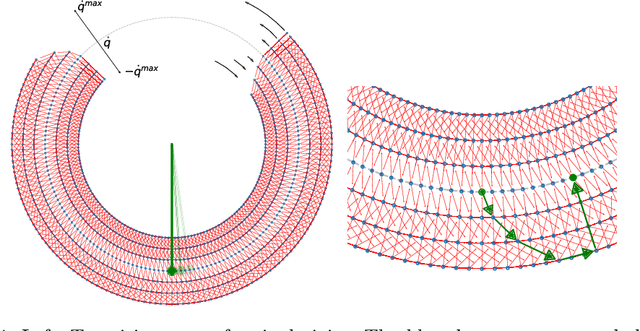
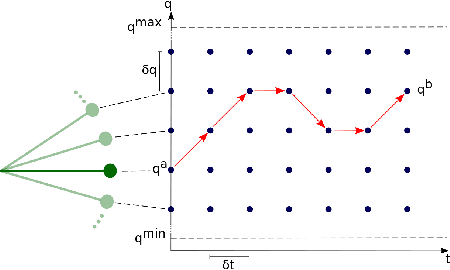
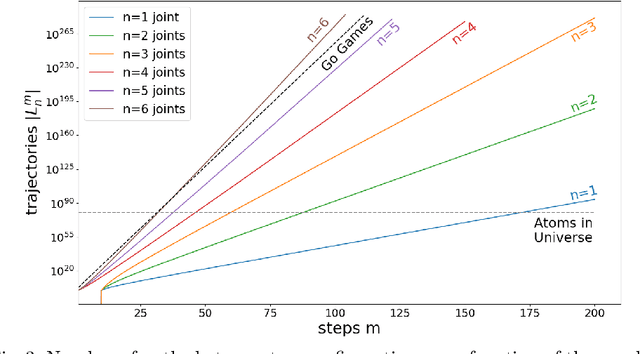
Motion planning is a difficult problem in robot control. The complexity of the problem is directly related to the dimension of the robot's configuration space. While in many theoretical calculations and practical applications the configuration space is modeled as a continuous space, we present a discrete robot model based on the fundamental hardware specifications of a robot. Using lattice path methods, we provide estimates for the complexity of motion planning by counting the number of possible trajectories in a discrete robot configuration space.