 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Robustness Out of the Box: Compositional Representations Naturally Defend Against Black-Box Patch Attacks
Dec 01, 2020



Patch-based adversarial attacks introduce a perceptible but localized change to the input that induces misclassification. While progress has been made in defending against imperceptible attacks, it remains unclear how patch-based attacks can be resisted. In this work, we study two different approaches for defending against black-box patch attacks. First, we show that adversarial training, which is successful against imperceptible attacks, has limited effectiveness against state-of-the-art location-optimized patch attacks. Second, we find that compositional deep networks, which have part-based representations that lead to innate robustness to natural occlusion, are robust to patch attacks on PASCAL3D+ and the German Traffic Sign Recognition Benchmark, without adversarial training. Moreover, the robustness of compositional models outperforms that of adversarially trained standard models by a large margin. However, on GTSRB, we observe that they have problems discriminating between similar traffic signs with fine-grained differences. We overcome this limitation by introducing part-based finetuning, which improves fine-grained recognition. By leveraging compositional representations, this is the first work that defends against black-box patch attacks without expensive adversarial training. This defense is more robust than adversarial training and more interpretable because it can locate and ignore adversarial patches.
Adversarial Examples for Edge Detection: They Exist, and They Transfer
Jun 02, 2019

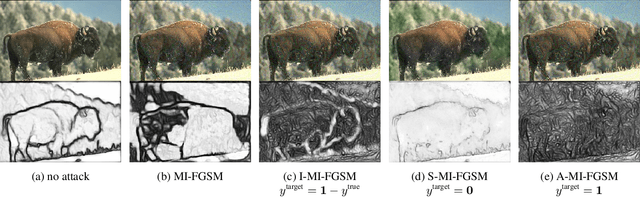

Convolutional neural networks have recently advanced the state of the art in many tasks including edge and object boundary detection. However, in this paper, we demonstrate that these edge detectors inherit a troubling property of neural networks: they can be fooled by adversarial examples. We show that adding small perturbations to an image causes HED, a CNN-based edge detection model, to fail to locate edges, to detect nonexistent edges, and even to hallucinate arbitrary configurations of edges. More surprisingly, we find that these adversarial examples transfer to other CNN-based vision models. In particular, attacks on edge detection result in significant drops in accuracy in models trained to perform unrelated, high-level tasks like image classification and semantic segmentation. Our code will be made public.